

大型语言模型(LLMs)已经在各种任务中展示了令人印象深刻的能力,从而革命了自然语言处理。不幸的是,它们易于出现幻觉,即模型在响应中暴露不正确或虚假信息,这使得必须进行勤奋的评估方法。虽然基于问答(Q&A)数据集通常评估LLM在特定知识领域中的表现,但这种评估通常仅报告整个领域的单个准确性数字,这种程序在透明度和模型改进方面存在问题。分层评估可能会揭示出更容易出现幻觉的子领域,从而有助于更好地评估LLMs的风险并指导它们的进一步发展。
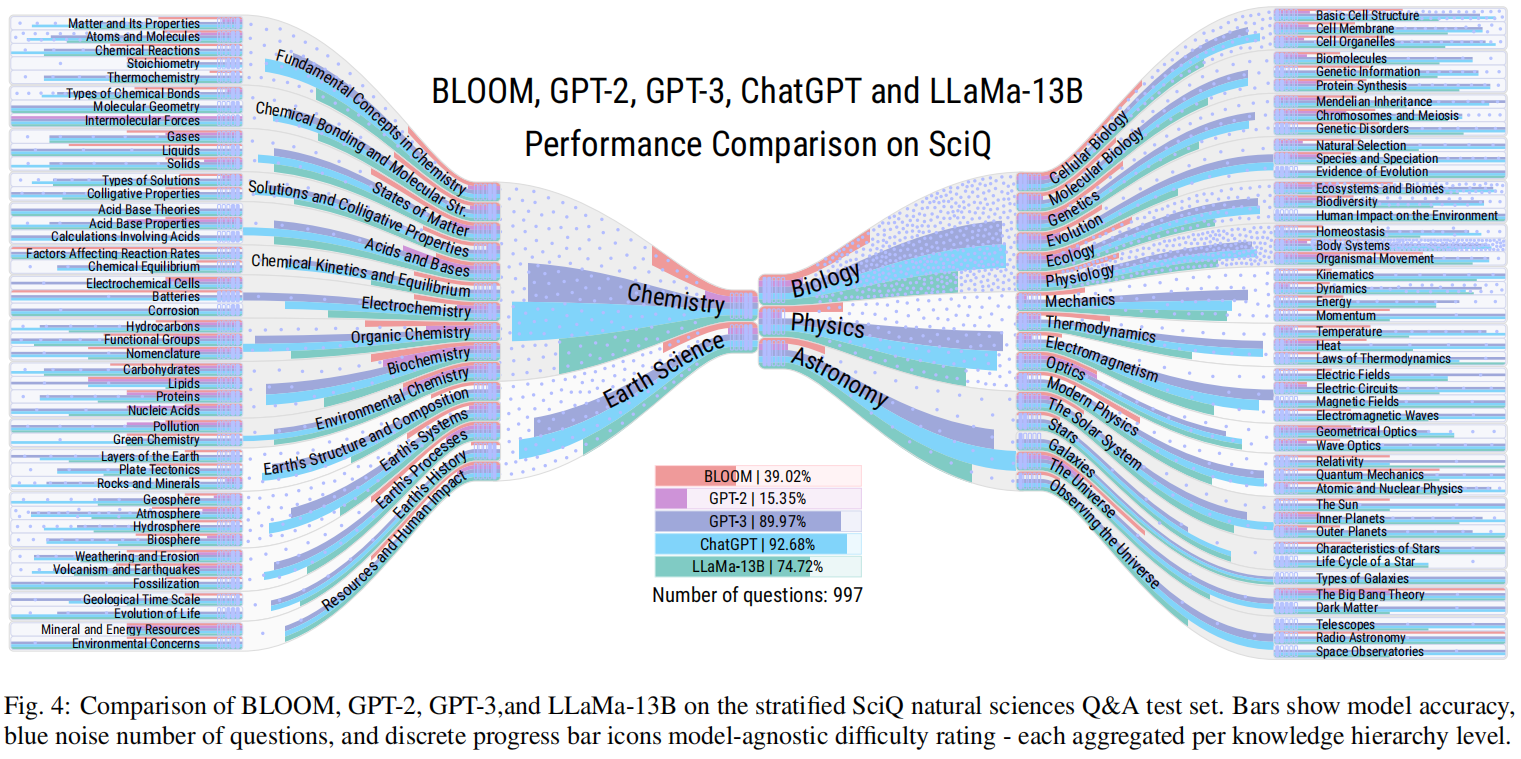
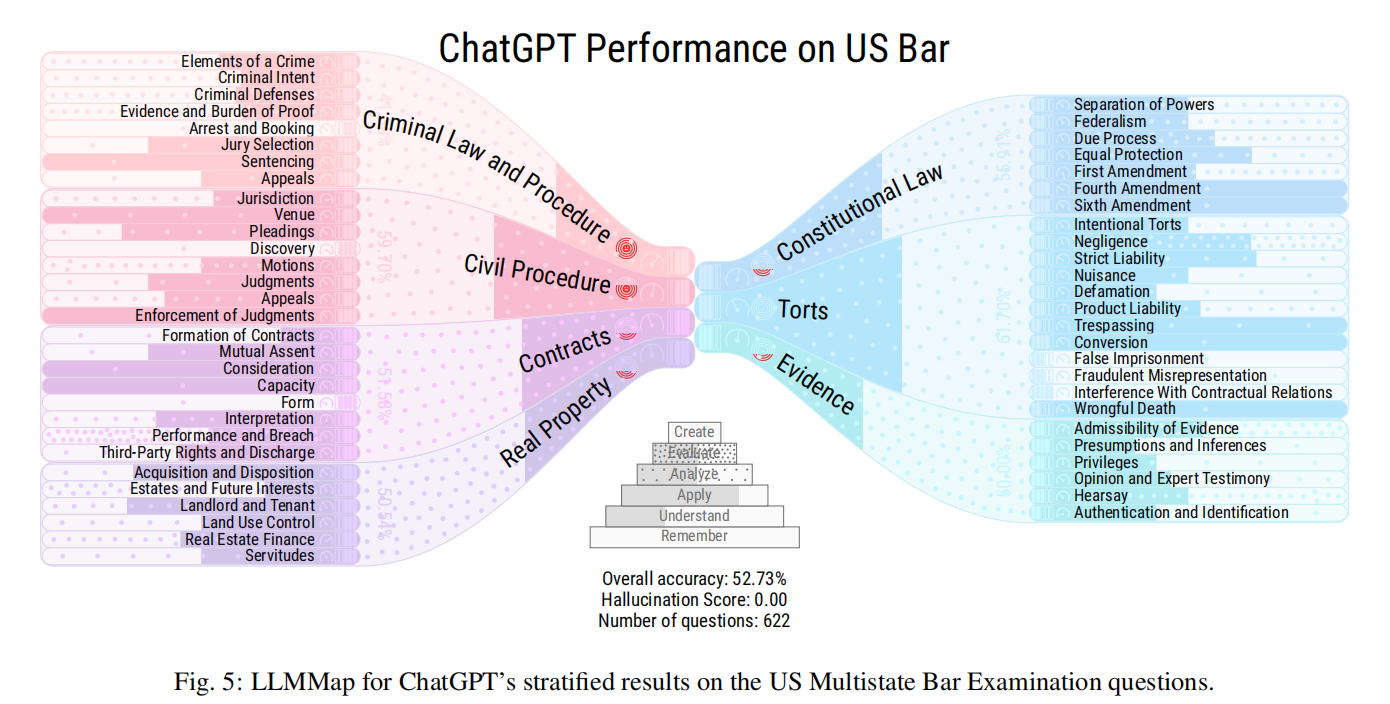
为了支持这种分层评估,本文提出了LLMMaps,这是一种新颖的可视化技术,可以让用户根据Q&A数据集评估LLMs的性能。LLMMaps通过将Q&A数据集以及LLM响应转化为本文内部知识结构,提供了关于LLMs在不同子领域的知识能力的详细见解。进一步的比较可视化扩展还允许详细比较多个LLMs。为了评估LLMMaps,本文使用它们对几个最先进的LLMs进行比较分析,如BLOOM、GPT-2、GPT-3、ChatGPT和LLaMa-13B,以及两个定性用户评估。所有用于生成LLMMaps的必要源代码和数据将在GitHub上公开。
总的来说,LLMMaps为科学出版物和其他地方提供了可用于评估LLMs的性能的必要工具,并允许更好地理解这些模型的风险,以及指导它们的进一步发展。
总结:
- LLMMaps是一种新颖的方法,通过分层评估的方式可视化评估大型语言模型。这种方法涉及将模型分成层,每层包含相关的任务或应用程序,并使用彩色地图评估模型在每个层上的表现。
- LLMMaps方法可全面且易于理解地评估大型语言模型,这对于这些模型不断增长的复杂性和规模尤为重要。通过提供视觉隐喻,LLMMaps让研究人员和从业者更好地理解语言模型的优势和不足,并确定改进的方向。
- 此外,LLMMaps可应用于广泛的NLP任务,包括机器翻译,语言建模和情感分析等。这突出了该方法的通用性和其在各个领域中改善大型语言模型开发的潜力。
标题:LLMMaps -- A Visual Metaphor for Stratified Evaluation of Large Language Models
作者:Patrik Puchert, Poonam Poonam, Christian van Onzenoodt, Timo Ropinski
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢