
标题:Subject-driven Text-to-Image Generation via Apprenticeship Learning
作者:Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Rui, Xuhui Jia, Ming-Wei Chang, William W. Cohen
[Google]
简介:
- 最近,像DreamBooth这样的文本-图像生成模型在生成目标对象的高度定制化图像方面取得了显著的进展,通过从一些例子中对特定对象的 "专家模型 "进行微调。然而,这个过程是昂贵的,因为必须为每个主题学习一个新的专家模型。
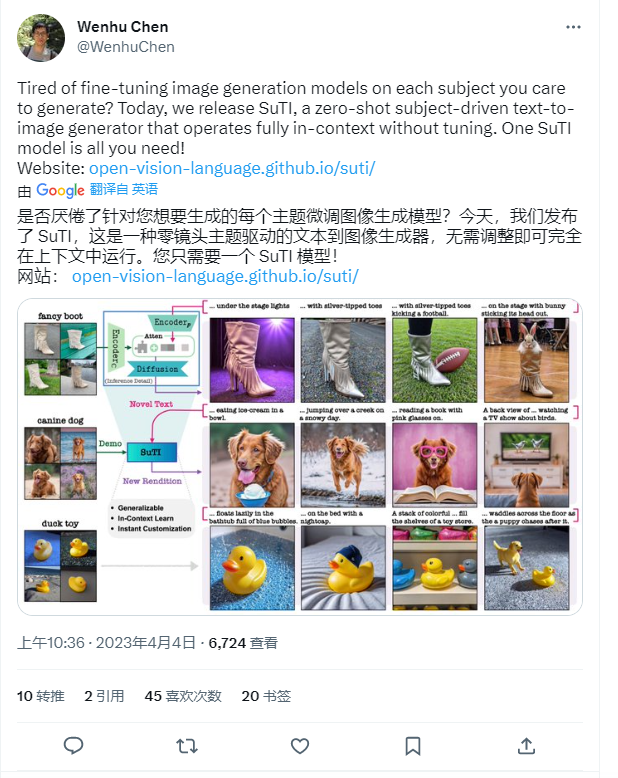
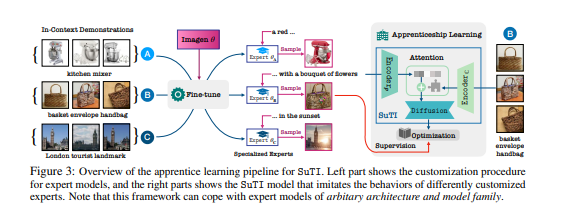
- 在本文中,我们提出了SUTI,一个主题驱动的文本-图像生成器,它用in-context学习取代了特定主题的微调。给予一个新主题的几个示范,SUTI可以立即生成该主题在不同场景中的新演绎,而不需要任何特定主题的优化。SuTI是由{学徒学习}提供动力的,其中一个学徒模型是从大量特定主题的专家模型产生的数据中学习的。
- 具体来说,我们从互联网上挖掘出数以百万计的图像集群,每个集群都围绕一个特定的视觉主题。我们采用这些集群来训练大量专门针对不同主题的专家模型。然后,学徒模型SUTI通过所提出的学徒学习算法,学习模仿这些专家的行为。与基于优化的SoTA方法相比,SuTI能够以20倍的速度生成高质量和定制的特定主题图像。在具有挑战性的DreamBench和DreamBench-v2上,我们的人类评估表明,SuTI可以明显地超过现有的方法,如InstructPix2Pix、Textual Inversion、Imagic、Prompt2Prompt、Re-Imagen,同时表现与DreamBooth相当。
https://arxiv.org/pdf/2304.00186.pdf
代码地址:https://open-vision-language.github.io/suti/



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢