
【推荐理由】文本到图像扩散模型具有出色的生成能力。它们所捕捉的表示知识尚未完全理解,并且尚未在下游任务上进行彻底的探索。本文提出了一种方法来评估扩散模型作为零样本分类器。
Text-to-Image Diffusion Models are Zero-Shot Classifiers
[Google Research]
【论文链接】https://arxiv.org/pdf/2303.15233.pdf
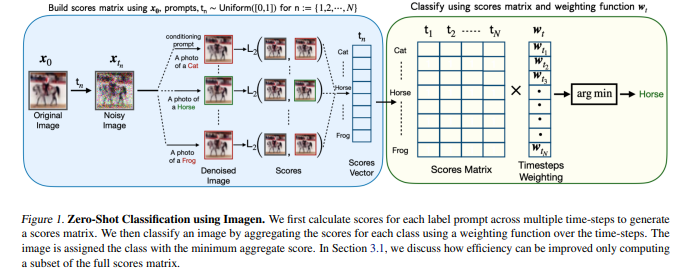
【摘要】文本到图像扩散模型具有出色的生成能力,这表明它们学习了图像-文本数据的信息表示。然而,它们的表示捕捉到的知识尚未完全理解,并且它们在下游任务中尚未得到全面探索。本文通过提出一种方法来评估扩散模型作为零样本分类器。关键思想是使用扩散模型根据标签的文本描述去噪一张带噪声的图像的能力作为该标签的可能性的代理。作者将这种方法应用于Imagen,用它来探索Imagen的知识的细粒度方面,并与CLIP的零样本能力进行比较。Imagen在广泛的零样本图像分类数据集上表现出与CLIP相当的竞争力。此外,它在形状/纹理偏差测试上取得了最先进的结果,并且可以成功地执行属性绑定,而CLIP不能。虽然生成预训练在NLP中很普遍,但视觉基础模型通常使用其他方法,如对比学习。根据作者的发现,本文认为生成预训练应该被探索作为视觉和视觉语言问题的一个有吸引力的替代方法。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢