
论文标题:EVA-02: A Visual Representation for Neon Genesis
论文链接:https://arxiv.org/pdf/2303.11331.pdf
代码链接:https://github.com/baaivision/EVA
作者姓名:Yuxin Fang2,1, Quan Sun1, Xinggang Wang2, Tiejun Huang1, Xinlong Wang1, Yue Cao1
作者单位:北京智源人工智能研究院(1BAAI) & 华中科技大学 (2HUST)
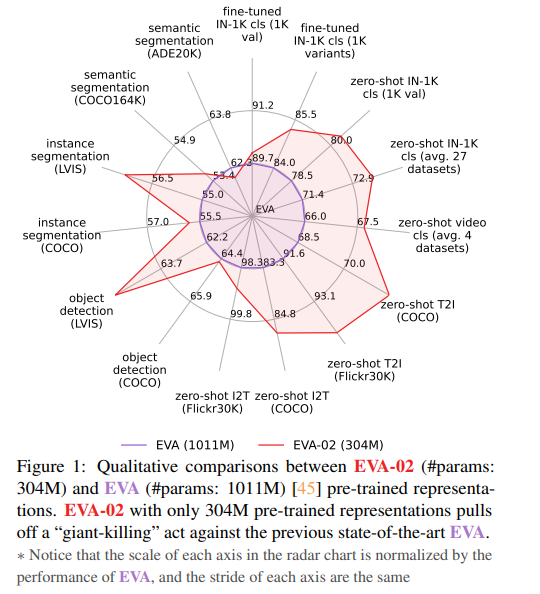
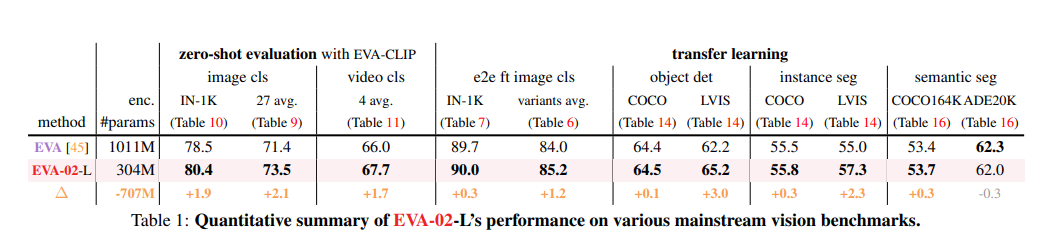
我们推出了 EVA-02,这是一种经过预训练的下一代基于 Transformer 的视觉表示,可通过掩码图像建模重建强大而稳健的语言对齐视觉特征。 凭借更新的普通 Transformer 架构以及来自开放和可访问的巨型 CLIP 视觉编码器的广泛预训练,EVA-02 在各种代表性视觉任务中展示了与先前最先进方法相比的卓越性能,同时使用更少参数和计算预算。 值得注意的是,仅使用 304M 参数的 EVA-02 使用完全可公开访问的训练数据,在 ImageNet-1K 验证集上实现了惊人的 90.0 微调 top-1 精度。 此外,我们的 EVA-02-CLIP 可以在 ImageNet-1K 上达到高达 80.4 的零样本 top-1,仅用 ∼1/6 的参数和 ∼1/6 的图像文本训练就优于之前最大和最好的开源 CLIP 数据。 我们提供四种不同型号尺寸的 EVA-02 变体,参数范围从 6M 到 304M,均具有令人印象深刻的性能。 为了促进开放获取和开放研究,我们向社区发布了完整的 EVA-02 套件。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢