

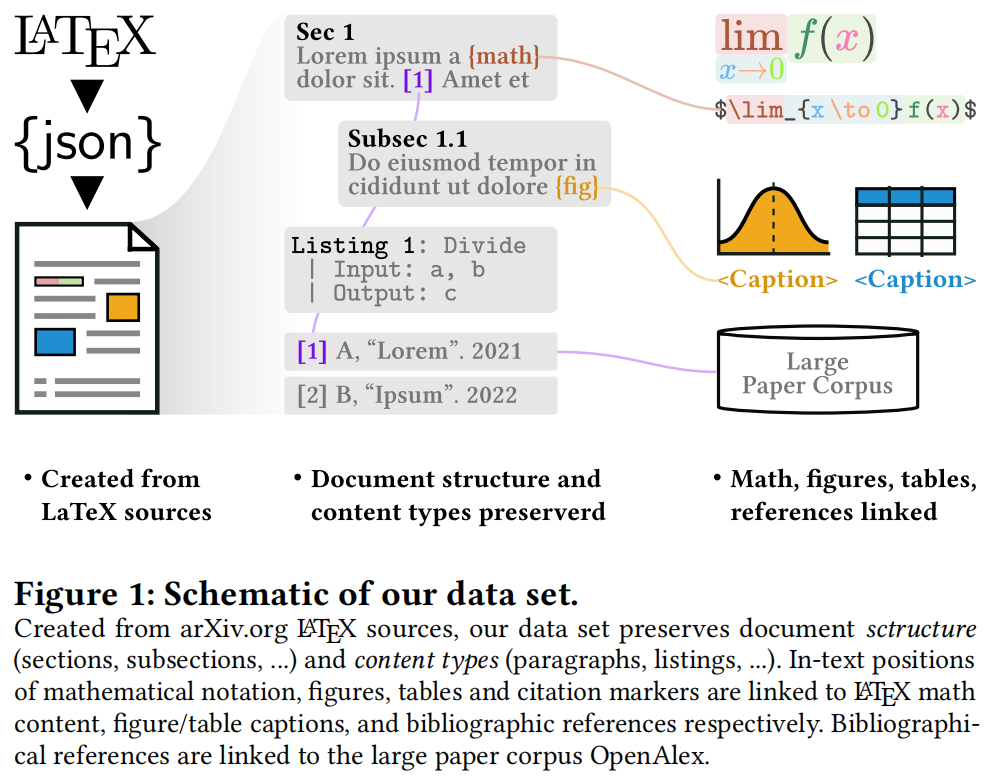
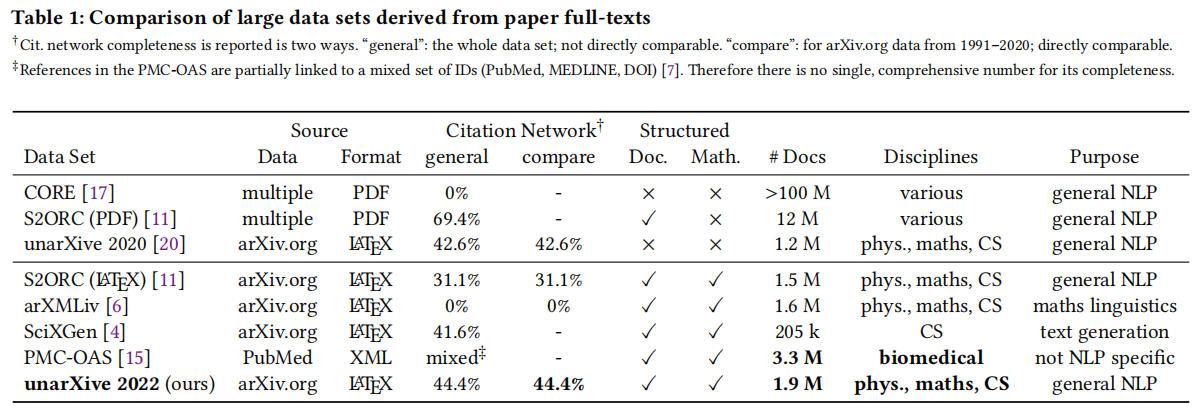
学术出版物的大规模数据集是进行各种文献计量分析和自然语言处理(NLP)应用的基础。特别是最近从全文派生的数据集已经引起了广泛的关注。虽然已经存在一些这样的数据集,但我们认为在领域和时间覆盖、引文网络完整性和全文内容表示方面存在关键的缺陷。为了解决这些问题,我们提出了一个新版本的数据集unarXive。我们基于两个现有数据集的数据处理流程和输出格式,并在每个数据集上进行了改进。我们的结果数据集包括1.9 M篇跨越多个学科和32年的出版物。它比以前的数据集具有更完整的引文网络,并保留了更丰富的文档结构表示以及数学符号等非文本出版内容。除了数据集外,我们还提供了可供引文推荐和IMRaD分类使用的即用型训练/测试数据。
标题:unarXive 2022: All arXiv Publications Pre-Processed for NLP, Including Structured Full-Text and Citation Network
作者:Tarek Saier, Johan Krause, Michael Färber
论文:https://papers.labml.ai/api/v1/redirect/pdf?paper_key=b0b05814cd0711edb95839eec3084ddd
代码:https://github.com/IllDepence/unarXive
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢