
【推荐理由】本文结合了经典网络Inception和 ConvNext并提出的InceptionNeX。该网络能够作为新的CNN基准,加速神经架构设计的研究。
InceptionNeXt: When Inception Meets ConvNeXt
Weihao Yu, Pan Zhou, Shuicheng Yan, Xinchao Wang
[National University of Singapore & Sea AI Lab]
【论文链接】https://arxiv.org/pdf/2303.16900.pdf
【项目链接】https://github.com/sail-sg/inceptionnext
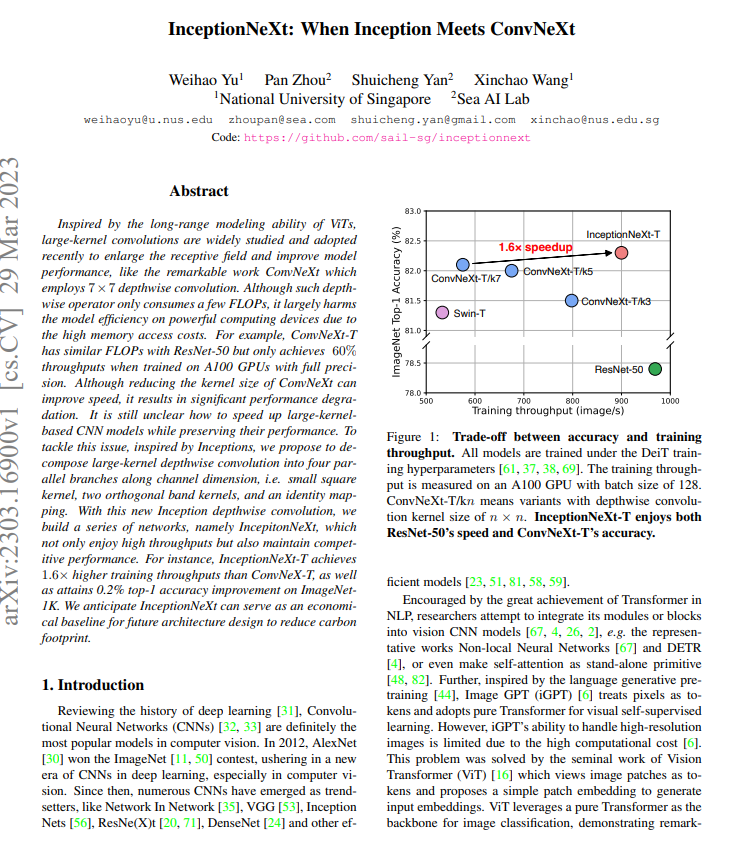
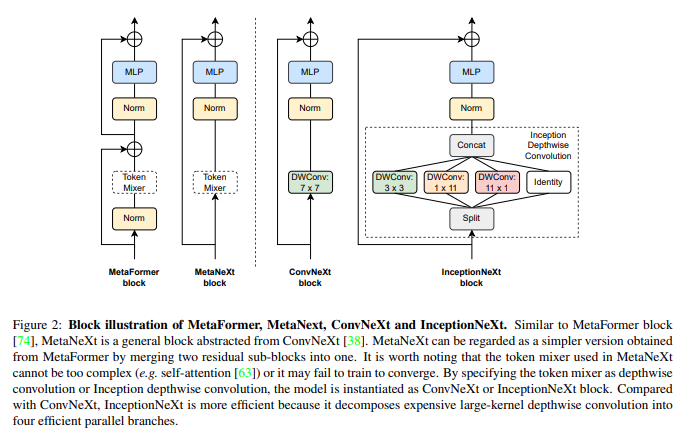
【摘要】受到ViT长距离建模能力的启发,大卷积核被广泛研究和采用,以扩大感受野并提高模型性能,例如使用7×7深度卷积的ConvNeXt。虽然这种深度卷积算子只消耗少量的FLOPs,但由于高内存访问成本,它在强大的计算设备上大大损害了模型效率。例如,ConvNeXt-T在全精度A100 GPU上训练时与ResNet-50具有相似的FLOPs,但仅实现了60%的吞吐量。虽然减小ConvNeXt的卷积核大小可以提高速度,但会导致显著的性能下降。如何在保持性能的同时加速基于大卷积核的CNN模型仍然不清楚。为了解决这个问题,受到Inception的启发,本文提出将大卷积核深度卷积分解为沿通道维度的四个并行分支,即小方形卷积核、两个正交带状卷积核和一个恒等映射。通过这种新的Inception深度卷积,作者构建了一系列网络,即IncepitonNeXt,不仅具有高吞吐量,而且保持竞争性能。例如,InceptionNeXt-T的训练吞吐量比ConvNeX-T高1.6倍,同时在ImageNet1K上获得了0.2%的top-1准确率提高。预计InceptionNeXt可以作为未来架构设计的经济基线,以减少碳足迹。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢