
随着百度文心一言、ChatGPT、GPT4等先进技术的问世,我们或许是历史上首次深刻意识到机器智能已经走到了一个临界点,未来的增长曲线或许会变得非常陡峭。
大家所看到类似ChatGPT产品的底层算法都是GPT(Generative Pretraining Transformer)。虽然对于GPT的介绍已经很多了,但今天我想探讨一下为什么一个只是预测下一个单词的语言模型能够产生如此好的效果,蕴含如此巨大的智能。
数据压缩是探讨这一问题非常重要的视角,但却很少有中文文章涉及。我最近看到了一篇相关的文章,标题是《ChatGPT是网上所有文本模糊的图片》。文章中提到ChatGPT的参数是对于Web的有损压缩,这种说法虽然不算错,但将GPT技术和有损压缩联系起来,不利于人们深入理解GPT的核心训练任务,即无损地对训练数据集进行压缩(没错,前面说是有损,后面说是无损,我接下来会详细说明)。
这篇文章有一些偏技术,如果你觉得后面的公式太过抽象,只需记住以下三句话即可,这也是本文的核心思想:
1.通用人工智能(AGI)的追求在于更强的泛化能力。泛化能力越强,智能水平越高。
2.压缩就是泛化。对于一个数据集最好的无损压缩,就是对于数据集之外的数据最佳泛化。
3.GPT预测下一个token的训练任务,等同于对训练数据进行无损压缩。GPT是目前最好的数据无损压缩算法,因此具备最强的智能。
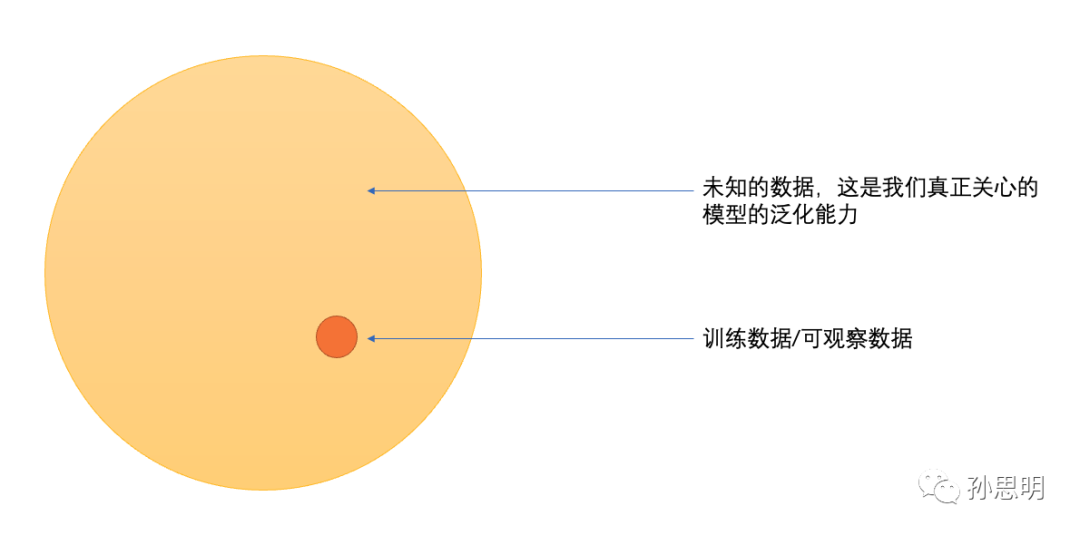
什么是泛化能力?
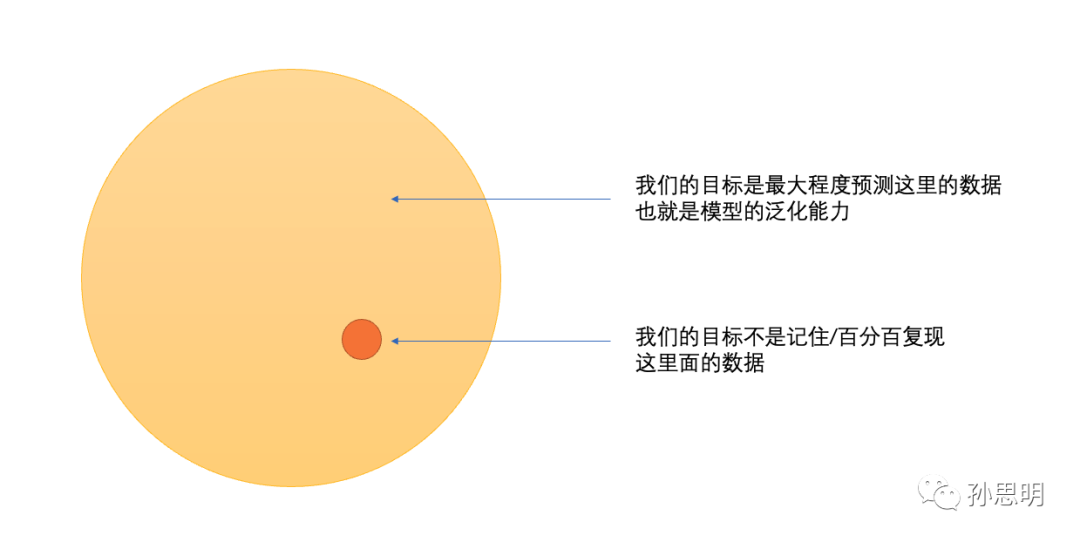
泛化就是从已知推到未知的过程。如图所示,我们关心的核心问题是如何从已经观察到的数据中,了解到关于可观察数据外数据的规律(你也可以理解成分布外数据或者测试数据)。一个模型越能够准确预测黄色部分,它的泛化能力就越强。
对于智能的直观理解
1980年,John Searle提出了一个著名的思想实验《中文房间》。实验过程可以表述如下:
将一个对中文毫无了解,只会说英语的人关在一个只有一个出口的封闭房间里。房间里有一本用英文写成的手册,其中包含了所有可能出现的中文句子及其对应的中文回答。房外的人不断向房间内投递用中文写成的问题,而房间内的人会在手册中找到相应的匹配,并将答案递出房间。

这样一个庞大的手册显然代表着非常低的智能水平,因为一旦遇到手册中没有的词汇,这个人就无法应对了。
如果我们能够从大量的数据中提取出一些语法和规则,那么手册可能会变得更加精简,但是系统的智能水平将会更高(泛化能力更强)。
手册越厚,智能越弱;手册越薄,智能越强。就好像公司雇一个人好像能力越强的人,你需要解释得越少,能力越弱,你需要解释得越多。有没有一种更准确的方式来描述甚至是量化智能呢?
压缩就是通用智能
2000 年,计算机教授Marcus Hutter 证明,找到理性主体的最优行为等同于压缩其观察结果。本质上他证明了奥卡姆剃刀,最简单的答案通常是正确答案。
他在2006年发起了一个竞赛,名叫Hutter Prize,鼓励研究和发展更高效的通用数据压缩算法。该竞赛的目标是设计出一个可以在给定数据集上实现最佳压缩率的通用算法。
他在Hutter Prize的官网上说,
...为了压缩数据,必须找到其中的规律,这本质上是困难的,...能够很好地压缩与智能密切相关...
如果Hutter是对的,那我们就可以通过压缩效率来近似量化模型的智能。
LLM是一种无损的数据压缩器
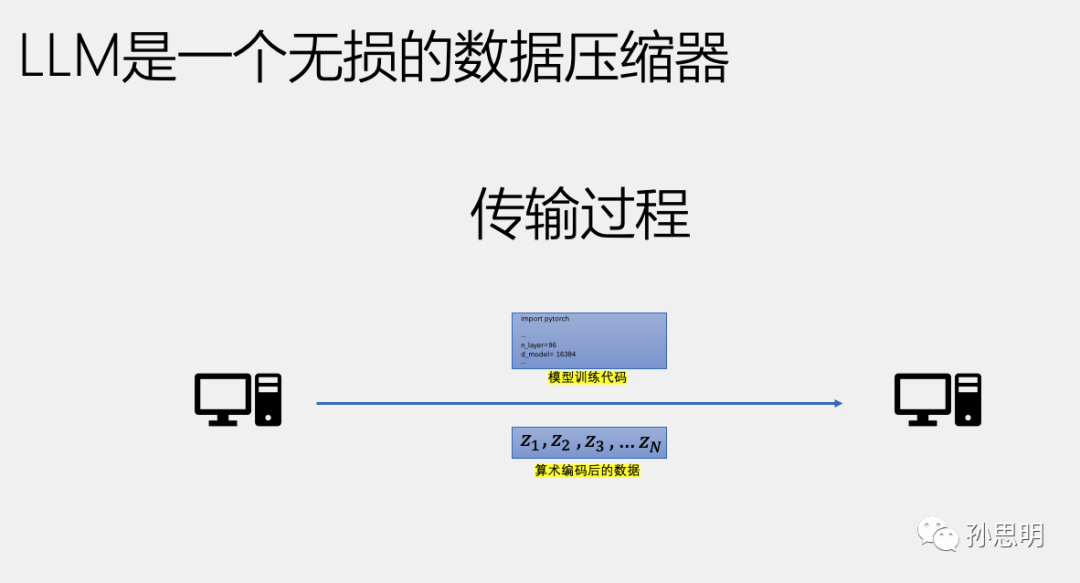
假设你需要将一些数据从遥远的半人马座星系传输回地球,但是带宽非常珍贵,你需要用最少的比特数来传输数据,并且保证另一端可以无损地恢复你的数据。你可以采用以下方法:
首先,准备一个语言模型的训练代码,每次运行时都会生成相同的神经网络模型(使用相同的种子和超参数等)。
其次,在N条数据上运行训练程序,假设batch_size=1,在t时刻,将在所有token概率分布Pt下的,Xt的概率取出,并使用算术编码将其转换为二进制小数,记为Zt。以此类推,得到一个由Z1,Z2,Z3,...,Zn构成的列表。

如果要在另一端无损地还原这N条数据,只需传输以下两个内容:
-
Z1-Zn的列表。
-
语言模型训练代码。
在接收端进行解码时,我们使用收到的训练代码初始化网络。在时间戳t时刻,模型使用Pt对Zt进行算术解码得到Xt。需要注意的是,t时刻的token概率分布Pt在发送端和接收端是完全一致的。
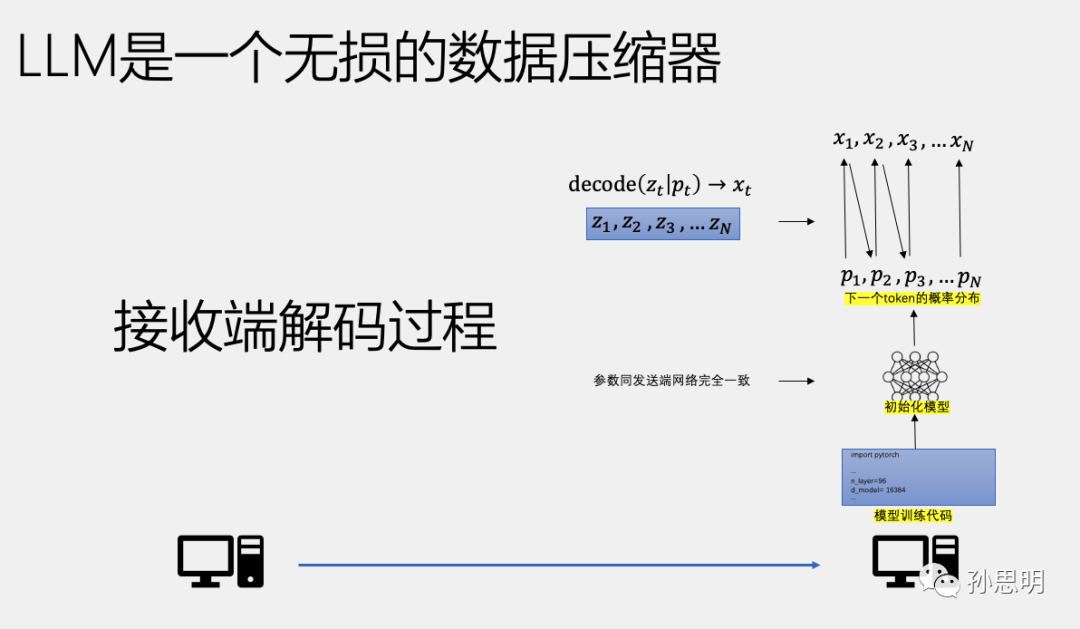
整个过程是一个无损的数据压缩过程,基于语言模型的训练代码,我们将N条数据压缩成了Z1-Zn的一串数字,每个压缩后的数据大小为-logp(x)。需要注意的是,在整个过程中,我们不需要发送整个神经网络(几百上千亿参数)。
因此,使用语言模型来压缩数据集D的总比特数可以表示为以下公式:
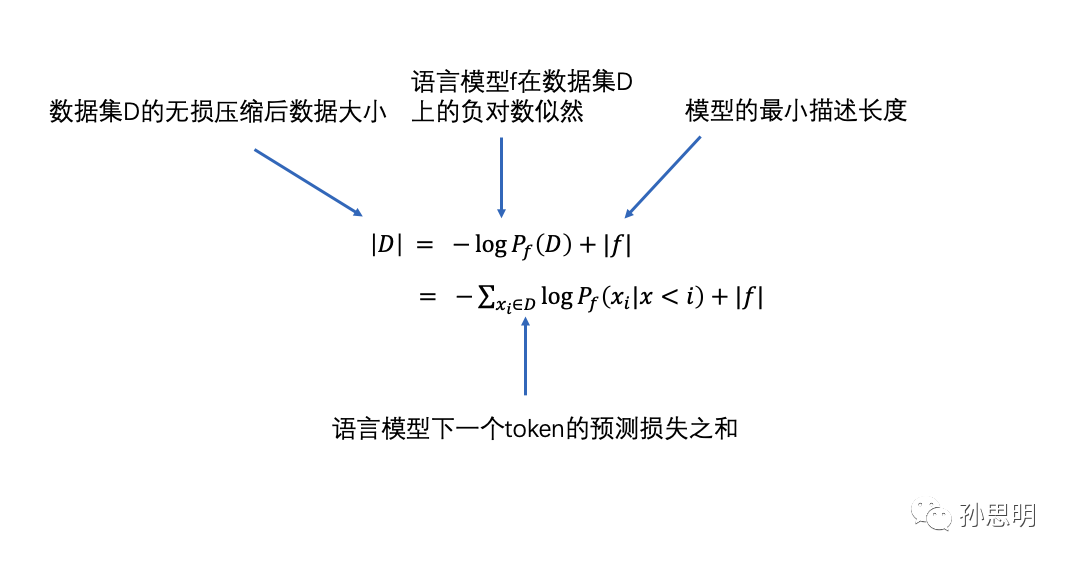
最小描述长度(MDL)是信息论和统计学中的一个原则,在选择模型的时候,要选择具有最小描述长度的模型。最小描述长度的单位是比特,也就是需要多少比特可以来描述模型。这是一个可以精确计算的数值。
一个基于transformer的模型的描述长度大概在100kb ~ 1MB之间(所有必要的代码大小)。模型的参数不属于模型的描述长度。
LLM是目前最好的无损数据压缩器
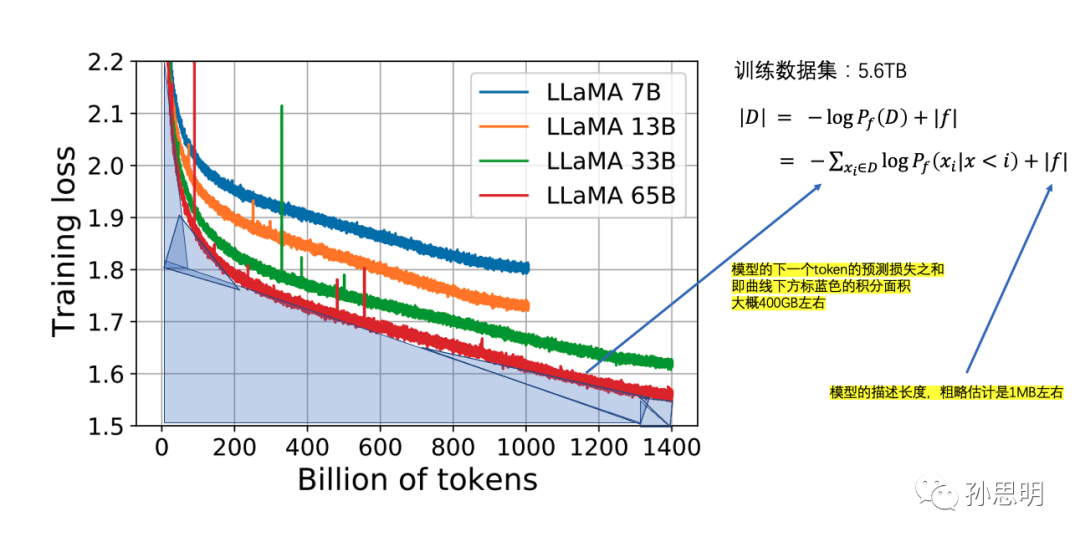
根据LLaMA论文中的数据,我们可以计算出具体的模型压缩比。绿色和红色的两个模型在数据集上只训练了1个epoch,处理的数据量相同,模型的描述长度也相同。语言模型f在数据集D上的负对数似然是训练时下一个token的预测损失之和,也就是曲线下方的积分面积。
计算曲线下面的积分面积得到大约400GB,原始训练数据集的大小是5.6TB,因此整体的压缩比约为14倍 (5.6TB/400GB ~= 14x)。目前在Hutter Prize上最好的无损文本压缩器可以实现8.7倍的压缩,LLM是一个比传统压缩算法更好的无损压缩器。
有损vs无损压缩
我们常常觉得chatgpt在关于事实性问题上错误百出,比如说问他刘慈欣是哪个城市的,模型还是会答错。这是因为在训练过程中,模型慢慢地记住了一些训练数据,模型的参数可以看成是一个对于训练数据的有损数据压缩,但这个损失是非常高的。这也是为什么在回答事实性问题的时候,我们需要搜索引擎来帮忙。
还记得我们开始的那张图吗,我们关心的不是红圈里面的内容,而是黄色的部分,因为我们关心的是泛化,而泛化才是智能。
几乎所有的大语言模型都能看做是某种文本压缩器,包括最早的n-gram,到RNN到Transformer等等。模型的参数量是已知的可以带来更好压缩比的方法,但scale并不是全部,更好的算法模型还有待于发现。
如果我们能找到更好的算法,能够让loss在开始训练的时候可以下降得更快,或者能够更好地处理不同类型的数据,都将极大地加强我们的压缩能力,也就会实现更好的泛化能力。
写在最后
本篇文章参考了OpenAI大语言模型的团队负责人,Jack Rae在Stanford ML Seminar上的分享,这是我近期听到的最好的talk,好久没有感受过的醍醐灌顶的感觉,原本的内容很长,我重新整理了一下思路,提炼出重点内容做了不影响原意的转述,如果你有兴趣的话,还是希望你去看看原本的视频。
MDL包括所罗门诺夫的归纳推理理论都只是领域内的竞争性的理论之一,在OpenAI没有通过ChatGPT一炮而红之前,关于数据压缩理论是否是通往通用人工智能的最佳方案,学界还有很多不同观点。针对于文本进行压缩,是否缺失了很多世界信息,压缩任务能否帮助到人类关心的任务(总结、分类、推理等等),压缩理论针对于图像其它模态效率很低等问题,也一直存在疑问。ChatGPT的成功也让这个理论在接下来会受到更多人的关注,理解和运用这些理论并不难,但是在不同思路中,如何慧眼独具地看到transformer作为一个通用计算引擎对于压缩数据任务的帮助,并且坚信更好的压缩比可以带来更大的智能,这反映了团队的学术眼光和品味。
Reference
-
Compression for AGI - Jack Rae | Stanford MLSys #76
https://www.youtube.com/@StanfordMLSysSeminars
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢