
《Large language models are having their Stable Diffusion moment》
部分为机器翻译,查看原文请点击这里
LLaMA 项目地址:https://github.com/facebookresearch/llama
LLaMA 论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
大型语言模型正在有其稳定的扩散时刻
早在2022年8月, Stable Diffusion 图像生成模型的公开发布是一个关键时刻。我当时写道,Stable Diffusion 是一件大事。
人们现在可以在自己的硬件上从文本中生成图像!更重要的是,开发人员可以搞乱正在发生的事情。
由此产生的创新爆炸式增长至今仍在继续。最近,就其能力而言,ControlNet似乎领先于Midjourney和DALL-E的 Stable Diffusion 。对我来说,8月份的稳定传播时刻引发了对生成性人工智能的整个新兴趣浪潮——然后,由于11月底ChatGPT的发布,生成人工智能被推向了过度驱动。
对于大型语言模型来说,这种稳定的扩散时刻正在再次发生——ChatGPT本身背后的技术。今天早上,我第一次在自己的个人笔记本电脑上运行GPT-3类语言模型!人工智能的东西已经很奇怪了。它即将变得更奇怪。
LLaMA
有点令人惊讶的是,像GPT-3这样的语言模型,像ChatGPT这样的电动工具比图像生成模型更大,构建和操作成本更高。
这些模型中最好的主要由OpenAI等私人组织构建,并受到严格控制——可以通过其API和Web界面访问,但不会发布给任何人在自己的机器上运行。
这些型号也很大。即使你可以获得GPT-3型号,你也无法在商品硬件上运行它——这些东西通常需要几个A100级GPU,每个GPU的零售价超过8000美元。
这项技术显然太重要了,不能完全由一小群公司控制。
在过去的几年里,已经发布了数十个开放的大型语言模型,但就以下方面而言,它们都没有达到我的甜蜜点:
- 易于在自己的硬件上运行
- 大到足以有用——在能力上等同于GPT-3
- 足够开源,以至于他们可以修补
由于Facebook的LLaMA模型和Georgi Gerganov的llama.cpp的组合,这一切昨天发生了变化。
这是LLaMA论文的摘要:
我们介绍了LLaMA,这是一个从7B到65B参数的建立语言模型的集合。我们在数万亿个令牌上训练我们的模型,并表明可以完全使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。特别是,LLaMA-13B在大多数基准测试上的表现优于GPT-3(175B),LLaMA-65B与最好的型号Chinchilla-70B和PaLM-540B竞争。我们向研究界发布所有模型。
需要注意的是,LLaMA并不完全“开放”。您必须同意一些严格的条款才能访问模型。它旨在作为研究预览,不是可用于商业目的的东西。
在完全的赛博朋克行动中,在发布后的几天内,有人将此PR提交给了LLaMA存储库,链接到模型文件的非官方BitTorrent下载链接!
所以他们现在在野外。你可能无法合法地在他们身上制造商业产品,但精灵已经从瓶子里出来了。你可以听到的愤怒的打字声是,世界各地的数千名黑客开始挖掘并弄清楚当你可以在自己的硬件上运行GPT-3类模型时,生活是什么样子的。
llama.cpp
如果LLaMA本身在个人笔记本电脑上运行仍然太难,那么它本身就不是很好。
Georgi是位于保加利亚索非亚的开源开发人员(根据他的GitHub个人资料)。他之前发布了whis语.cpp,这是OpenAI的Whisper自动语音识别模型到C++的移植版。该项目使Whisper适用于大量新用例。
他刚刚和LLaMA做了同样的事情。
Georgi的llama.cpp项目昨天首次发布。来自README:
主要目标是在MacBook上使用4位量化来运行模型。
4位量化是一种减小模型大小的技术,以便它们可以在功能较弱的硬件上运行。它还将磁盘上的型号大小减少到7B型号的4GB,13B型号的型号略低于8GB。完全有效!
今晚,我用它在我的笔记本电脑上运行了7B LLaMA型号,然后今天早上升级到了13B型号——Facebook声称该型号与GPT-3具有竞争力。
以下是我关于我如何做到的详细说明——我需要的大部分信息已经在README中了。
当我的笔记本电脑开始向我吐出短信时,我真的有一种感觉,世界又要改变了。
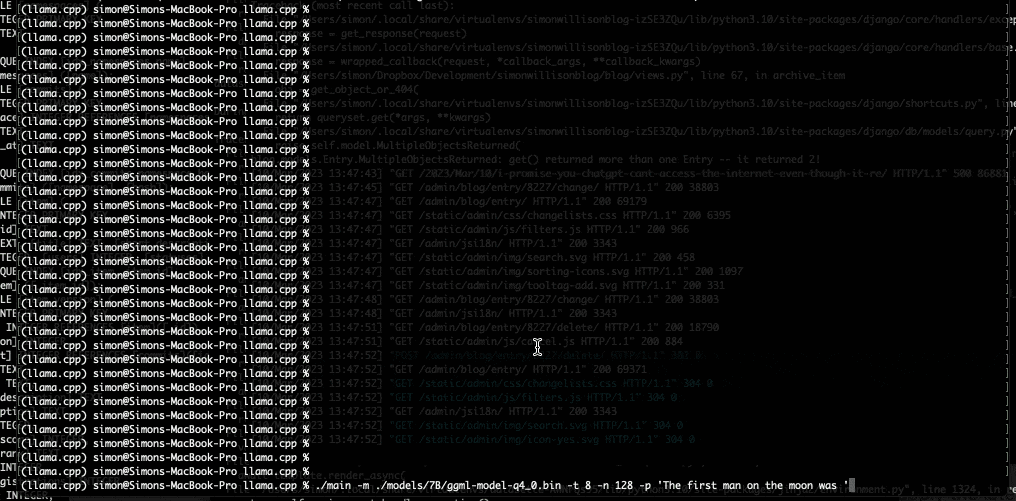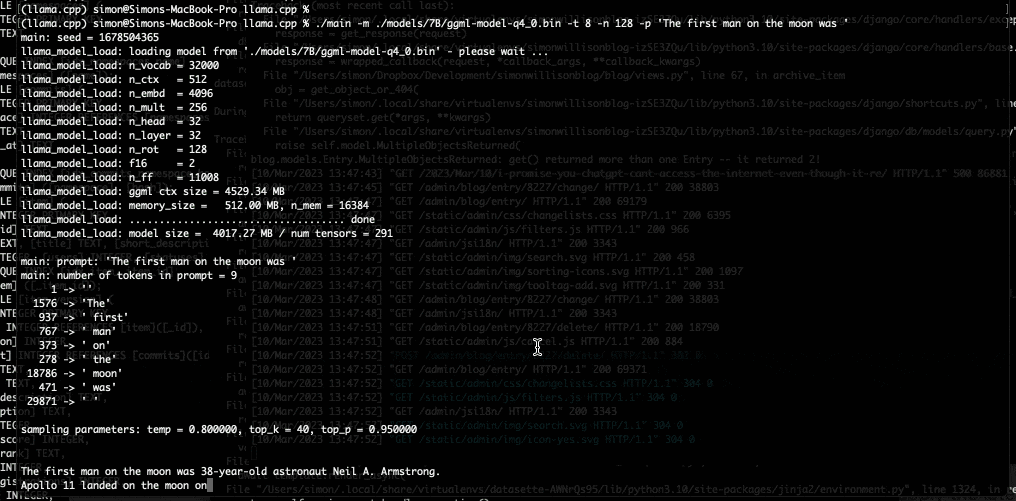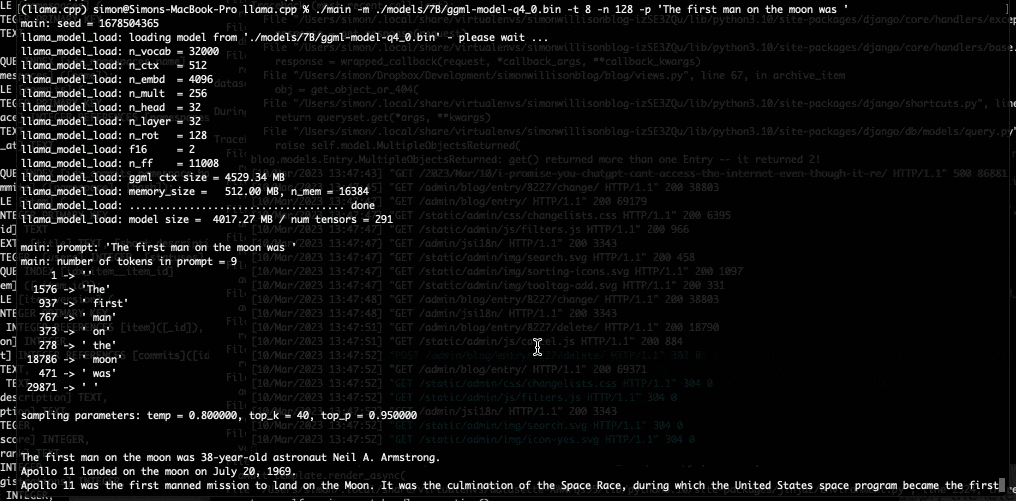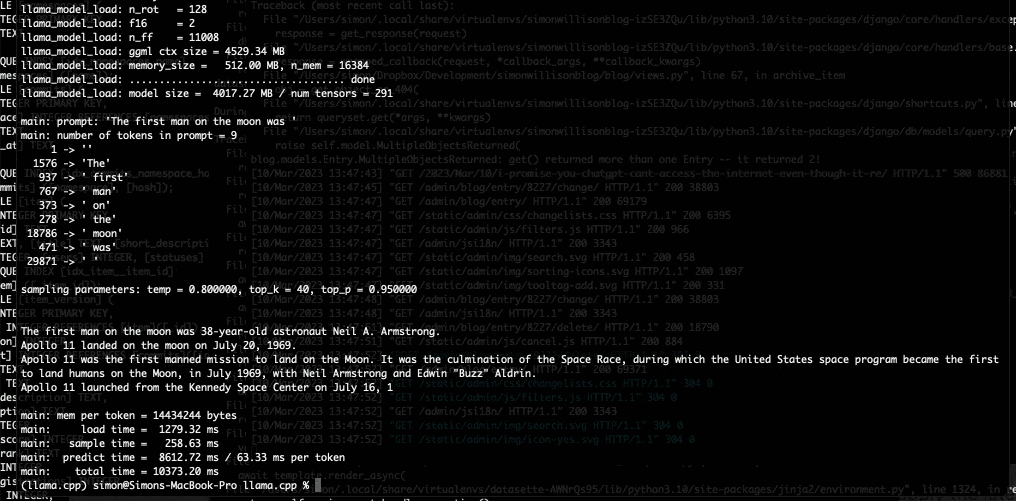
我以为再过几年,我才能在我拥有的硬件上运行GPT-3类模型。我错了:未来已经在这里了。
这是有史以来最糟糕的事情吗?
我不担心这里的科幻场景。我的笔记本电脑上运行的语言模型不是将挣脱并接管世界的AGI。
但有很多非常真实的方法可以将这项技术用于伤害。只是几个:
- 生成垃圾邮件
- 自动浪漫诈骗
- 挑術和仇恨言论
- 假新闻和虚假信息
- 自动激进化(我非常担心这个)
更不用说这项技术就像鹦鹉事实信息一样容易制造事情,并且无法分辨区别。
在此之前,像OpenAI这样的公司控制人们如何与这些模型互动的能力有限,就存在一层薄弱的防御层。
现在我们可以在自己的硬件上运行这些,甚至这些控件也消失了。
我们如何善用这个?
我认为这会对社会产生巨大影响。我的首要任务是试图将这种影响引向积极的方向。
很容易陷入一个愤世嫉俗的陷阱,认为这里根本没有什么好东西,所有生成的人工智能要么是积极的伤害,要么是浪费时间。
我现在每天都在使用生成人工智能工具,用于各种不同的目的。他们提高了我的物质生产力,但更重要的是,他们扩大了我承担的项目的雄心壮志。
就在上周,我使用ChatGPT学习了足够的AppleScript,在不到一个小时的时间内发布一个新项目!
我将继续探索和分享这项技术的真正积极应用。它不会是未经发明的,所以我认为我们的首要任务应该是找出最有建设性的可能使用它的方法。
接下来要寻找什么
假设Facebook不放宽许可条款,LLaMA最终可能会更多地证明本地语言模型在消费者硬件上是可行的,而不是人们未来使用的新基础模型。
比赛即将发布第一个完全开放的语言模型,该模型为人们在自己的设备上提供类似ChatGPT的功能。
引用 Stable Diffusion 支持者Emad Mostaque的话:如果有一个完全开放的版本,那就不好了。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢