
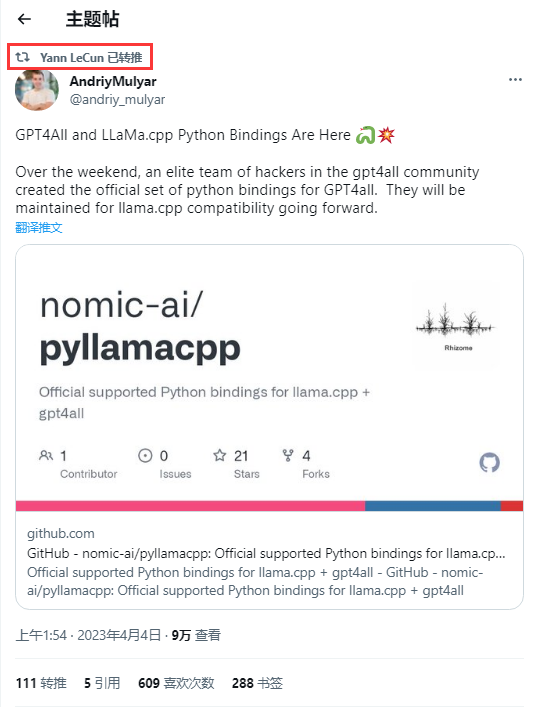
简介:
PyLLaMaCpp
是一个开源机器学习工具包,它可以使用LLaMA对ChatGPT进行微调,以生成高质量的聊天文本。文中提到,该工具包可以在Linux和MacOS上运行,并提供了使用说明和示例代码。它为研究人员在聊天文本生成领域的研究提供了更多可操作的工具。
PyLLaMaCpp是一个用于微调语言模型的机器学习工具包,主要用于在ChatGPT模型上生成高质量的聊天文本。以下是如何使用PyLLaMaCpp的一般步骤:
确保您将操作系统设置为Linux或MacOS,并以管理员身份运行。
安装LLaMA库,可以使用以下命令:
pip install llama安装PyLLaMaCpp程序包,可以使用以下命令:
pip install pyllamacpp下载聊天数据集,可以使用AI任务平台上的数据集或自己准备。
创建一个训练集和测试集,可以使用以下代码块:
from pyllamacpp.utils import readlines
from sklearn.model_selection import train_test_split
data = readlines("your_dataset.txt")
train, test = train_test_split(data, test_size=0.1, random_state=42)使用以下代码块微调ChatGPT:
from pyllamacpp.models import LanguageModel
model = LanguageModel("gpt2-medium")
model.train(train, use_gpu=True, num_epochs=5)这将使用训练集微调ChatGPT模型,使用GPU进行加速,并在5个时期内完成微调过程。
生成文本,可以使用以下代码块:
context = "你想谈什么"
output = model.generate(context, max_length=500)
print(output)这将生成一个最大长度为500的聊天文本,以响应输入的上下文。
请注意,您需要对代码进行适当的修改,以适应您的数据集和模型参数。在使用PyLLaMaCpp之前,最好先熟悉LLaMA和ChatGPT模型的基本知识。
相关资讯:
GPT4All:用GPT-3.5-Turbo的大规模数据提炼训练一个助理式聊天机器人
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢