
神经语言模型中的事实知识可以通过将局部转换应用于实体提及和其他名词的上下文表示来解释和控制。本文描述了一个过程REMEDI,它从属性的文本描述构建这些转换。理解这种编码提供了一个了解LM行为的窗口,甚至在生成文本之前也是如此。通过放大事实的编码,我们可以强制LM生成与该事实一致的文本(即使文本提示无法做到这一点)。同样,通过检查模型的表示,我们有时可以检测到缺乏正确的信息,并预测语言模型会出错。我们的发现为控制LMs提供了一条新的途径:提示可以直接在表示空间中构建,而不是提供文本上下文或指令。特别是在较小的模型中,这些工程表示可以解锁不容易用文本提示的行为。
标题:Measuring and Manipulating Knowledge Representations in Language Models
作者:Evan Hernandez, Belinda Z. Li, Jacob Andreas
[MIT CSAIL]
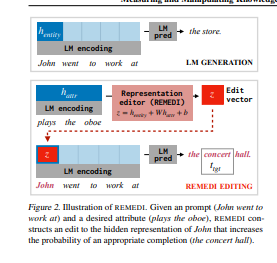
简介:神经语言模型(LMs)代表了关于文本描述的世界的事实。有时这些事实来自于训练数据(在大多数LM中,香蕉这个词的表征编码了香蕉是水果这一事实)。有时,事实来自于输入文本本身("我把瓶子倒掉了 "这句话的表示,编码了瓶子变空的事实)。几乎在所有使用LM的地方,检查和修改LM事实表述的工具都是有用的:当世界发生变化时,可以更新它们,定位和消除偏见的来源,并识别生成文本中的错误。我们描述了REMEDI,一种用于查询和修改LM中事实知识的方法。REMEDI学习一种从文本查询到LM内部表示系统的事实编码的映射。这些编码可以作为知识编辑使用:通过将它们添加到LM的隐藏表示中,我们可以修改下游的生成,使之与新的事实相一致。REMEDI编码也可以被用作模型探针:通过将它们与LM的表示进行比较,我们可以确定LM将哪些属性归于所提到的实体,并预测它们何时会产生与背景知识或输入文本相冲突的输出。因此,REMEDI将探测、提示和模型编辑方面的工作联系起来,并为精细检查和控制LM中的知识提供了通用工具的步骤。
https://arxiv.org/pdf/2304.00740.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢