
本文研究使用有限资源(如单个商品GPU)进行高吞吐量的LLM推理,提出了FlexGen,一个用于在有限的GPU内存中运行LLM的高吞吐量生成引擎。FlexGen可以在各种硬件资源限制下灵活配置,通过聚合GPU、CPU和磁盘的内存和计算。
High-throughput Generative Inference of Large Language Models with a Single GPU
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, Ce Zhang
[Stanford University &b UC Berkeley & ETH Zurich & Yandex & HSE University & Meta & Carnegie Mellon University]
- 传统上,大型语言模型(LLM)推理对计算和内存的要求很高,只有使用多个高端加速器才可行。
- 出于对分批处理的延迟不敏感任务的新需求,本文开始研究使用有限资源(如单个商品GPU)进行高吞吐量的LLM推理。本文提出了FlexGen,一个用于在有限的GPU内存中运行LLM的高吞吐量生成引擎。FlexGen可以在各种硬件资源限制下灵活配置,通过聚合GPU、CPU和磁盘的内存和计算。
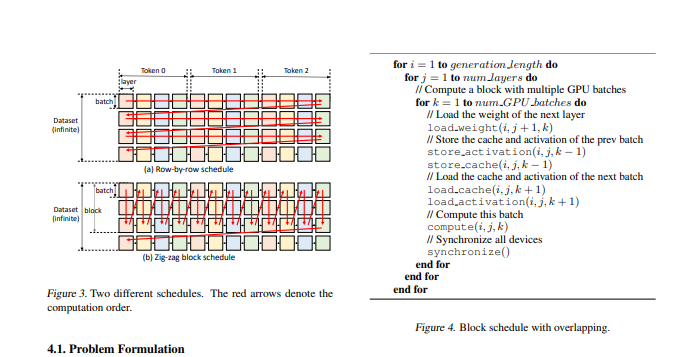
- 通过线性编程优化器,它搜索有效的模式来存储和访问张量。FlexGen进一步将这些权重和注意力缓存压缩到4位,其精度损失可忽略不计。这些技术使FlexGen有更大的批量大小选择空间,从而显著提高最大吞吐量。
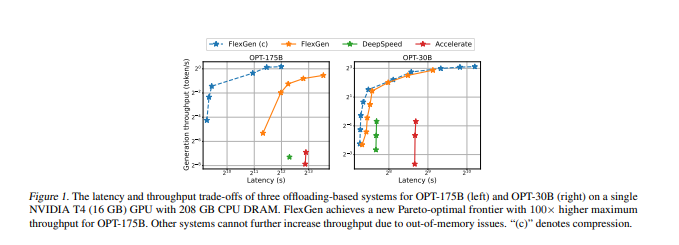
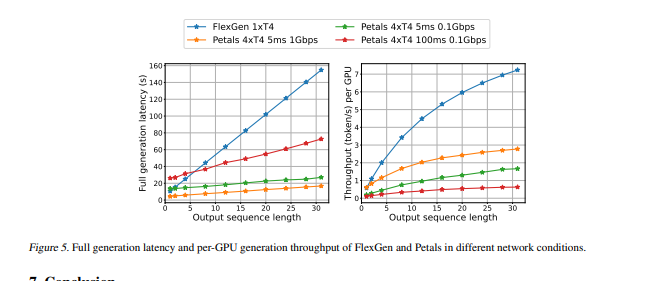
- 因此,当在单个16GB的GPU上运行OPT-175B时,与最先进的卸载系统相比,FlexGen实现了明显更高的吞吐量,在有效批次大小为144时,首次达到了1 token/s的生成吞吐量。在HELM基准测试中,FlexGen可以在21小时内用16GB的GPU对7个代表性的子场景进行30B模型的基准测试。该代码可在此https://github.com/FMInference/FlexGen网址上获得
https://arxiv.org/pdf/2303.06865.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢