

大规模视觉-语言模型可通过使用稀疏门控专家混合(MoE)进行有效扩展,可以在一些基准上达到最先进的性能,同时降低计算成本。
Scaling Vision-Language Models with Sparse Mixture of Experts
Sheng Shen, Zhewei Yao, Chunyuan Li, Trevor Darrell, Kurt Keutzer, Yuxiong He
[Microsoft & UC Berkeley]
基于稀疏混合专家的视觉语言模型规模扩展
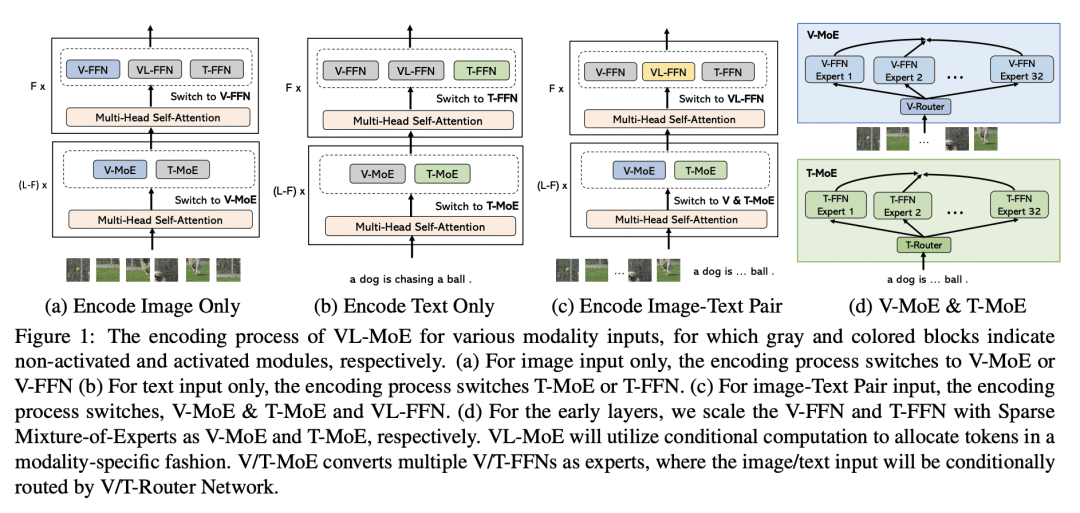
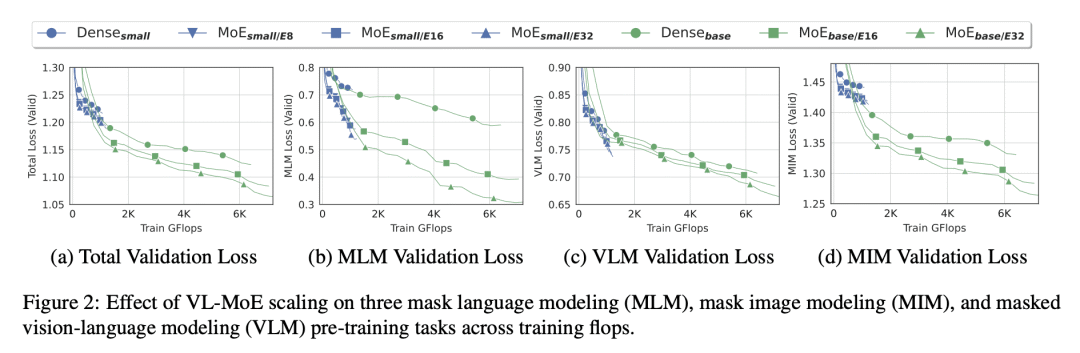
稀疏门控专家混合(MoE)可有效地扩展大型视觉-语言模型,在一些基准上达到最先进的性能,同时降低计算成本。通过 MoE 将一个大型视觉-语言模型划分为较小的、专门的子模型,可以通过更好地了解模型如何处理不同的输入来提高模型的可解释性;MoE 中较大的专家库产生了一致的性能改进;为探索 MoE 在其他视觉-语言任务中的有效性开辟了新的研究方向,如视觉答、视觉推理和图像-文本检索。
https://arxiv.org/abs/2303.07226

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢