
微软提出了"Meet in the Middle",一种同时使用前向和后向LM的方法。这种方法同时使用前向和后向LM,它们共享参数并被训练成彼此一致,此外还能预测下一个标记。由此产生的前向LM可以直接替代替换现有的自回归LM,同时还能在强大的基线上实现更好的质量。
Meet in the Middle: A New Pre-training Paradigm
Anh Nguyen, Nikos Karampatziakis, Weizhu Chen
[Microsoft Azure AI]
- 大多数语言模型(LMs)是以自回归的方式从左到右进行训练和应用的,假设下一个标记只取决于前面的标记。然而,这种假设忽略了在训练过程中使用完整序列信息的潜在好处,以及在推理过程中拥有来自双方的背景的可能性。
- 在本文中,提出了一种新的预训练范式,其技术可以共同提高训练数据的效率和填充任务中LM的能力。
- 首先是一个训练目标,使从左到右的LM的预测与从右到左的LM的预测相一致,在相同的数据上训练,但顺序相反。
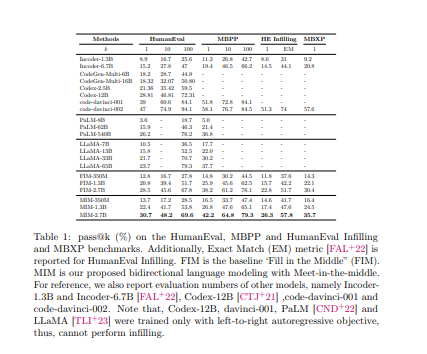
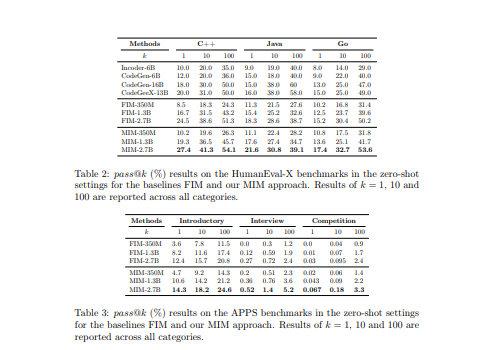
- 第二个是一个双向推理程序,使两个LM在中间相遇。通过对编程和自然语言模型进行广泛的实验,证明了我们的预训练范式的有效性,其表现优于强大的基线。
https://arxiv.org/pdf/2303.07295.pdf



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢