
使用 ChatGPT 的文本数据增强,通过生成语义多样化且语言自然的样本,改善了NLP任务中的少样本学习。
标题:ChatAug: Leveraging ChatGPT for Text Data Augmentation
作者:Haixing Dai, Zhengliang Liu, Wenxiong Liao, Xiaoke Huang, Zihao Wu, Lin Zhao, Wei Liu, Ninghao Liu, Sheng Li, Dajiang Zhu, Hongmin Cai, Quanzheng Li, Dinggang Shen, Tianming Liu, and Xiang Li
[University of Georgia & South China University of Technology]
论文地址:https://arxiv.org/abs/2302.13007
-
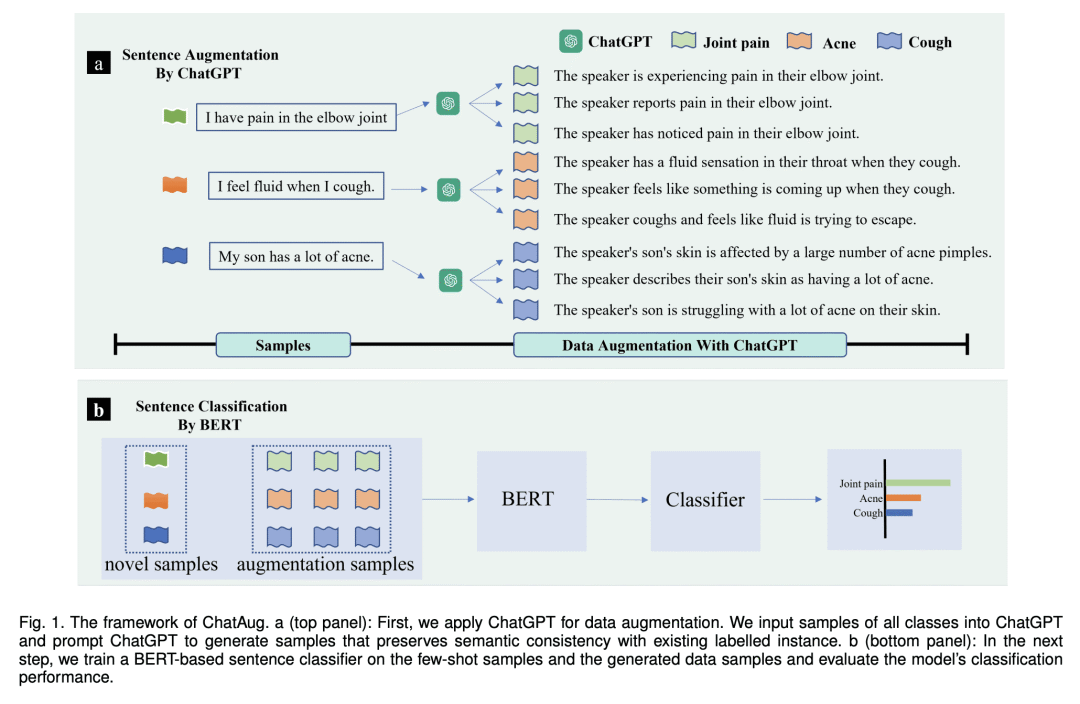
基于 ChatGPT 的文本数据增强(ChatAug)是一个很有前途的策略,可以克服在少样本学习场景中样本量有限的挑战; -
ChatAug 将训练样本中每个句子重新表述为多个概念相似但语义不同的样本,增强了数据的一致性和鲁棒性; -
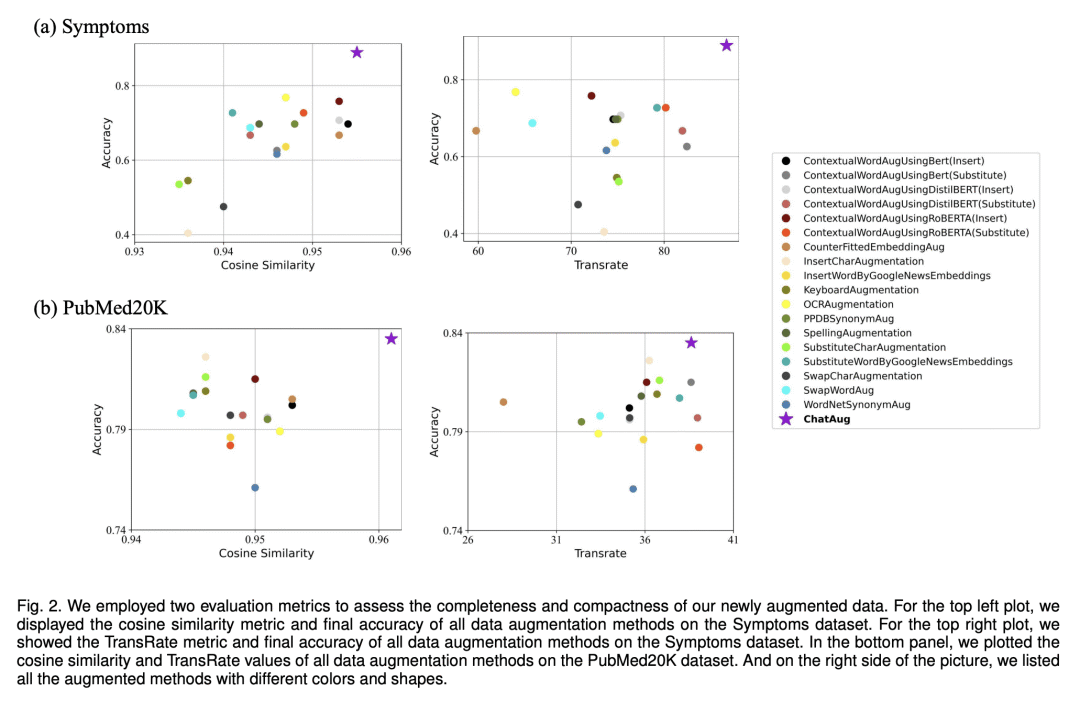
ChatAug 在测试精度和增强样本分布方面优于最先进的文本数据增强方法; -
ChatGPT 在计算机视觉域特定摘要和少样本学习方面具有潜力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢