
在本文中,提出了一个新的文本驱动的视频编辑框架FateZero,它可以对属性、风格和形状进行时间上的一致性编辑。首次尝试研究和利用DDIM反演过程中的交叉注意和空间-时间自我注意,在每个去噪步骤中提供细粒度的运动和结构指导。进一步提出了一个新的注意力混合块,以提高框架的形状编辑性能。该框架有利于使用广泛存在的图像扩散模型进行视频编辑,我们相信这将有助于许多新的视频应用。
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, Qifeng Chen
[HKUST & Tencent AI Lab & CAIR, HKISI-CAS]
- 基于扩散的生成模型在基于文本的图像生成中取得了显著的成功。然而,由于它在生成过程中包含巨大的随机性,将这种模型应用于现实世界的视觉内容编辑,特别是视频,仍然是一个挑战。
- 在本文中,提出了FateZero,一种在现实世界的视频中基于零镜头的文本编辑方法,无需按提示训练或特定用途的掩码。为了稳定地编辑视频,提出了几种基于预训练模型的技术。
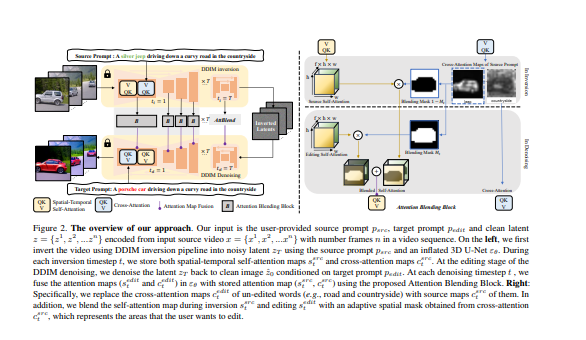
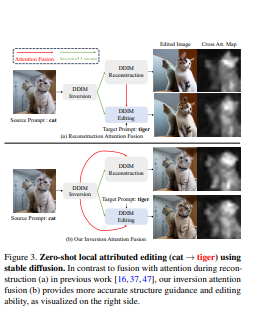
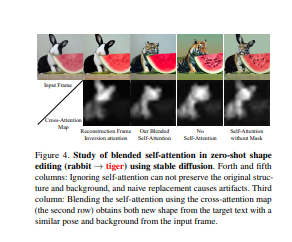
- 首先,与直接的DDIM反转技术相比,我们的方法在反转过程中捕获了中间的注意力图,它有效地保留了结构和运动信息。这些地图是在编辑过程中直接融合的,而不是在去噪过程中产生的。为了进一步减少源视频的语义泄漏,我们随后将自我注意力与由源提示的交叉注意力特征获得的混合掩码进行融合。
- 此外,通过引入空间-时间注意力以确保帧的一致性,对去噪UNet中的自我注意力机制进行了改革。然而,简洁的是,该方法是第一个显示出从训练好的文本到图像模型的零镜头文本驱动的视频风格和局部属性编辑的能力。还有一个更好的基于文本到视频模型的零镜头形状感知编辑能力。
- 大量的实验证明了此方法比以前的工作有更高的时间一致性和编辑能力。
代码:https://fate-zero-edit.github.io
https://arxiv.org/pdf/2303.09535.pdf




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢