
本文引入了SemDeDup,这是一种简单而可行的有效方法,它利用预先训练好的嵌入来去除语义上高度相似但不完全相同的语义重复。去除语义上的重复,可以提高学习速度和分布外的性能,同时在基本未整理的LAION上提供高达50%的效率提升,
SemDeDup: Data-efficient learning at web-scale through semantic deduplication
Amro Abbas, Kushal Tirumala, Dániel Simig, Surya Ganguli, Ari S. Morcos
[Meta AI (FAIR) & Stanford University]
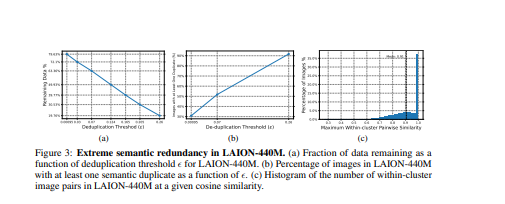
- 机器学习的进展在很大程度上是由数据的大量增加所推动的。然而,像LAION这样的大型网络规模的数据集在很大程度上除了搜索精确的重复数据外,还没有进行整理,可能会留下很多冗余的内容。
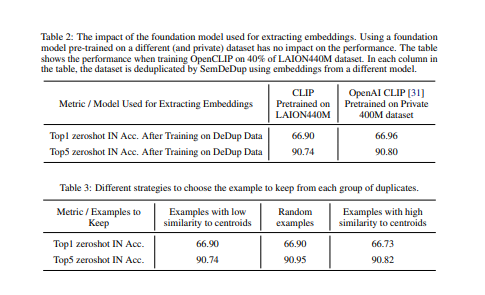
- 本文介绍了SemDeDup,一种利用预训练模型的嵌入来识别和删除语义重复的方法:语义相似但不完全相同的数据对。删除语义重复的数据可以保持性能并加快学习速度。
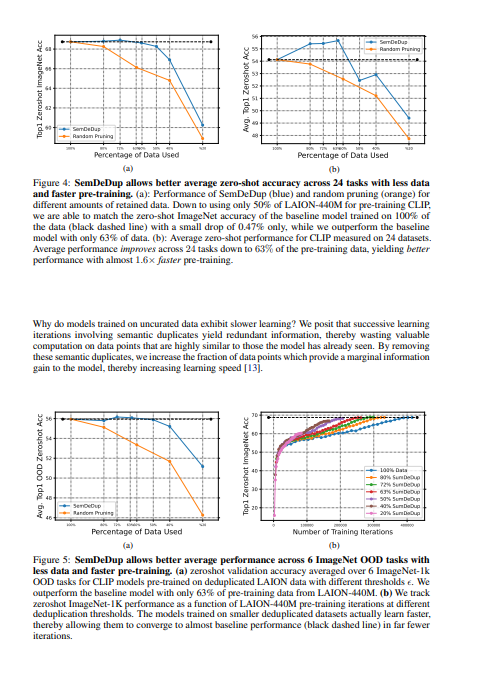
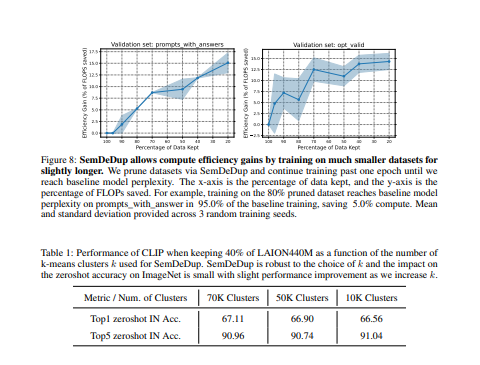
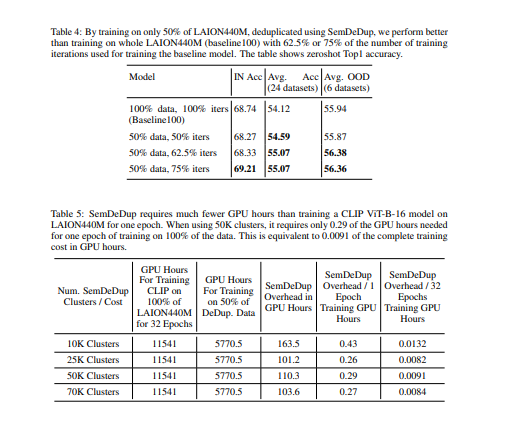
- 通过分析LAION的一个子集,发现SemDeDup可以在性能损失最小的情况下删除50%的数据,有效地将训练时间减半。
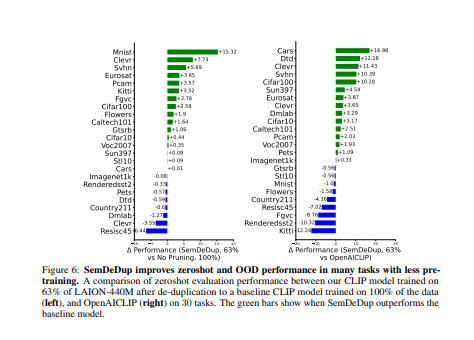
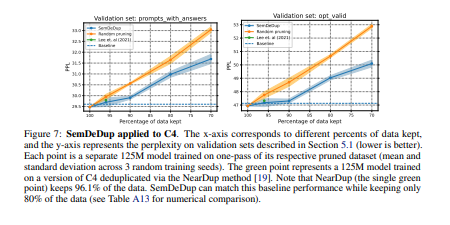
- 此外,性能在分布之外也会增加。另外,通过分析在C4(一个部分策划的数据集)上训练的语言模型,表明SemDeDup比之前的方法有所改进,同时提供了效率的提升。SemDeDup提供了一个例子,说明利用质量嵌入的简单方法可以用来使模型在更少的数据下学习得更快。
https://arxiv.org/pdf/2303.09540.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢