

01 作者信息
02 论文简介
-
让大模型复用(继承)已有小模型中的隐式知识,从而加速大模型的训练 -
提出基于“知识蒸馏”和“参数复用”知识继承框架,充分利用现有小模型消耗的算力 -
知识继承可以很好地加速模型收敛、提高模型性能
03 研究设计
研究思路
-
简单地扩大模型容量、数据大小和训练时间可以显著提升模型性能,然而更多的模型参数也意味着更昂贵的计算资源、训练成本。 -
现有的 PLM 通常是从零开始单独训练,而忽略了许多已训练的可用模型。 -
考虑到人类可以利用前人总结的知识来学习新任务;同样我们可以让大模型复用(继承)已有小模型中的隐式知识,从而加速大模型的训练。
-
“知识蒸馏” 大模型预训练初期,让现有小模型作为大模型的“老师”,将小模型的隐式知识“反向蒸馏”给大模型从而复用现有小模型的能力,减少大模型预训练计算消耗 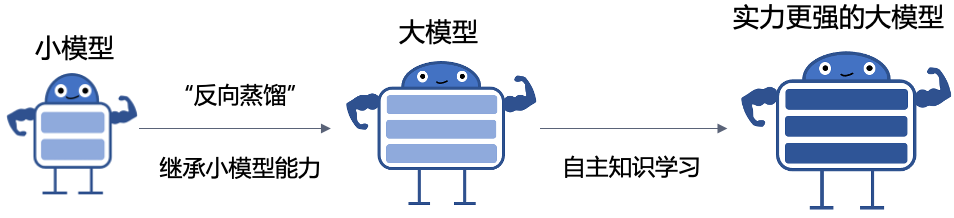
-
“参数复用”
04 实验及结论
知识蒸馏
-
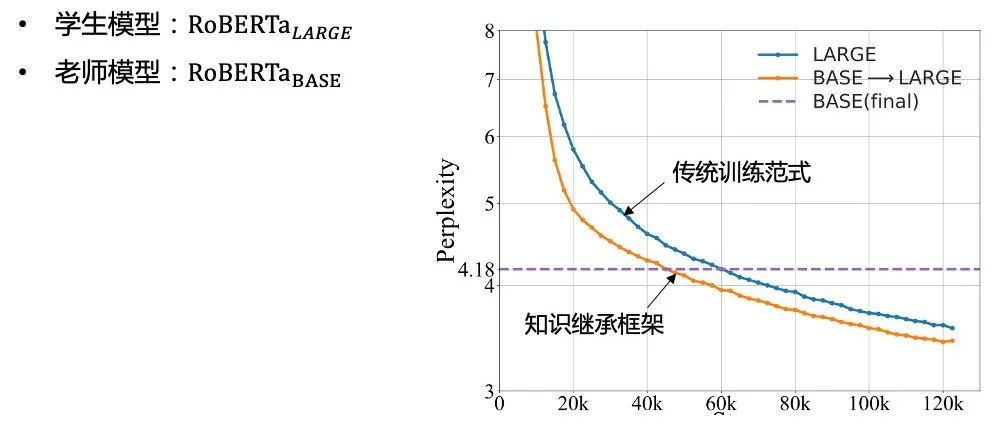
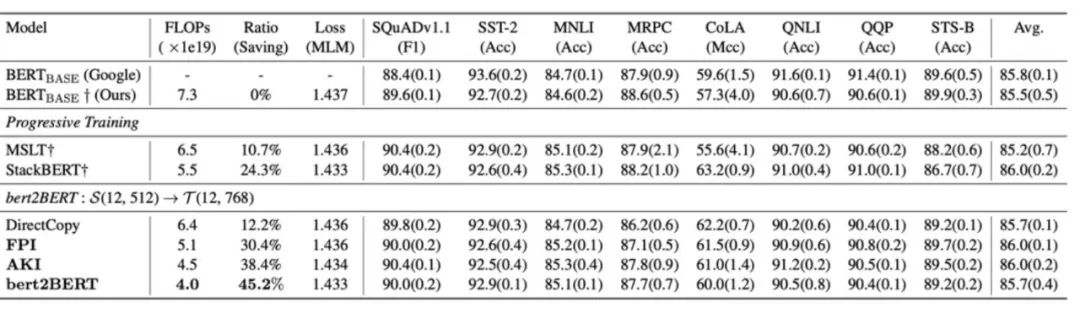
在知识继承框架下大模型预训练收敛速度提升37.5%
-
大模型在下游任务上显著超越传统方法
-
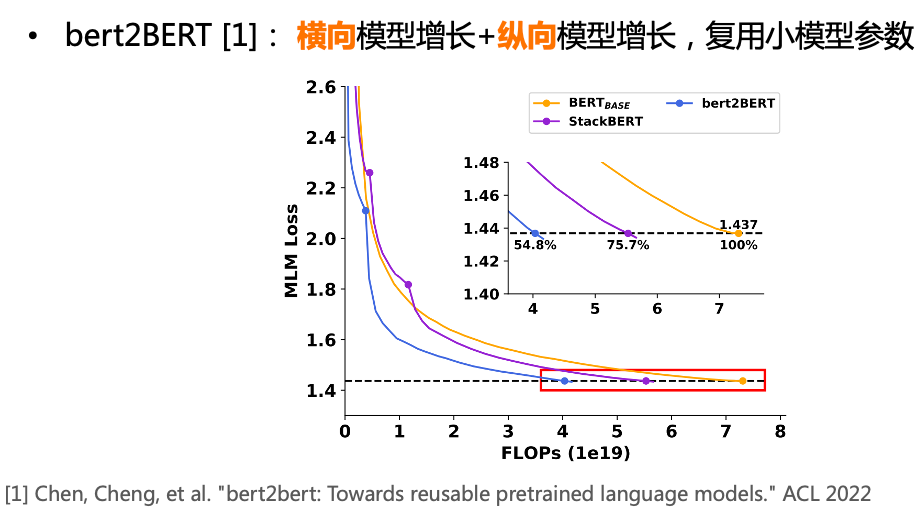
纵向模型增长:参考 StackingBERT,并引入阶段式训练 -
实验结果:
05 方法对比
基于知识蒸馏
-
更加灵活,对模型架构要求较低
-
支持多对一知识继承,不需要得到小模型参数
-
性能提升不及参数复用
基于参数复用
-
比基于知识蒸馏的方法效果更好
-
约束较高,需要得到模型参数,应用场景受限
我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台发送“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !

本期论文速读视频版已发布于 OpenBMB的 B站账号 (视频讲解比文字阅读更加详细易懂哦),欢迎大家观看后 一键三连 !
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢