
作者:Nolan Dey,研究科学家;Joel Hestness,首席研究科学家;Sean Lie,首席硬件架构师和联合创始人贡献作者:Nolan Dey、Gurpreet Gosal、Charles Chen、Hemant Khachane、William Marshall、Ribhu Pathria、Marvin Tom、Joel Hestness。
位于加利福尼亚州桑尼维尔的初创公司得到了超过7.2亿美元的风险投资支持。该公司出售一种名为WSE-2的芯片,专为运行人工智能软件而设计。WSE-2位于经过优化运行人工智能应用程序的Cerebras Andromeda超级计算机的核心,拥有超过1350万个处理器内核。
人工智能芯片制造商Cerebras Systems Inc.今天宣布,它已经训练并发布了七个基于GPT的生成人工智能大型语言模型,使其可供更广泛的研究社区使用。Cerebras开放了从1.11亿到130亿参数的七个GPT-3模型。使用Chinchilla公式训练,这些模型为准确性和计算效率设定了新的基准。
该公司表示与现有的任何可用的LLM相比,他们的训练时间更短,成本更低,能耗更低,且已开源。
这是Cerebras希望在今天的发布中解决的问题。它开源了七个GPT模型,有1.16亿、2.56亿、5.9亿、13亿、27亿、67亿和130亿参数,在GitHub和Hugging Face上提供。训练这些模型通常需要几个月的时间,但Cerebras表示,仙女座的Cerebras CS-2系统的速度,加上独特的重量流架构,有助于将这一时间缩短到几周。
官网地址:
https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models
GPT地址:https://www.cerebras.net/cerebras-gpt
Hugging Face地址:https://huggingface.co/cerebras

新的LLM值得注意,因为它们是第一个在仙女座人工智能超星系团中使用CS-2系统进行训练的,该超星系团由专门为运行AI软件而设计的Cerebras WSE-2芯片提供动力。换句话说,他们是第一批在不依赖基于图形处理单元的系统的情况下接受的大模型之一。
Cerebras表示,它不仅通过标准的Apache 2.0许可证共享模型,还共享使用的重量和训练配方。
Cerebras联合创始人兼首席软件架构师Sean Lie表示 “向开源社区发布七个经过全面训练的GPT模型,表明Cerebras CS-2系统的集群是多么高效,以及它们如何快速解决最大规模的人工智能问题——这些问题通常需要数百或数千个GPU。”
该公司解释说,由于Cerebras LLM是开源的,它们可用于研究和商业目的。它们还提供了一些好处,他们的训练权重产生了一个极其准确的预训练模型,该模型可以用少量的自定义数据针对不同的任务进行微调,使任何人都可以以最小的努力构建一个强大的、可生成的人工智能应用程序。
该版本还展示了Cerebras所谓的“简单、数据并行的方法”的有效性。在传统的GPU LLM中,需要管道、模型和数据并行技术的复杂融合。然而,Cerebras的重量流架构展示了如何通过更简单、仅数据并行的模型来完成,该模型不需要代码或模型修改即可扩展到非常大的模型。
Cambrian AI的分析师Karl Freund表示,今天的发布不仅展示了Cerebras的CS-2系统作为首屈一指的人工智能平台的能力,而且还将该公司提升到人工智能从业者的上层。
Freund说:“世界上有少数公司能够部署端到端的人工智能基础设施,并最大的大模型,以达到最先进的准确性。”“Cerebras现在必须算在其中。此外,通过使用允许的Apache 2.0许可证将这些模型发布到开源社区,Cerebras表明致力于确保人工智能仍然是一项广泛造福人类的开放技术。”
以下官网博客(机器翻译)
原文为:https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models
摘要
最先进的语言模型的极具挑战性;它们需要巨大的计算预算、复杂的分布式计算技术和深厚的ML专业知识。因此,很少有组织从头开始大型语言模型(LLM)。越来越多的那些拥有资源和专业知识的人没有开源结果,这标志着与几个月前相比发生了重大变化。
在Cerebras,我们相信促进对最先进的模型的开放访问。考虑到这一点,我们很自豪地宣布向Cerebras-GPT的开源社区发布,这是一个由七个GPT模型组成的系列,参数从1.11亿到130亿不等。使用Chinchilla公式训练,这些模型为给定的计算预算提供了最高的准确性。与迄今为止任何公开可用的模型相比,Cerebras-GPT的训练时间更快,成本更低,能耗更低。
所有模型都在CS-2系统上进行训练,这些系统是仙女座人工智能超级计算机的一部分,使用我们简单的数据并行权重流架构。通过不必担心模型分区,我们能够在短短几周内训练这些模型。训练这七个模型使我们能够推导出一个新的缩放定律。缩放定律根据计算预算预测模型准确性,并对指导人工智能研究产生了巨大影响。据我们所知,Cerebras-GPT是第一个预测公共数据集模型性能的缩放定律。
今天的发布旨在供任何人使用和重现。在Apache 2.0许可证下,所有模型、权重和检查点都可以在Hugging Face和GitHub上使用。此外,我们在即将发布的论文中提供了有关我们的方法和绩效结果的详细信息。用于的Cerebras CS-2系统也可以通过Cerebras Model Studio按需提供。
Cerebras-GPT:开放式LLM开发的新模式
人工智能具有改变世界经济的潜力,但其访问越来越封闭。最新的大型语言模型——OpenAI的GPT4——发布时没有关于其模型架构、训练数据、训练硬件或超参数的信息。公司越来越多地使用封闭数据集构建大型模型,并仅通过API访问提供模型输出。
为了使LLM成为一种开放和可访问的技术,我们认为访问最先进的模型很重要,这些模型对于研究和商业应用都是开放的、可重现的和免版税的。为此,我们使用我们称之为Cerebras-GPT的最新技术和开放数据集训练了一个变压器模型系列。这些模型是第一个使用Chinchilla公式训练并通过Apache 2.0许可证发布的GPT模型系列。

大型语言模型可以大致分为两个阵营。第一组包括OpenAI的GPT-4和DeepMind的Chinchilla等模型,这些模型根据私人数据进行了训练,以实现最高级别的准确性。然而,这些模型的训练有素的重量和源代码不向公众开放。第二组包括Meta的OPT和Eleuther的Pythia等模型,这些模型是开源的,但没有以计算优化的方式进行训练。
通过“计算最优”,我们指的是DeepMind的发现,当模型中的每个参数使用20个数据令牌时,大型语言模型可以实现固定计算预算的最高准确性。因此,应在200亿数据令牌上训练10亿参数模型,以达到固定预算的最佳结果。这有时被称为“Chinchilla食谱”。
这一发现的一个含义是,在训练模型大小家族时,使用相同数量的训练数据不是最佳的。例如,训练一个数据过多的小模型会导致回报递减,每个FLOP的准确性收益降低——最好使用数据较少的较大模型。相比之下,一个用太少的数据训练的大型模型没有发挥其潜力——最好缩小模型大小并为其提供更多数据。在每种情况下,根据Chinchilla食谱,每个参数使用20个令牌是最佳的。
EleutherAI的Pythia开源模型套件对研究社区非常有价值,因为它在受控的训练方法下使用公共桩数据集提供了广泛的模型大小。然而,Pythia接受了所有模型尺寸的固定数量的令牌训练,目的是在所有模型中提供苹果对苹果的基线。
Cerebras-GPT旨在与Pythia相辅相成,旨在使用相同的公共桩数据集覆盖各种模型尺寸,并建立高效的缩放定律和模型家族。Cerebras-GPT由七个模型组成,具有111M、256M、590M、1.3B、2.7B、6.7B和13B参数,所有这些参数都使用每个参数20个令牌进行训练。通过使用每个模型大小的最佳训练令牌,Cerebras-GPT在所有模型大小中实现了每单位计算的最低损失(图2)。
新的缩放法
大型语言模型可能是一个昂贵且耗时的过程。它需要大量的计算资源和专业知识来优化模型的性能。解决这一挑战的一种方法是训练不同大小的模型家族,这可以帮助建立描述训练计算和模型性能之间关系的缩放定律。
缩放定律对LLM开发至关重要,因为它们允许研究人员在前预测模型的预期损失,从而避免昂贵的超参数搜索。OpenAI是第一个建立缩放定律,显示计算和模型损失之间的幂定律关系。DeepMind随后进行了Chinchilla研究,展示了计算和数据之间的最佳比例。然而,这些研究是使用封闭数据集进行的,这使得它们很难将结果应用于其他数据集。
Cerebras-GPT通过建立基于开放桩数据集的缩放定律来继续这一研究。由此产生的缩放定律为使用Pile训练任何规模的LLM提供了一个计算高效的配方。通过发布我们的发现,我们希望为社区提供宝贵的资源,并进一步推进大型语言模型的开发。
下游任务的模型性能
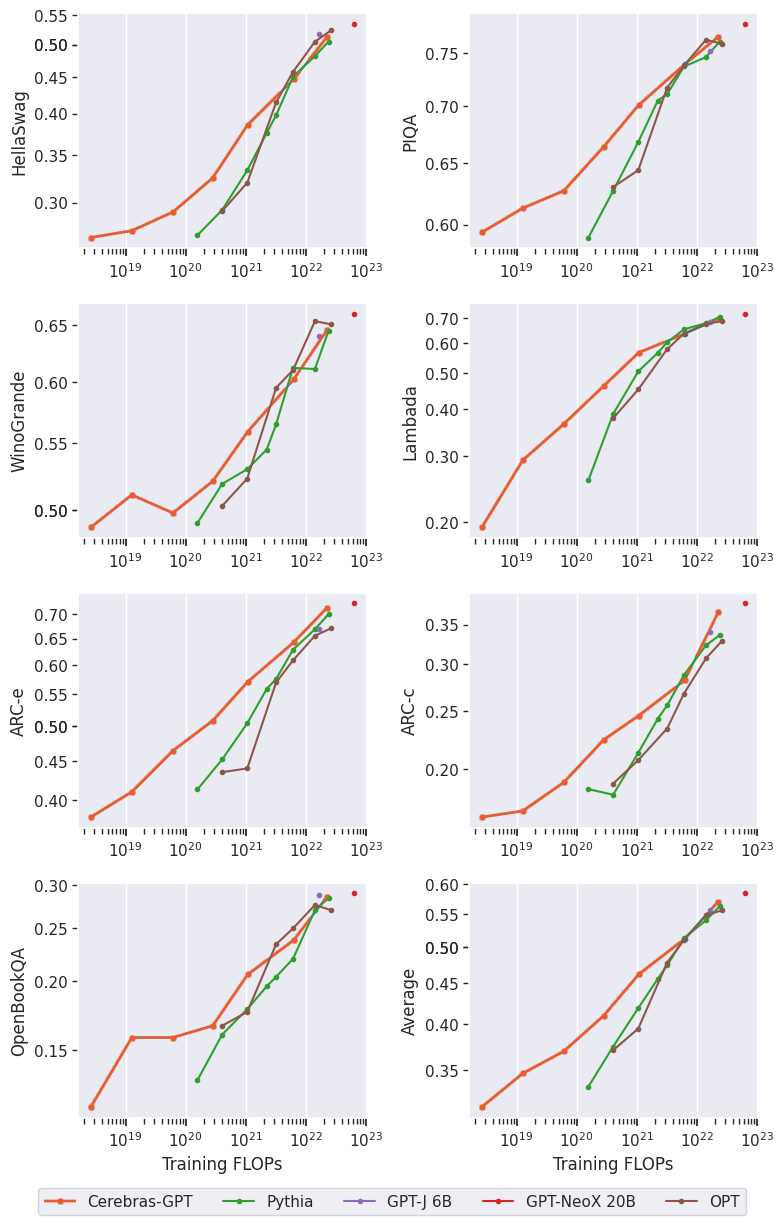
我们评估了Cerebras-GPT在几项特定语言任务上的表现,如句子完成和问答。这些很重要,因为即使模型可能具有良好的自然语言理解,但可能不会转化为专门的下游任务。我们表明,Cerebras-GPT为最常见的下游任务保留了最先进的效率,如图4中的示例所示。值得注意的是,虽然以前的缩放法显示了训练前损失的缩放,但这是首次发布结果,显示下游自然语言任务的缩放。
Cerebras CS-2:简单、数据并行训练
在GPU上训练非常大的模型需要大量的技术专业知识。在最近发布的GPT-4技术报告中,OpenAI仅为计算基础设施和扩展而归功于30多名贡献者。为了理解原因,我们将看看图5所示的GPU上现有的LLM缩放技术。
最简单的扩展方法是数据并行。数据并行缩放在每个设备中复制模型,并在这些设备上使用不同的训练批次,平均其梯度。显然,这并不能解决模型大小的问题——如果整个模型不适合单个GPU,它就会失败。
一个常见的替代方法是流水线模型并行,它作为流水线在不同的GPU上运行不同的层。然而,随着管道的增长,激活内存随着管道深度的平方增加,这对大型模型来说可能令人望而却步。为了避免这种情况,另一种常见的方法是跨GPU拆分层,称为张量模型并行,但这在GPU之间强加了重要的通信,这使实现复杂化,并且可能很慢。
由于这些复杂性,今天没有一种在GPU集群上扩展的单一方法。在GPU上训练大型模型需要具有各种形式的并行性的混合方法;实现复杂且难以提出,并且存在重大的性能问题
最近的两个大型语言模型说明了在许多GPU上拆分大型语言模型所涉及的复杂性(图6)。Meta的OPT模型,从125M到175B参数,在992个GPU上进行了训练,使用了数据并行性和张量并行性的组合以及各种内存优化技术。Eleuther的20B参数GPT-NeoX使用组合数据、张量和管道并行性来训练96个GPU的模型。

我们在名为仙女座的16x CS-2 Cerebras Wafer-Scale集群上训练了所有Cerebras-GPT模型。该集群使所有实验都能快速完成,而无需GPU集群所需的传统分布式系统工程和模型并行调优。最重要的是,它使我们的研究人员能够专注于ML的设计,而不是分布式系统。我们相信轻松训练大型模型的能力是广泛社区的关键推动因素,因此我们通过Cerebras AI Model Studio在云上提供了Cerebras Wafer-Scale Cluster。
结论
在Cerebras,我们认为大型模型的民主化既需要解决基础设施挑战,也需要向社区开放更多模型。为此,我们设计了带有按钮缩放的Cerebras Wafer-Scale集群,我们正在开源Cerebras-GPT系列的大型生成模型。我们希望,作为第一个具有最新效率的公共大型GPT模型套件,Cerebras-GPT将作为高效的秘诀和进一步社区研究的参考。此外,我们正在通过Cerebras AI Model Studio在云上提供基础设施和模型。我们相信,通过更好的基础设施和更多的社区共享,我们可以一起进一步推进大型生成性人工智能行业。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢