
标题:Image as Set of Points
作者:Xu Ma, Yuqian Zhou, Huan Wang, Can Qin, Bin Sun, Chang Liu, Yun Fu
原文链接:https://openreview.net/forum?id=awnvqZja69
代码链接:https://anonymous.4open.science/r/ContextCluster
我们提取特征的方式在很大程度上取决于我们如何解读图像。近年来,卷积神经网络 (ConvNets) 作为一种基本范式在计算机视觉领域占据主导地位,并显着提高了各种视觉任务的性能。从方法论上讲,ConvNets 将图片概念化为矩形排列像素的集合,并以滑动窗口方式使用卷积提取局部特征。受益于一些重要的归纳偏差,如局部性和翻译等方差,ConvNets 变得高效和有效。最近,Vision Transformers (ViTs) 极大地挑战了 ConvNets 在视觉领域的统治地位。Transformers 将图像视为一系列token,并采用全局范围的自注意力操作来自适应地融合来自补丁的信息。通过生成的模型(即 ViTs),放弃了 ConvNets 中固有的inductive bias,并获得了令人满意的结果。最近的工作显示了视觉社区的巨大改进,这些改进主要建立在卷积或注意力之上。同时,一些尝试将卷积和注意力结合在一起,如 CMT。这些方法在卷积神经网络中对图像进行编译,同时利用注意力探索图像中context的关系。 基于 MLP 的架构已经说明,纯基于 MLP 的设计也可以实现类似的性能。此外,将图网络作为特征提取器被证明是可行的。因此,我们期待一种新的特征提取范例,它可以提供一些新颖的见解,而不是渐进式的创新。
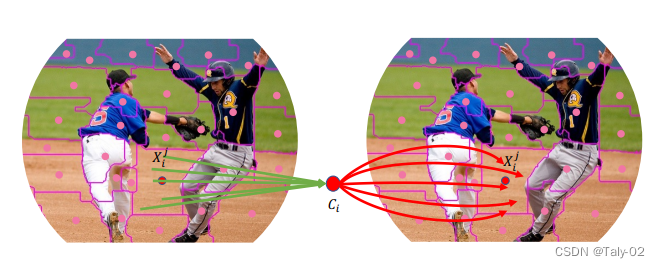
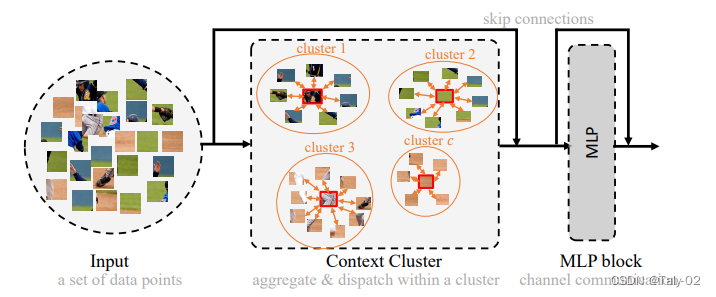
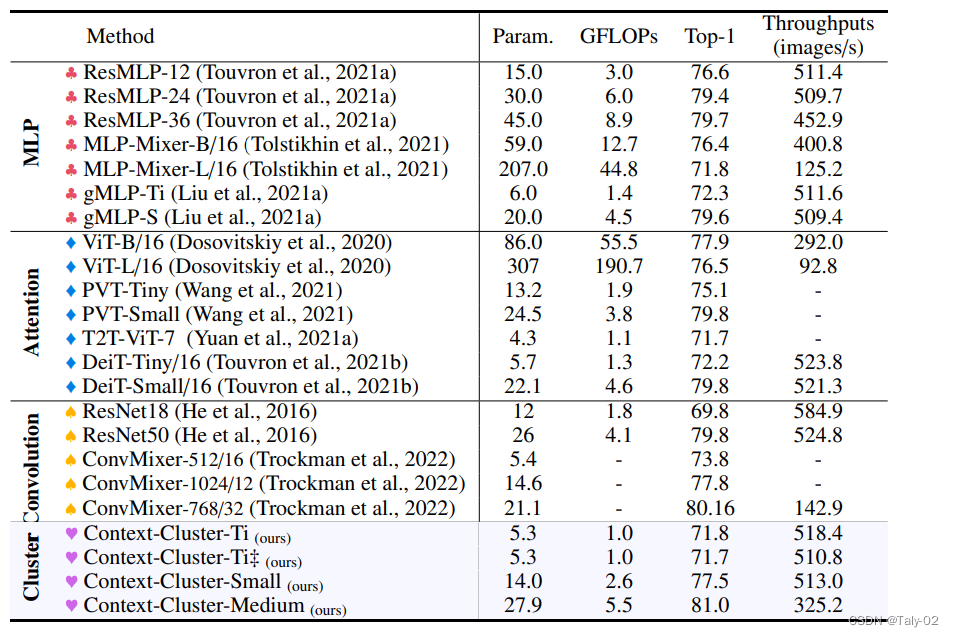
在这项工作中,从整体上讲,论文将图像视为一组point并将所有点分组到set中。如上图所示, 在每个set中,我们将point聚合到一个中心,然后自适应地将中心点分配给所有点。我们称这种设计为上下文的簇(context cluster)。具体来说,我们将每个像素视为具有颜色和位置信息的 5 维数据点。从某种意义上说,我们将图像转换为一组点云,并利用点云分析的方法进行图像视觉表征的learning。这弥合了图像和点云的表示,显示出强大的泛化能力,并为轻松融合多模态提供了可能性。 本文应该是是第一份为一般视觉representation引入聚类方法并使其发挥作用的人。总的来说,本文提出了一种新的visual representation learning的pipeline,称为上下文集群(CoC)。主要思想是将图像视为一组点(类似于点云)并使用聚类算法形成局部上下文集群,而不是将图像视为规则的补丁网格。集群中的点特征使用自适应平均池聚合,然后通过全连接层“分发”回组成点。该架构进一步考虑了多头调度,就像在自注意力网络中一样。在各种识别任务上给出了实验结果,包括 ImageNet-1K 对象识别、ScnObjectNN 上的 3D 点云分类、MS-COCO 上的对象检测和实例分割以及 ADE20K 上的语义分割。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢