
Cal-QL 是一种从离线数据中学习有效初始化的方法,可实现快速在线微调。
Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
Mitsuhiko Nakamoto, Yuexiang Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, Sergey Levine
[UC Berkeley & Stanford University]
-
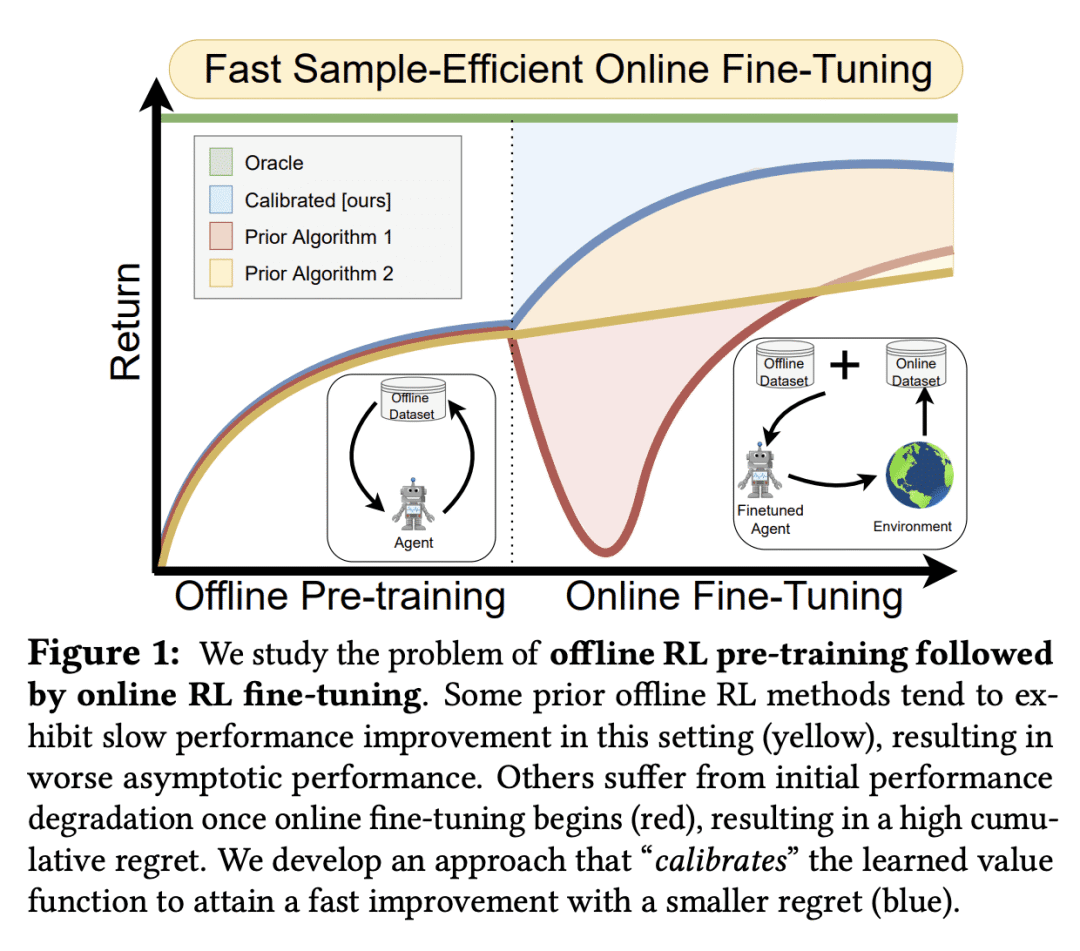
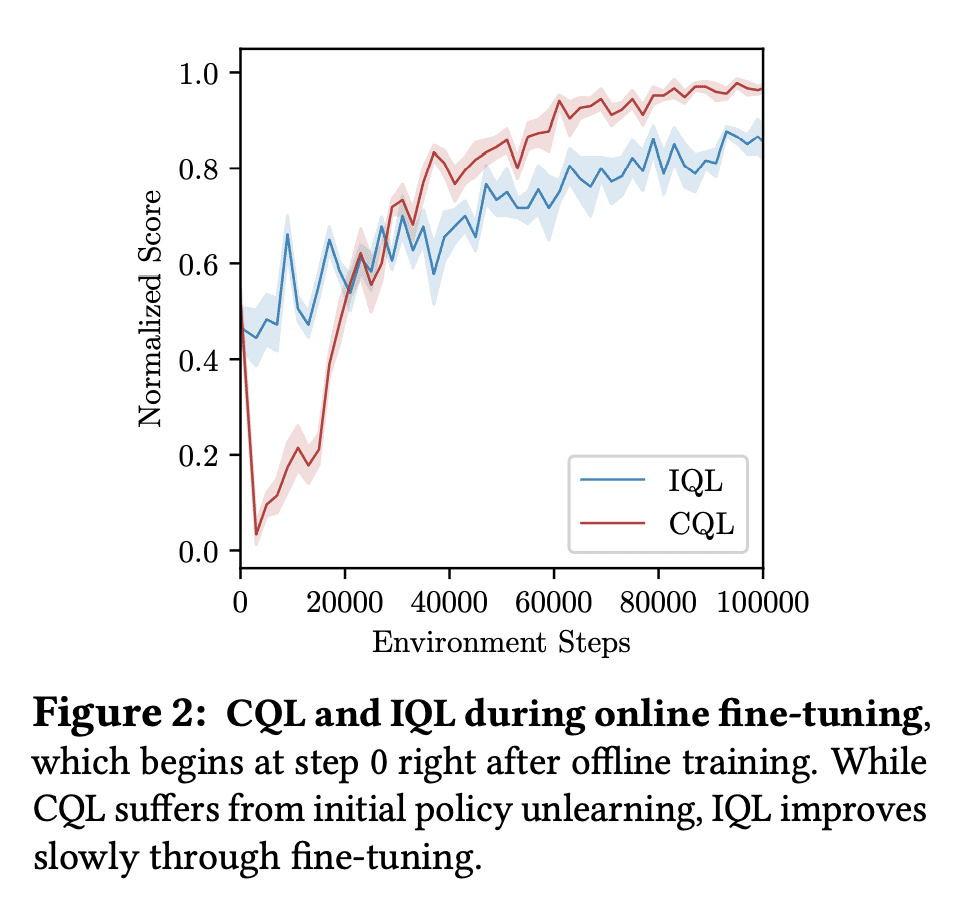
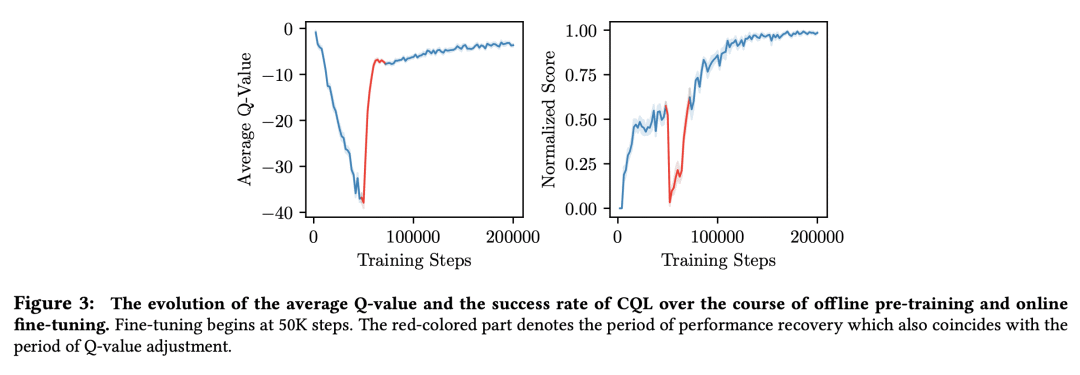
离线强化学习可以从现有的数据集获得策略初始化,但现有的方法往往表现出较差的在线微调性能;
-
在线强化学习方法通过在线交互有效学习,但在纳入离线数据方面却很困难;
-
Cal-QL 学习一个保守的价值函数初始化,它低估了从离线数据中学习的策略的价值,同时也被校准,这导致有效的在线微调;
-
在研究的10/11个微调基准任务中,Cal-QL 的表现优于最先进的方法。
https://arxiv.org/abs/2303.05479

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢