

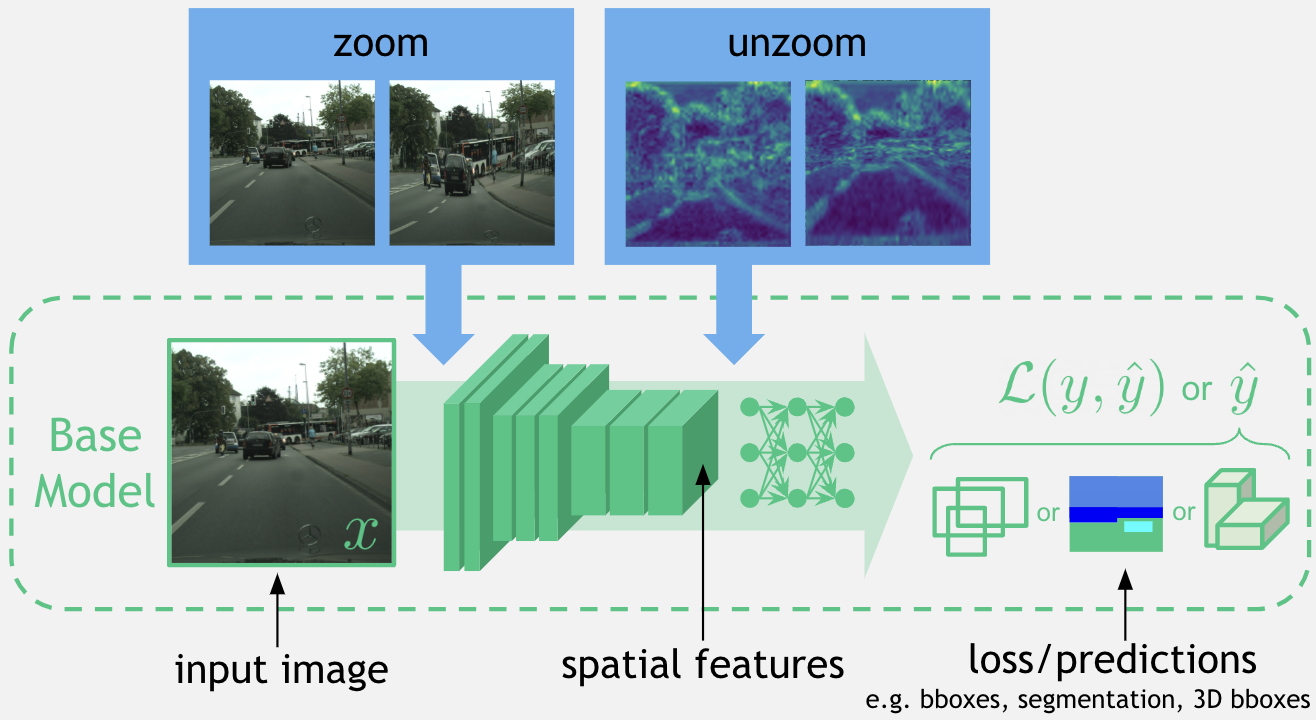
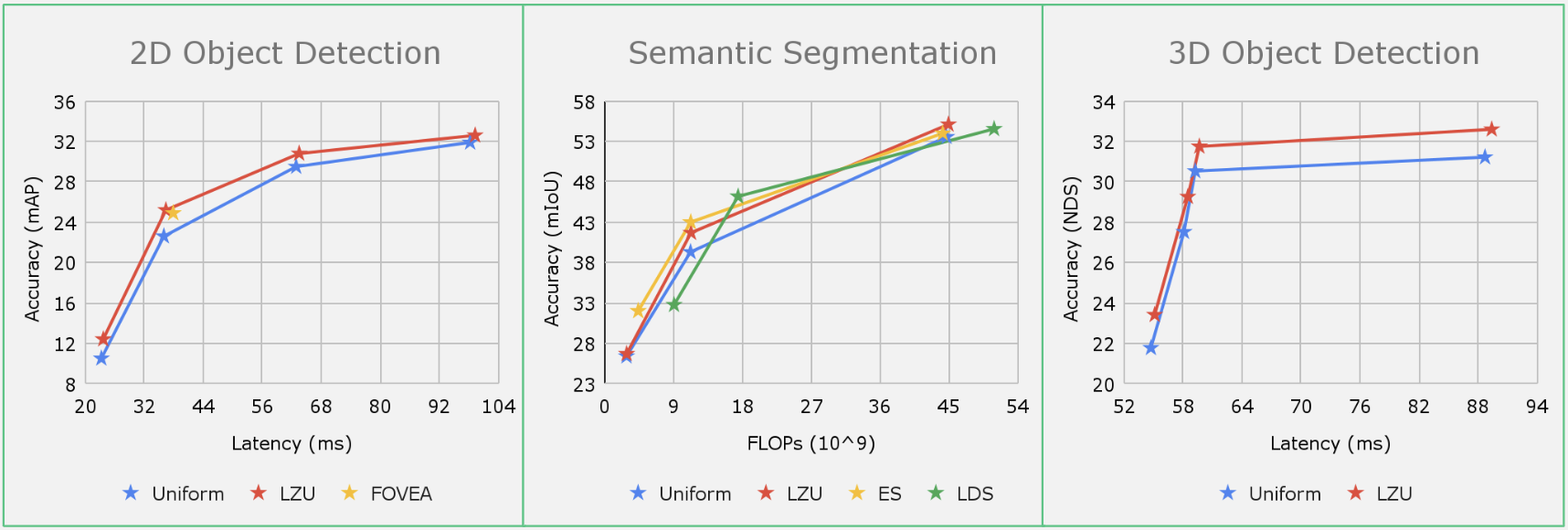
移动计算、自主导航和AR/VR中的许多感知系统都面临着严格的计算限制,尤其是对于高分辨率输入图像的挑战。先前的作品提出了非均匀下采样器,可以“学习聚焦”于显著的图像区域,从而减少计算量,同时保留任务相关的图像信息。然而,对于具有空间标签的任务(如2D/3D物体检测和语义分割),这种扭曲可能会损害性能。在这项/工作中,本文“学习聚焦”于输入图像,计算空间特征,然后“反聚焦”以恢复任何形变。为了实现高效和可微分的反聚焦,本文使用分段双线性映射近似缩放变形,并保证其可逆性。LZU可以应用于具有2D空间输入的任何任务和具有2D空间特征的任何模型,并通过在不同任务和数据集上的评估证明了其多功能性:Argoverse-HD6上的物体检测、Cityscapes5上的语义分割以及NuScenes4上的单目3D物体检测。有趣的是,当高分辨率传感器数据不可用时,本文观察到性能提升,这意味着LZU也可以用于“学习上采样”。
标题:Learning to Zoom and Unzoom
作者:Chittesh Thavamani,Mengtian Li,Francesco Ferroni,Deva Ramanan
论文:https://arxiv.org/abs/2303.15390
代码:https://tchittesh.github.io/lzu/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢