

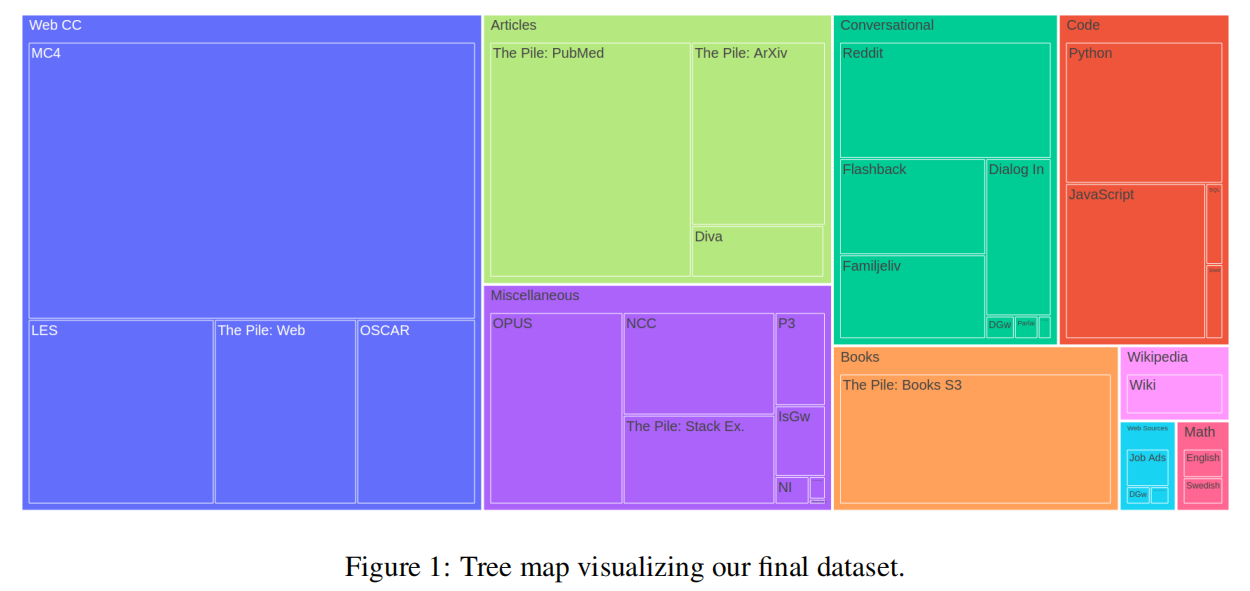
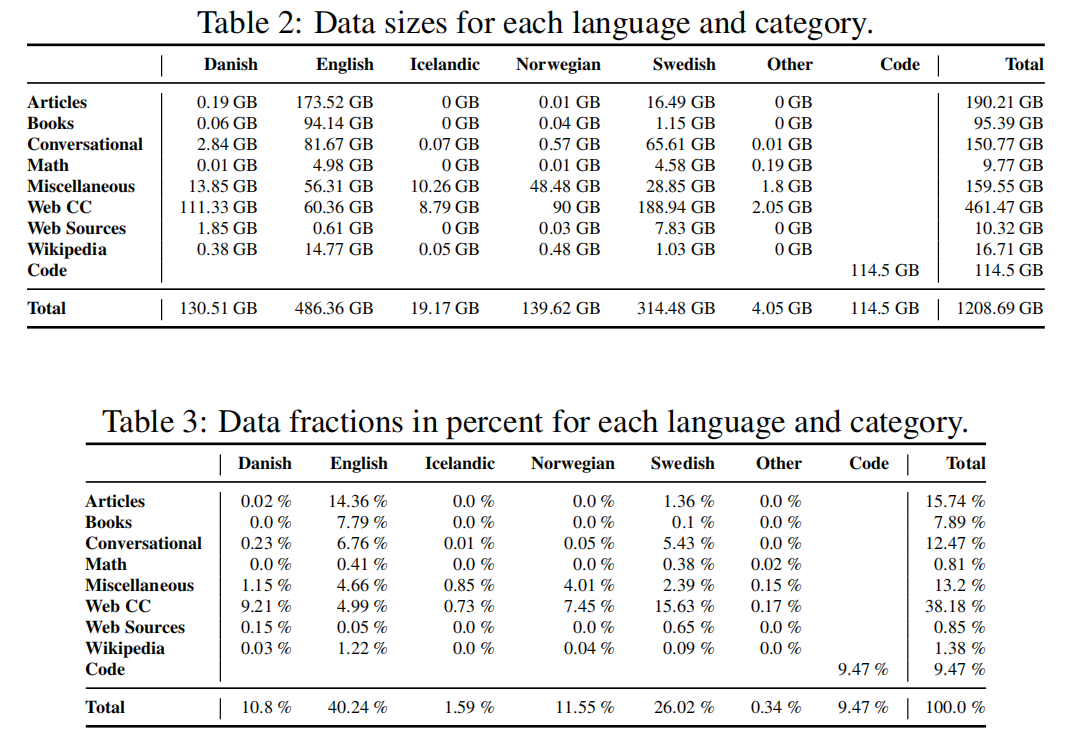
The Nordic Pile是一个来自北欧国家的1.2TB大型文本数据集,旨在用于语言建模研究。该数据集包括来自多个来源的文本,包括新闻文章、书籍和社交媒体。The Nordic Pile数据集对于自然语言处理研究人员尤其有价值,特别是对于那些对北欧地区的语言使用有兴趣的人。由于其规模和多样性,该数据集具有推动语言模型研究、促进更准确的语言处理系统发展的潜力。
标题:The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
作者:Joey Öhman, Severine Verlinden, Ariel Ekgren, Amaru Cuba Gyllensten, Tim Isbister, Evangelia Gogoulou, Fredrik Carlsson, Magnus Sahlgren
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢