

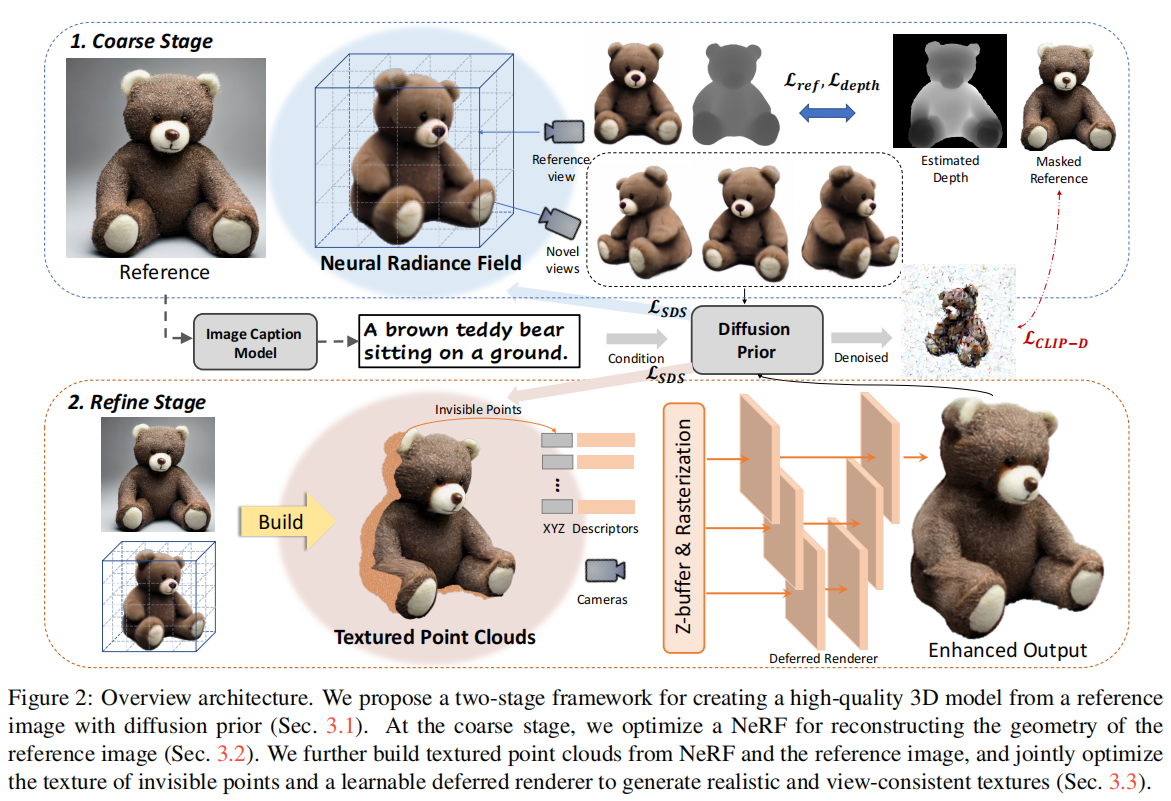
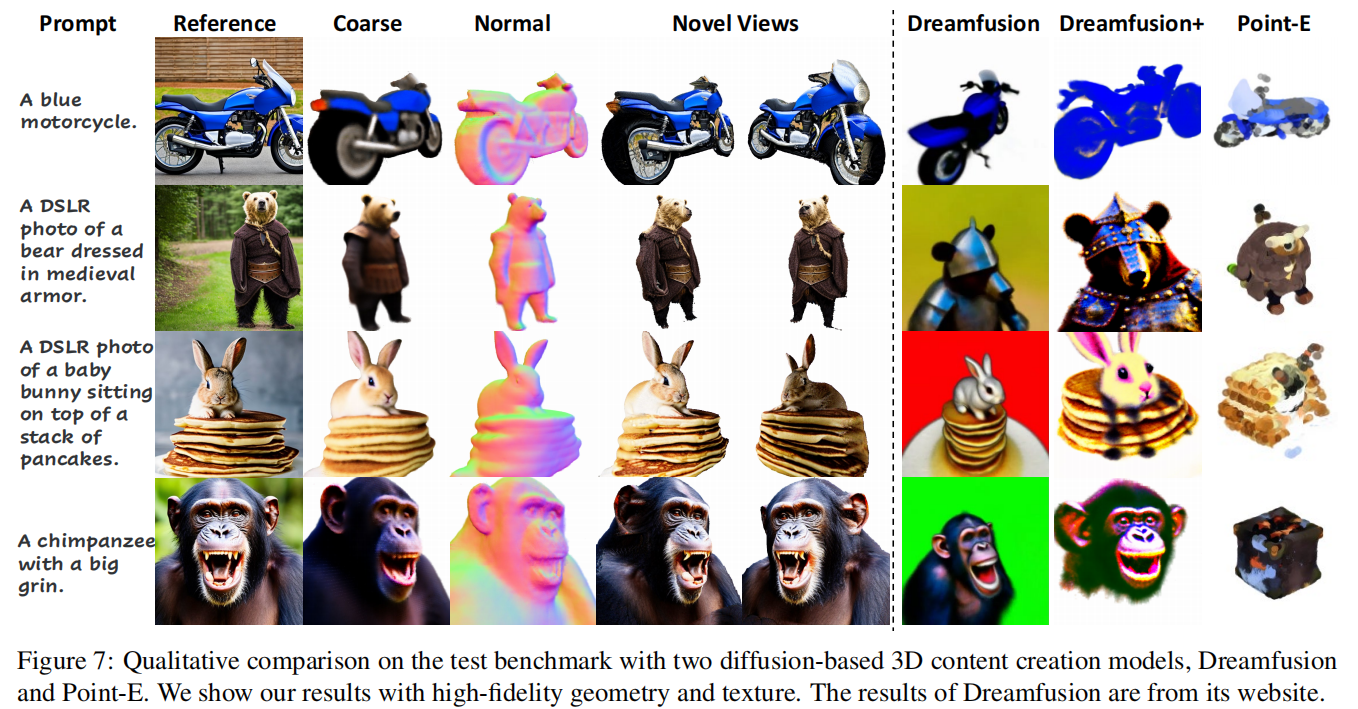
本文探讨了仅凭一张单独的图像创建高保真3D内容的问题。这本质上是一个具有挑战性的问题:它涉及到在同步幻觉未见纹理的同时估计潜在的3D几何形状。为了解决这个挑战,作者利用来自经过充分训练的2D扩散模型的先验知识,作为3D创建的3D感知监督。Make-It-3D采用了两阶段的优化流程:第一阶段通过在前视图中融入参考图像的约束和在新视图中使用扩散先验来优化神经辐射场;第二阶段将粗糙模型转化为纹理点云,并利用参考图像的高质量纹理和扩散先验进一步提高真实感。大量实验证明,Make-It-3D在精准重建和印象深刻的视觉质量方面都优于先前的工作。本文的方法是首次尝试实现从单个图像创建通用物体的高质量3D内容,并实现了各种应用,如文本转3D创建和纹理编辑。
标题:Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Pri
作者:Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, Dong Chen
论文:
https://papers.labml.ai/api/v1/redirect/pdf?paper_key=c5235c9ccc3f11edb95839eec3084ddd
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢