

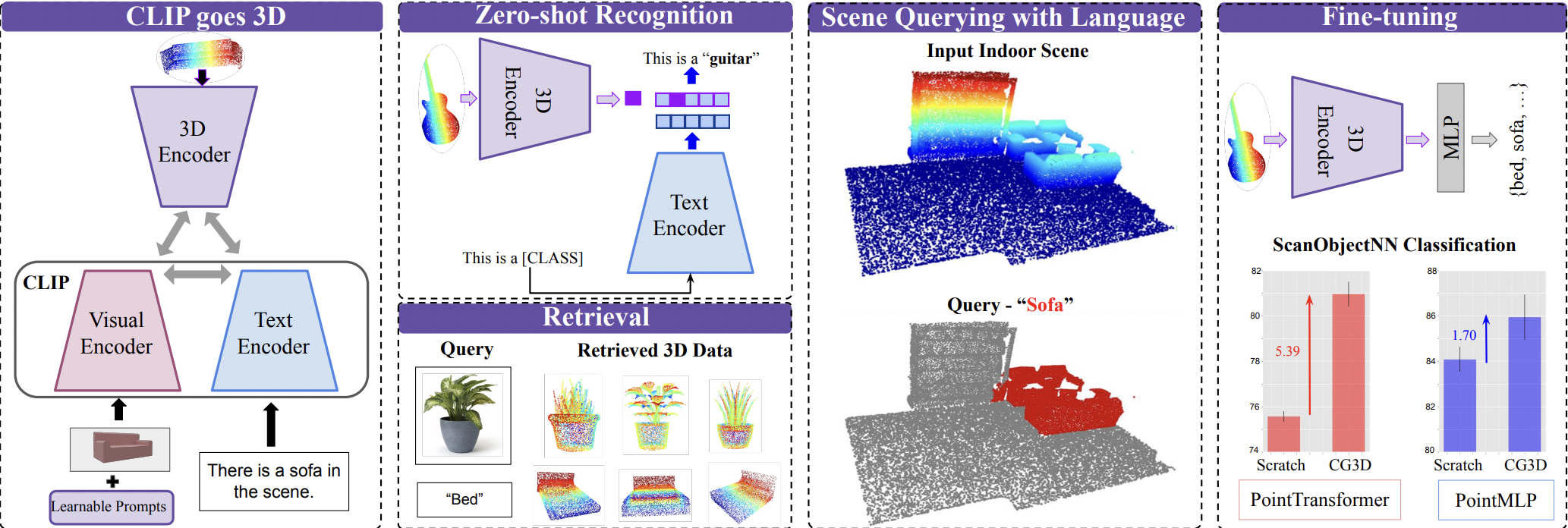
CLIP等视觉-语言大模型近期在小样本场景下展现出了强大的表征学习能力,进而被广泛应用于多种任务中。然而,CLIP这一系列模型在训练中仅包含文本监督下的图像和文本,它们难以被应用于提取3D集合特征。本文针对这一问题提出了一个新的框架CG3D(CLIP Goes 3D)。CG3D采用点云数据和具有文本监督信息的图像、文本进行训练。在此模型中,作者利用对比损失函数对齐多模态数据的映射特征,并通过提示学习解决了CLIP对自然图像和点云渲染图像的分布漂移问题。实验中,作者将CG3D在零样本学习、开放场景理解、开放场景检索任务汇总进行了对比,在SOTA的性能基础上进而发现CG3D对于下游3D目标识别任务的良好支撑作用。
论文地址:https://arxiv.org/abs/2303.11313
项目地址:https://jeya-maria-jose.github.io/cg3d-web/
作者:


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢