
我们提出了LERF,一种以密集、多尺度的方式将原始CLIP嵌入融合到NeRF中的新方法,不需要区域建议或微调。我们发现,它可以在不同的真实世界场景中支持广泛的自然语言查询,在支持自然语言查询方面强烈地超过了像素对齐的LSeg。LERF是一个通用框架,支持任何对齐的多模态编码器,这意味着它可以自然地支持视觉语言模型的改进。代码和数据集 将在提交过程中发布。
LERF: Language Embedded Radiance Fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik
[UC Berkeley]
- 人类使用自然语言来描述物理世界,根据大量的属性来指代特定的三维位置:视觉外观、语义、抽象联想或可操作的能力。
- 在这项工作中,提出了语言嵌入辐射场(Language Embedded Radiance Fields, LERFs),这是一种将语言嵌入从现成的模型(如CLIP)落地到NeRF的方法,它使这些类型的开放式语言查询在3D中得以进行。
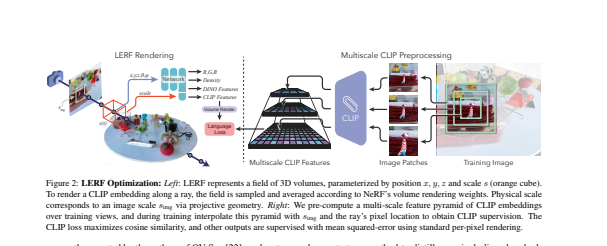
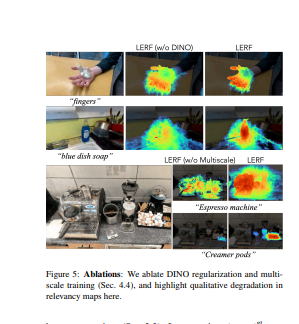
- LERF通过沿着训练射线的体积渲染CLIP嵌入,在NeRF内部学习一个密集的、多尺度的语言场,监督这些嵌入跨训练视图,以提供多视图一致性和平滑的基础语言场。
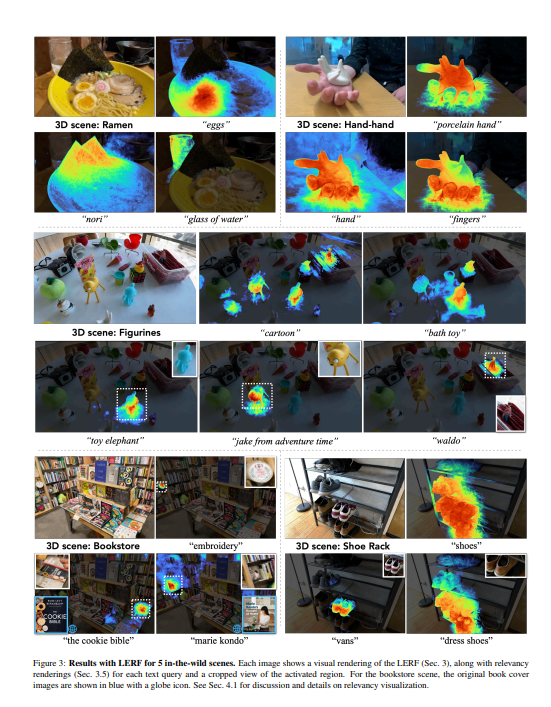
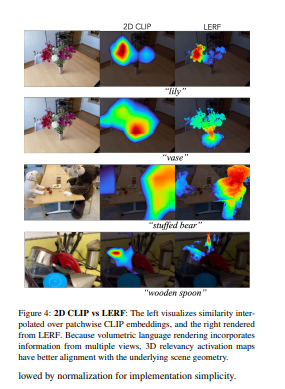
- 经过优化,LERF可以为广泛的语言提示实时互动地提取3D相关性地图,这在机器人、理解视觉语言模型和与3D场景互动方面有潜在的用例。LERF能够对提炼出来的三维CLIP嵌入进行像素对齐的零点查询,而不依赖于区域建议或掩码,支持整个卷内分层的长尾开放词汇查询。该项目网站可以在https://lerf.io。
https://arxiv.org/pdf/2303.09553.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢