


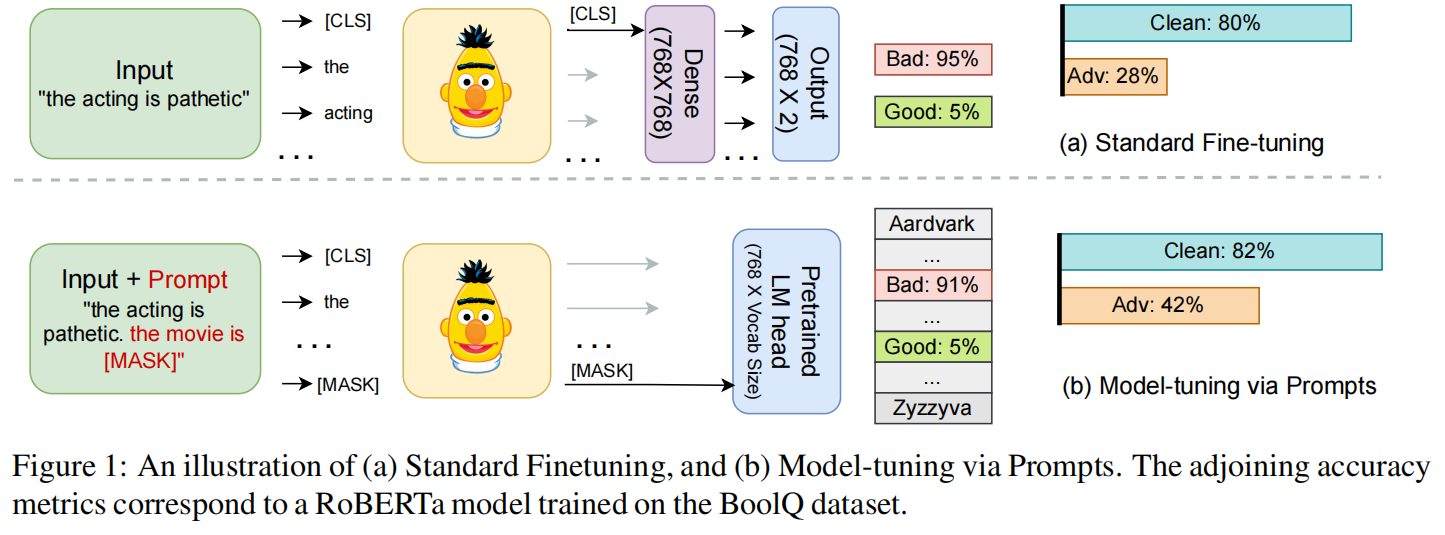
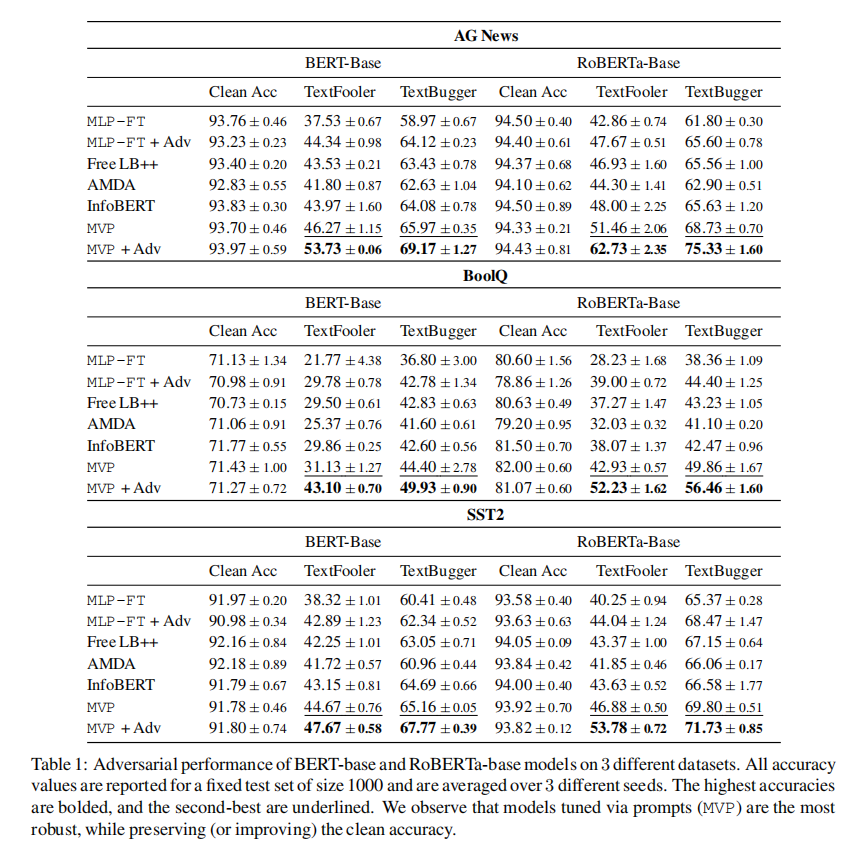
近年来,NLP研究者在如下三个方面展开了丰富的实践:1)利用离线预训练的语言模型;2)在模型的中间表达中添加不同的Token;3)在下游任务中微调整个模型。这一流程在诸多NLP任务上均取得了较好的性能提升,但这些模型对对抗扰动的鲁棒性仍未得到有效探索和提升。在本文中,作者证实这一问题的解决方法包含通过Prompt微调模型(Model-tuning via Prompts, MVP)。与添加Token微调模型参数这一常规做法不同,MVP的目的在于为输入添加合适的提示(Prompts)。实验表明,MVP在三个常用的分类数据集上可以提升模型约8%的鲁棒性,超出已有研究3.5%。
论文地址:https://arxiv.org/pdf/2303.07320.pdf
开源代码(暂未发布):https://github.com/acmi-lab/mvp
作者:Mrigank Raman, Pratyush Maini, Zico Kolter, Zachary C. Lipton, Danish Pruthi
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢