

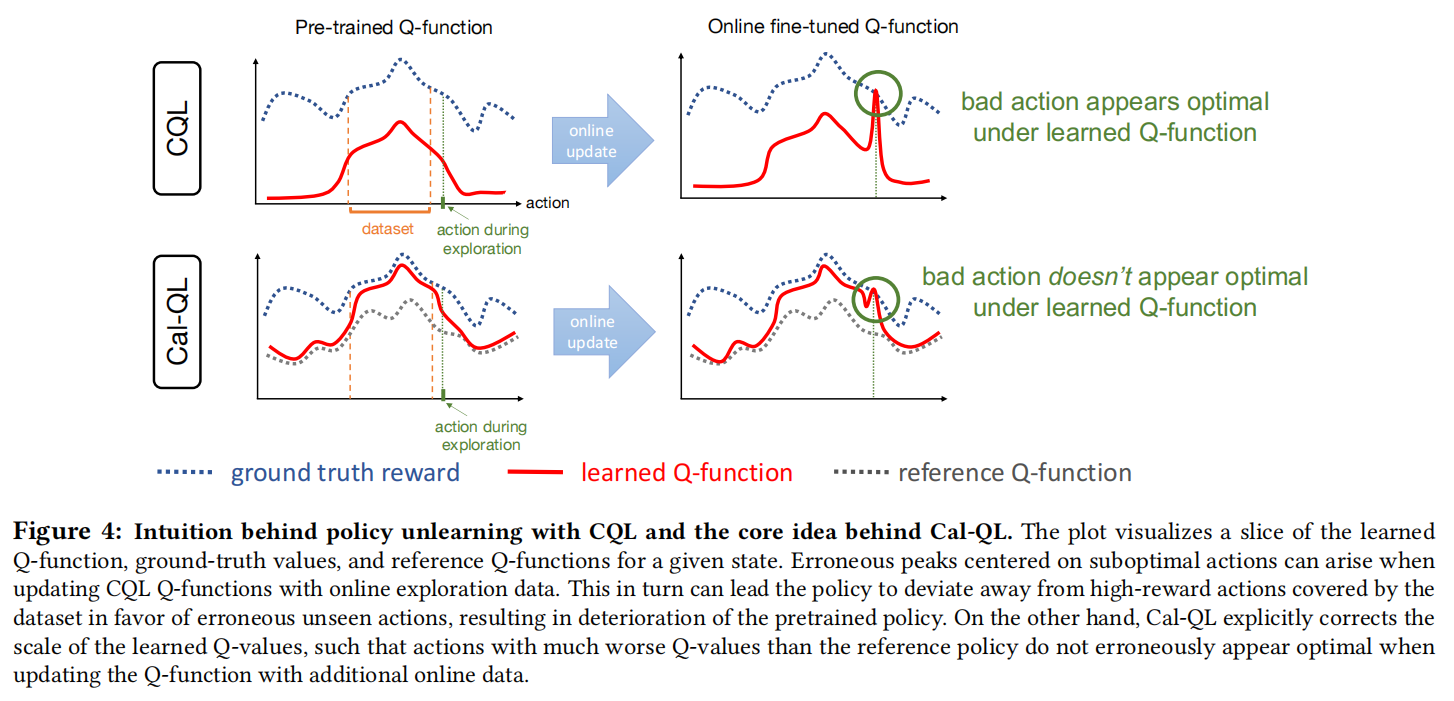
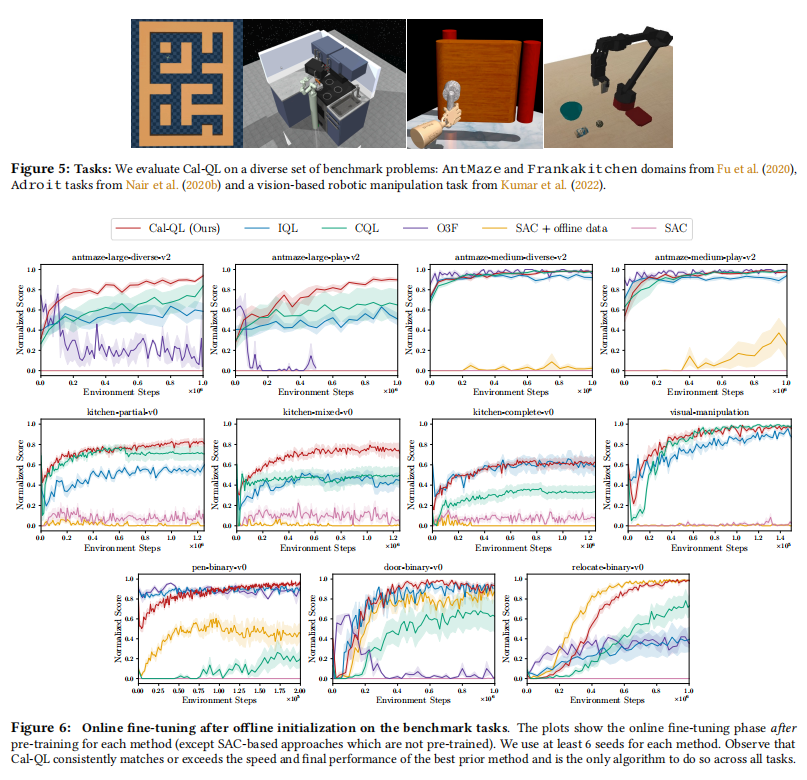
在线强化学习(RL)一个常见的做法是从现有数据集获得策略初始化,并在有限的主动在线交互下进行调整。然而,现有的在线RL方法往往表现出较差的在线微调性能。另一方面,在线RL方法需要通过在线交互进行学习,难以有效处理在线数据,这使得它们在探索具有挑战性或需要预训练的环境中非常缓慢。在本文中,作者设计了一种从所有数据中学习有效初始化的方法(Cal-QL),同时也实现了快速在线调优能力。Cal-QL通过学习保守值函数初始化来实现这一点,该方法低估了从所有数据中学习到的策略的值,同时确保学习到的q值在一个合理的尺度上。作者将这个属性称为校准,并将其正式定义为提供了学习策略的真实值函数的下界和其他一些(次优)参考策略的值的上界。
论文地址:https://openreview.net/forum?id=PhCWNmatOX

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢