
本文提出了一个自下而上的方法,在多个基于视觉和语言模型的数据集中训练一个统一的视觉关系检测(VRD)模型。得到的检测器在两个VRD任务(人与物体的交互检测和场景图的生成)上显示了在特定数据集和统一配置下的竞争性性能。本文首次表明,扩大到大型模型可以使统一模型在VRD任务中受益。我们希望我们的模型能作为一个强大的基线方法,用于通用的VRD系统。
Unified Visual Relationship Detection with Vision and Language Models
Long Zhao, Liangzhe Yuan, Boqing Gong, Yin Cui, Florian Schroff, Ming-Hsuan Yang, Hartwig Adam, Ting Liu
[Google Research]
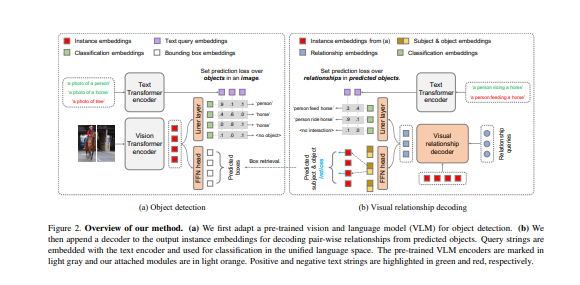
- 这项工作的重点是训练一个单一的视觉关系检测器,预测多个数据集的标签空间的联合。由于分类法的不一致,合并跨越不同数据集的标签可能是一个挑战。当二阶视觉语义被引入对象对之间时,这个问题在视觉关系检测中变得更加严重。
- 为了应对这一挑战,本文提出了UniVRD,这是一种新型的自下而上的方法,通过利用视觉和语言模型(VLMs)进行统一视觉关系检测。VLMs提供排列整齐的图像和文本嵌入,其中类似的关系被优化为接近彼此的语义统一。
- 本方法自下而上的设计使该模型能够享受到用物体检测和视觉关系数据集训练的好处。在人与物体的交互检测和场景图的生成方面的经验结果证明了模型的竞争性能。
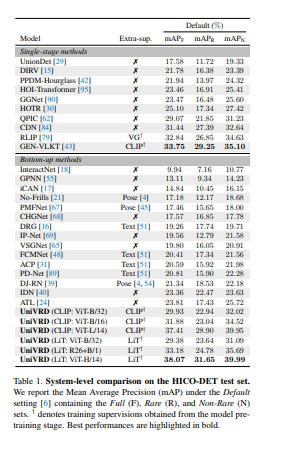
- UniVRD在HICO-DET上实现了38.07的mAP,比目前最好的自下而上的HOI检测器的性能相对高出60%。更重要的是,实验表明该统一检测器在mAP方面的表现与特定数据集的模型一样好,并且在扩大模型规模时取得了进一步的改进。
https://arxiv.org/pdf/2303.08998.pdf



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢