
HiCLIP 在 CLIP 的基础上进行了改进,纳入了层次感知的注意力,以无监督方式捕捉图像和文本中传达的高层次和细粒度的语义的层次性。
HiCLIP: Contrastive Language-Image Pretraining with Hierarchy-aware Attention
S Geng, J Yuan, Y Tian, Y Chen, Y Zhang
[Rutgers University & ByteDance Inc]
-
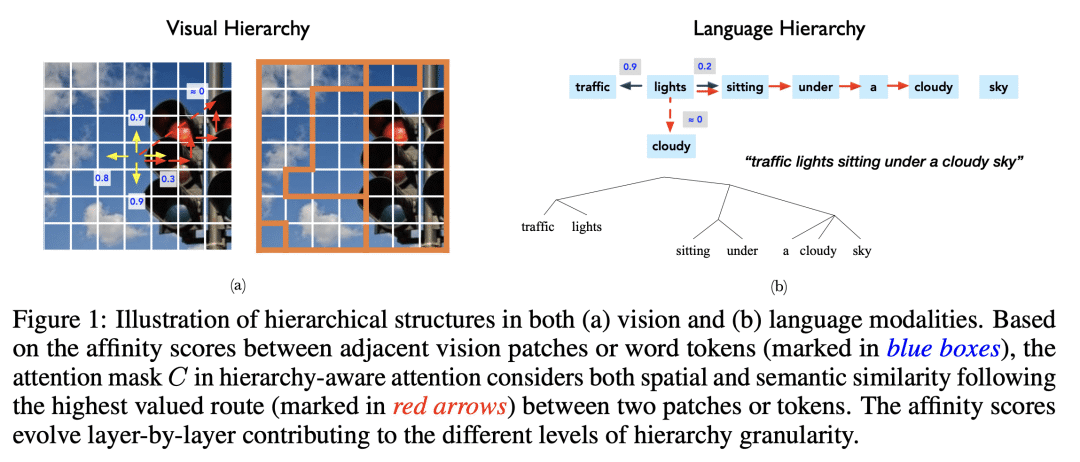
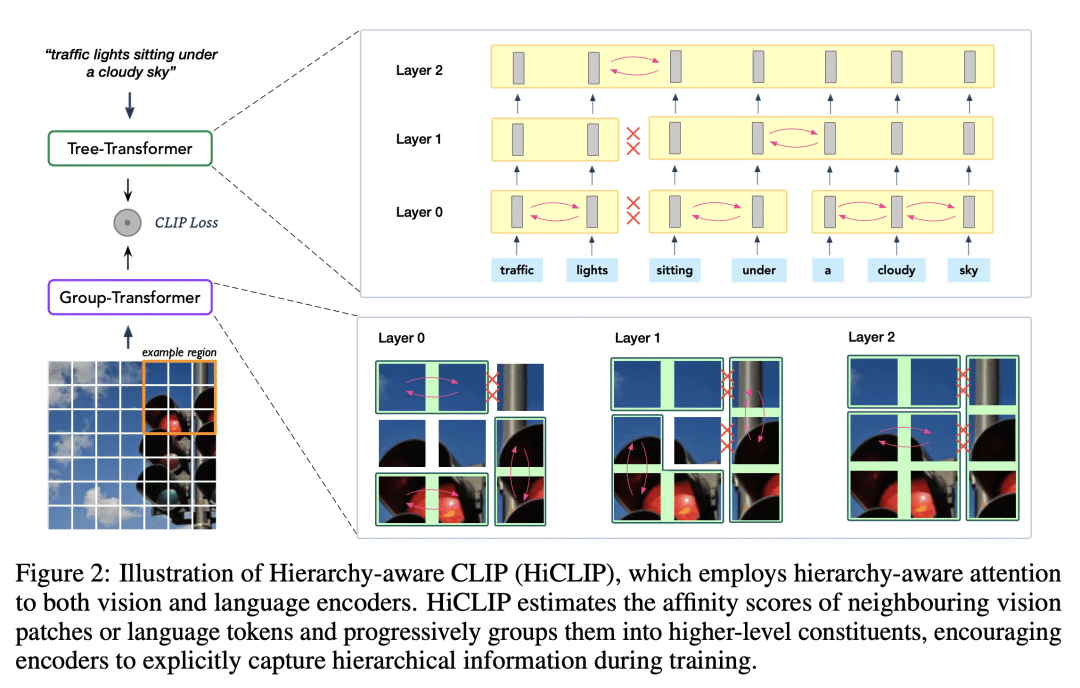
HiCLIP 为 CLIP 的视觉和语言分支都配备了层次感知的注意力,以自动从图像-描述对中捕捉层次结构;
-
所提出的 HiCLIP 通过逐渐将空间和语义上相似的图块或标记聚集到共同的组中来创建紧凑的图像和文本嵌入,与最近的几种 CLIP 式的方法相比,大大改善了图像和文本模态的一致性;
-
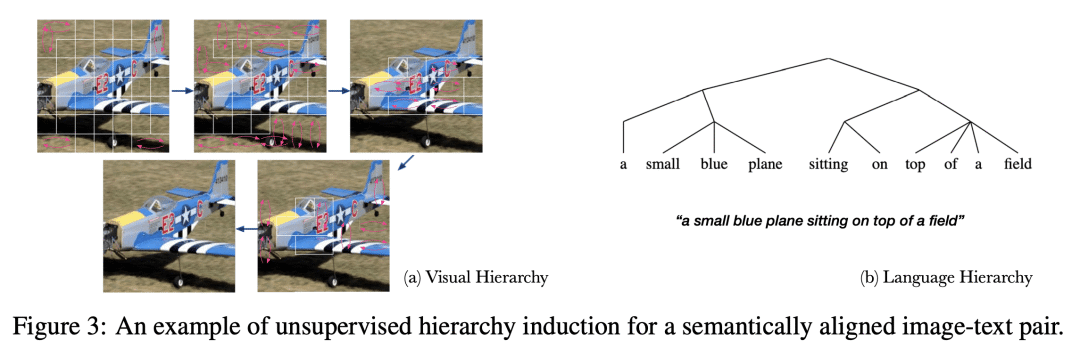
HiCLIP 可以通过分析生成的组成注意力权重,用于无监督的层次结构归纳,有助于提高可解释性;
-
HiCLIP 的未来方向包括扩大预训练数据集的规模,用更好的多模态信息融合操作来探索层次感知注意力的全部潜力,并验证该方法的可扩展性。
https://arxiv.org/abs/2303.02995

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢