
Improving Code Generation by Training with Natural Language Feedback
提出一种基于自然语言反馈的仿真学习算法,通过训练时的自然语言反馈来提高代码生成模型的性能。
Angelica Chen, Jérémy Scheurer, Tomasz Korbak, Jon Ander Campos, Jun Shern Chan, Samuel R. Bowman, Kyunghyun Cho, Ethan Perez
[New York University]
通过自然语言反馈训练提高代码生成质量
-
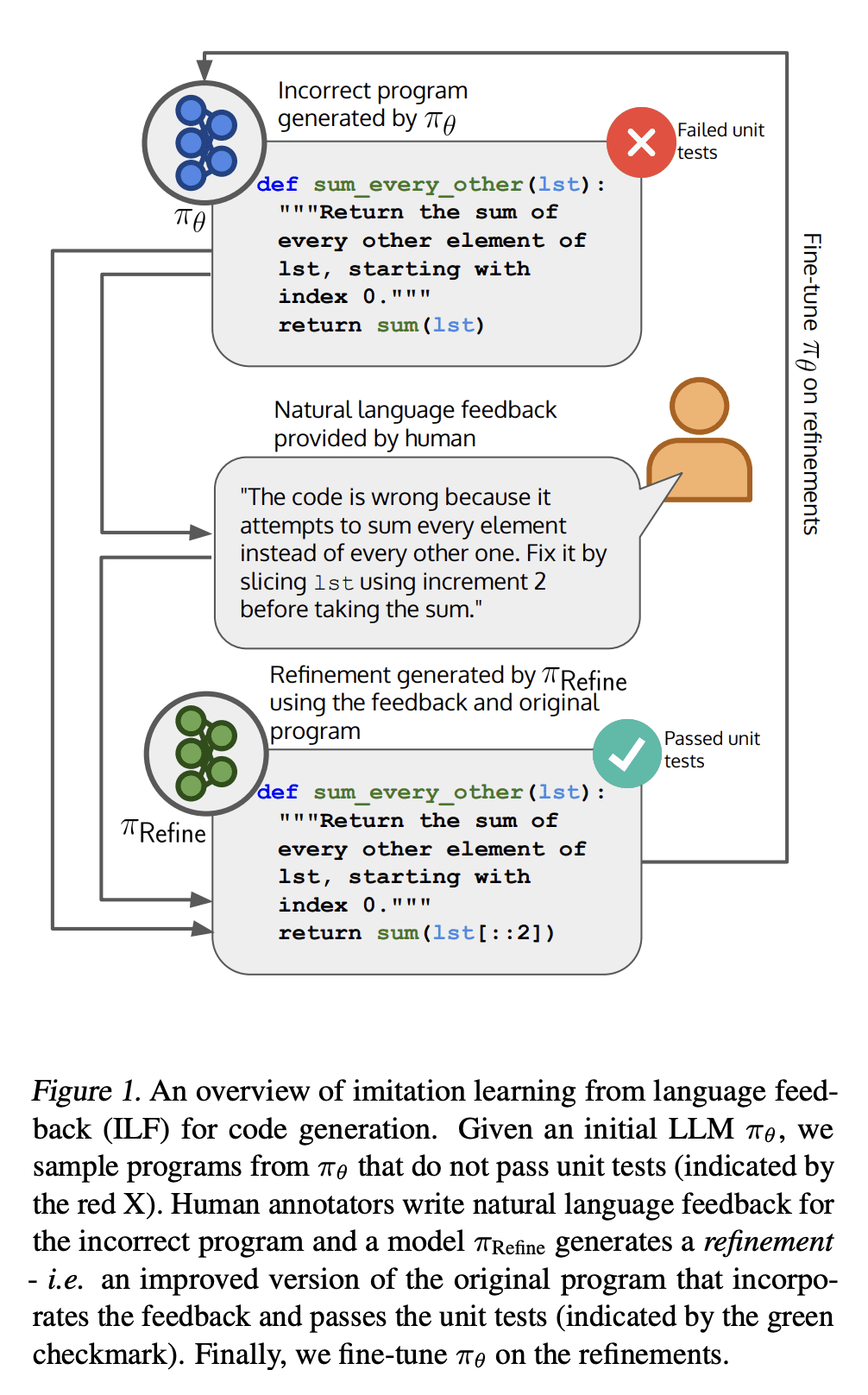
动机:当前大型语言模型(LLM)在推理时使用自然语言反馈的潜力受到广泛关注,本文旨在探索使用自然语言反馈在训练期间提高代码生成模型性能的方法。 -
方法:提出一种名为“基于自然语言反馈的仿真学习(ILF)”算法来学习自然语言反馈,并将其用于代码生成任务。ILF只需要在训练期间使用少量的人工编写的反馈信息,并且在测试时不需要相同的反馈信息,这使其既用户友好又样本高效。 -
优势:该方法证明了使用自然语言反馈来提高代码生成模型的性能是有效的,具有样本高效的优点,并可以连续多轮地改进模型。该方法还可以纠正代码中特定类型的错误,并生成与现实场景更加接近的训练数据。使用ILF方法在基本Python问题上的表现比在MBPP数据集上进行微调或人工编写程序的微调效果更好,相对提高了38%(绝对提高了10%)。
https://arxiv.org/abs/2303.16749

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢