
在北京时间3月21日23点举行的GTC 2023的首日主题演讲上,英伟达的创始人黄仁勋发布了四款AI推理芯片,包括针对生成式AI图像处理、大模型处理的芯片;发布了三个大模型云服务,分别适用于文本、图像和生物研究;发布了超级计算机,以及针对场景优化的应用100个、更新功能的工业元宇宙Omniverse。
四款AI推理芯片:英伟达发布四款AI推理芯片
英伟达发布四款AI推理芯片
设计一个云数据中心来处理生成式AI是一个巨大的挑战:理想情况下最好使用一种加速器,因为这使得数据中心具有弹性,能够处理不可预测的流量高峰和低谷:没有一个加速器能以最优的方式处理算法、模型、数据类型和大小的多样性。
英伟达在GTC 2023上,发布了新的“兼具加速功能和弹性”的推理平台——四种配置、一个体系架构、一个软件栈。

英伟达一口气推出了四款新的芯片,第一款为AI视频芯片 L4。L4是一款针对视频的云推理芯片,功能主要集中于视频解码和转码、频内容审核、视频通话等,例如在视频通话过程中的背景替换、重新打光、增加眼神交流、语音转录和实时语言翻译等。
性能方面,在AI视频领域,一台配备 8个L4的服务器可以取代 100 多台双插槽 CPU 服务器。目前,谷歌云平台已成为首批使用英伟达 AI 云技术的企业之一。
同样是图像领域,推理芯片L40主要用于Omniverse、图形渲染和生成式AI,包括文本到图像和文本到视频等。L40的主要应用场景对标的是在2018年推出、至今仍是推理芯片主流的T4。根据英伟达的介绍,L40 的性能是 T4 的 10 倍,这让L40在处理上述任务时都更加高效。
通过L40,AI编辑软件Runway让用户可以轻松地通过几个笔触就从视频中删除一个对象,或者改变视频的背景或前景。相信目前流行的AI图片生成平台Midjourney、Stable Diffusion、DALL-E等都可以通过L40创造更多的可能性。
可以看到,虽然同为针对图像的AI推理芯片,L4关于云端的视频场景,而L40则更通用,可以实现所有与图像相关的场景优化。

英伟达宣布推出H100 NVL - 用于大型语言模型的最大内存服务器卡
2022年的GTC上,英伟达带来了全新GPU架构NVIDIA Hopper,同时推出了首个基于Hopper架构打造的产品NVIDIA H100。一年的时间里,H100已经成为各大科技训练人工智能模型使用最多的GPU之一。
在此次GTC 2023上,黄仁勋推出了一个巨大的专门用于训练大型语言模型(LLM)的GPU——H100 NVL。
这是一个基于去年英伟达发布的H100的改进版本,它将两个H100 GPU通过NVLink拼接在一起,支持188 GB HBM3内存。卡名称中的“NVL”代表 NVLink,它通过外部接口(桥接器)以600 GB/s的速度连接两张H100。但实际上如果在技术条件允许的前提下,通过NVLink协议可以将至多256 个H100连接在一起。
这不是一个消费级的GPU产品,H100 NVL是为了服务于大型语言模型,这个专用的GPU计划于下半年推出。
大模型对内存和计算方面的需求较高,也需要很高容量的横向扩展能力。目前,能够处理拥有1750 亿参数的 GPT-3 等大型语言模型的只有A100,而GPT-4等参数量更大的模型则需要更多A100的堆叠。性能方面,一台8卡的H100 NVL的速度是目前标配8卡A100服务器的10倍。这不仅意味着速度的提升,也将降低大模型公司在算力方面的成本。

原文地址
虽然今年的春季 GTC 活动没有采用 NVIDIA 的任何新 GPU 或 GPU 架构,但该公司仍在推出基于去年推出的 Hopper 和 Ada Lovelace GPU 的新产品。在高端市场,该公司近日宣布推出专门针对大型语言模型用户的新 H100 加速器变体:H100 NVL。
H100 NVL 是NVIDIA H100 PCIe 卡的一个有趣变体,标志着时代和NVIDIA在人工智能领域的广泛成功,它针对一个特定市场:大型语言模型(LLM)部署。这张卡片与NVIDIA通常的服务器产品有一些不同之处——最显著的是它是两个H100 PCIe板卡的组合——但是最大的卖点就是它拥有巨大的内存容量。这个结合了双GPU的卡提供了188GB的HBM3内存,每张卡片为94GB,每个GPU的内存超过了迄今为止的任何其他NVIDIA产品,甚至比H100系列内的其他产品还多。
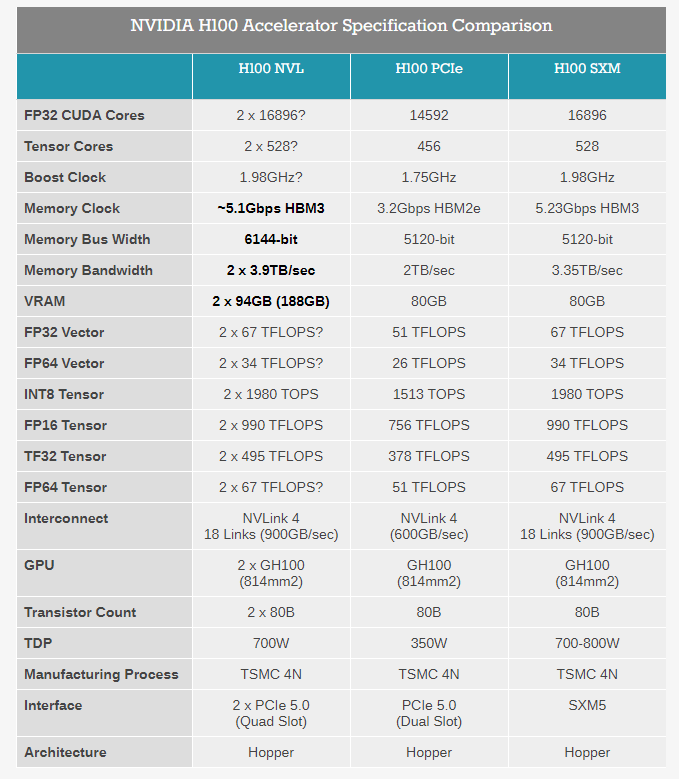
驱动此 SKU 的是一个特定的利基市场:内存容量。像 GPT 系列这样的大型语言模型在许多方面都受到内存容量的限制,因为它们甚至会很快填满 H100 加速器以保存它们的所有参数(在最大的 GPT-3 模型的情况下为 175B)。因此,NVIDIA 选择拼凑出一个新的 H100 SKU,它为每个 GPU 提供的内存比他们通常的 H100 部件多一点,后者最高为每个 GPU 80GB。
在引擎盖下,我们看到的本质上是放置在 PCIe 卡上的GH100 GPU的特殊容器。所有 GH100 GPU 都配备 6 个 HBM 内存堆栈(HBM2e 或 HBM3),每个堆栈的容量为 16GB。然而,出于产量原因,NVIDIA 仅在其常规 H100 部件中提供 6 个 HBM 堆栈中的 5 个。因此,虽然每个 GPU 上标称有 96GB 的 VRAM,但常规 SKU 上只有 80GB 可用。
反过来,H100 NVL 是神话般的完全启用的 SKU,启用了所有 6 个堆栈。通过打开第 6个HBM 堆栈,NVIDIA 能够访问它提供的额外内存和额外内存带宽。它将对产量产生一些实质性影响——多少是 NVIDIA 严密保守的秘密——但 LLM 市场显然足够大,并且愿意为近乎完美的 GH100 封装支付足够高的溢价,以使其值得 NVIDIA 光顾。
即便如此,应该注意的是,客户无法访问每张卡的全部 96GB。相反,在总容量为 188GB 的内存中,它们每张卡的有效容量为 94GB。在今天的主题演讲之前,NVIDIA 没有在我们的预简报中详细介绍这个设计怪癖,但我们怀疑这也是出于产量原因,让 NVIDIA 在禁用 HBM3 内存堆栈中的坏单元(或层)方面有一些松懈。最终结果是新 SKU 为每个 GH100 GPU 提供了 14GB 的内存,内存增加了 17.5%。同时,该卡的总内存带宽为 7.8TB/秒,单个板的总内存带宽为 3.9TB/秒。
除了内存容量增加之外,更大的双 GPU/双卡 H100 NVL 中的各个卡在很多方面看起来很像放置在 PCIe 卡上的 H100 的 SXM5 版本。虽然普通的 H100 PCIe 由于使用较慢的 HBM2e 内存、较少的活动 SM/张量核心和较低的时钟速度而受到一些限制,但 NVIDIA 为 H100 NVL 引用的张量核心性能数据与 H100 SXM5 完全相同,这表明该卡没有像普通 PCIe 卡那样进一步缩减。我们仍在等待产品的最终、完整规格,但假设这里的所有内容都如所呈现的那样,那么进入 H100 NVL 的 GH100 将代表当前可用的最高分档 GH100。
这里需要强调复数。如前所述,H100 NVL 不是单个 GPU 部件,而是双 GPU/双卡部件,它以这种方式呈现给主机系统。硬件本身基于两个 PCIe 外形规格的 H100,它们使用三个 NVLink 4 桥接在一起。从物理上讲,这实际上与 NVIDIA 现有的 H100 PCIe 设计完全相同——后者已经可以使用 NVLink 桥接器进行配对——所以区别不在于两板/四插槽庞然大物的结构,而是内部硅的质量。换句话说,您今天可以将普通的 H100 PCIe 卡捆绑在一起,但它无法与 H100 NVL 的内存带宽、内存容量或张量吞吐量相匹配。
令人惊讶的是,尽管有出色的规格,但 TDP 几乎保持不变。H100 NVL 是一个 700W 到 800W 的部件,分解为每块板 350W 到 400W,其下限与常规 H100 PCIe 的 TDP 相同。在这种情况下,NVIDIA 似乎将兼容性置于峰值性能之上,因为很少有服务器机箱可以处理超过 350W 的 PCIe 卡(超过 400W 的更少),这意味着 TDP 需要保持稳定。不过,考虑到更高的性能数据和内存带宽,目前还不清楚 NVIDIA 如何提供额外的性能。Power binning 在这里可以发挥很大的作用,但也可能是 NVIDIA 为卡提供比平常更高的提升时钟速度的情况,因为目标市场主要关注张量性能并且不会点亮整个 GPU一次。
否则,鉴于 NVIDIA 对 SXM 部件的普遍偏好,NVIDIA 决定发布本质上最好的 H100 bin 是一个不寻常的选择,但在 LLM 客户的需求背景下,这是一个有意义的决定。基于 SXM 的大型 H100 集群可以轻松扩展到 8 个 GPU,但任何两个 GPU 之间可用的 NVLink 带宽量因需要通过 NVSwitch 而受到限制。对于只有两个 GPU 的配置,将一组 PCIe 卡配对要直接得多,固定链路保证卡之间的带宽为 600GB/秒。
但也许比这更重要的是能够在现有基础设施中快速部署 H100 NVL。LLM 客户无需安装专门为配对 GPU 而构建的 H100 HGX 载板,只需将 H100 NVL 添加到新的服务器构建中,或者作为对现有服务器构建的相对快速升级即可。毕竟,NVIDIA 在这里针对的是一个非常特殊的市场,因此 SXM 的正常优势(以及 NVIDIA 发挥其集体影响力的能力)可能不适用于此。
综上所述,NVIDIA宣传H100 NVL提供的推理吞吐量是上一代HGX A100的12倍(8颗H100 NVL与8颗A100相比的GPT3-175B推理吞吐量)。对于希望尽快部署和扩展他们的系统以适应LLM工作负载的客户来说,这将是非常吸引人的。如前所述,就架构特性而言,H100 NVL并没有带来任何新的东西——其性能提升的很大一部分来自Hopper架构中的新Transformer引擎。但是,H100 NVL将在一个特定的领域发挥作用,因为它是最快的PCIe H100选项,并拥有最大的GPU内存池。
总的来说,据NVIDIA表示,H100 NVL卡将在今年下半年开始出货。公司没有公布价格,但由于它基本上是一款最高GH100级别的产品,我们预计它们的价格会很高。特别是随着LLM使用的爆炸式增长,这正成为服务器GPU市场的新热门,更增加了它们的高价值。
英伟达发布NVIDIA DGX Cloud人工智能云服务
英伟达的加速计算始于其AI超级计算机DGX,这是大语言模型背后的动力引擎。2016年,全球首款DGX由黄仁勋亲手交付给OpenAI,此后《财富》100强企业中有一半都安装了DGX,DGX成为AI研究的必备工具。
英伟达的创始人黄仁勋宣布发布NVIDIA DGX Cloud人工智能云服务。

“我们正处于人工智能的iPhone时代”,这句话是在黄仁勋宣布英伟达发布NVIDIA DGX Cloud人工智能云服务时说的,而它也可能会成为整个2023年人工智能市场的缩影。
NVIDIA DGX Cloud是一项人工智能超级计算服务,它可以让企业快速访问为生成式人工智能和其他开创性应用训练高级模型所需的基础设施和软件。DGX Cloud提供NVIDIA DGX AI超级计算专用集群,黄仁勋在大会宣布DGX H100人工智能超级计算机全面投产。
每个DGX Cloud中都集成了8个NVIDIA H100或A100 80GB Tensor Core(张量计算核心)的GPU,每个节点合计有640GB的GPU,这个巨大的GPU可以满足高级AI训练的性能要求。
而基于NVIDIA DGX Cloud提供的强大的算力基础,英伟达也基于此开发了一系列的应用模型,这些模型为特定领域的任务创建,通过专有的数据进行训练。英伟达在发布会上宣布了一个全新的NVIDIA AI Foundations模型,涵盖NVIDIA NeMo语言和NVIDIA Picasso图像、视频和3D等服务。
黄仁勋在介绍NVIDIA AI Foundations模型时表示,NeMo和Picasso服务会在NVIDIA DGX Cloud上运行,可以通过浏览器访问。开发人员可以通过API接口调用每项服务。
一旦模型部署完成,就可以使用NVIDIA AI Foundations模型在云服务上实现大规模的运算负载作业。每项云服务都包括六个要素:预训练模型、数据处理框架、矢量数据库和个性化、优化推理引擎、API,以及来自NVIDIA专家的支持,以帮助企业实现自定义模型的优化工作。
另外一个基于云服务的服务称为NVIDIA Picasso,这是一个可用于构建和部署生成式人工智能图像、视频和3D应用程序,具有从文本到图像、文本到视频和文本到3D动画的功能。英伟达在主题演讲中披露,他们将和Adobe扩大长期的合作关系,将创建下一代具有商业落地前景的生成式AI模型,而这套模型将由Adobe Creative Cloud和NVIDIA Picasso共同开发完成。
黄仁勋激动地表示:“NVIDIA DGX H100是全球客户构建AI基础设施的蓝图,已经全面投入生产。”
微软宣布Azure将向其H100 AI超级计算机开放私人预览版,AWS、Google Cloud、Oracle等云厂商,戴尔、联想等服务器厂商也将很快开放服务。

DGX最初用作AI研究,但现在正在扩展到更多的应用场景,黄仁勋将其称为“现代AI工厂”。
为了让客户更轻松、更快地享受英伟达AI服务,英伟达通过与微软Azure、谷歌GCP、甲骨文OCI合作,推出英伟达的AI云服务(NVIDIA DGX Cloud),为客户提供端到端的AI服务。
甲骨文将成为英伟达AI云的首个云合作伙伴。英伟达宣布有50家早期企业客户,覆盖消费互联网和软件、医疗保健、媒体和娱乐、金融服务。
英伟达表示,DGX Cloud是一项月租服务,允许客户通过云快速设置大型多节点训练工作负载,从而减少大型模型的训练和开发时间。
英伟达称,美国制药公司安进(Amgen)正在使用DGX Cloud以及英伟达的BioNeMo大型语言模型来加速药物发现。
安进的数字创新研究加速中心执行主任Peter Grandsard说:借助英伟达的DGX Cloud和BioNeMo,我们的研究人员能够专注于更深层次的生物学,而不必花心思在处理AI基础设施和建立搭建模型。
与此同时,美国数字保险公司CCC Intelligent Services正在使用DGX Cloud加快其财产和意外伤害保险平台的AI模型开发。
英伟达还公布了其新的AI Foundations服务,该服务将允许公司用户根据他们提供的数据构建和运行自己的大型语言和生成式AI模型。到目前为止,英伟达表示包括Adobe、Getty Images、晨星、Quantiphi和Shutterstock等知名企业正在使用这一新平台构建AI模型。例如,Adobe正在使用该软件构建图像和视频的生成式AI模型,最终将嵌入到Photoshop、Premiere Pro和After Effects等软件中。
本文内容选编于腾讯科技&甲子光年,阅读原文请点击
https://mp.weixin.qq.com/s/F9Hb75mi3WlzQ5OYSdKbxA
https://mp.weixin.qq.com/s/uxvxChC9oaqxwUdXuTXc0w
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢