
标题:Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
作者:Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Ying Shan, Xiu Li, Qifeng Chen
[Tsinghua University & HKUST & Tencent AI Lab ]
简介:
- 生成文字可编辑和姿势可控制的人物视频在创造各种数字人类方面有着迫切的需求。然而,由于缺乏以视频姿势配对为特征的综合数据集和视频的生成性先验模型,这项工作一直受到限制。
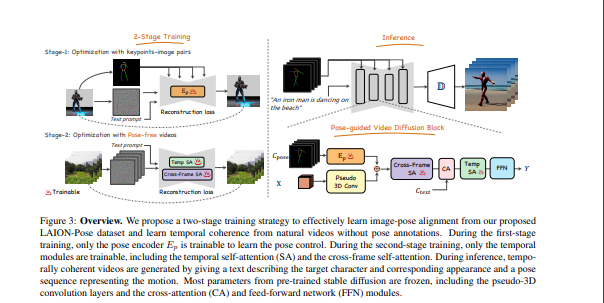
- 在这项工作中,我们设计了一个新颖的两阶段训练方案,可以利用容易获得的数据集(即图像姿势配对和无姿势视频)和预先训练的文本-图像(T2I)模型来获得姿势可控的人物视频。
- 具体来说,在第一阶段,只有关键点-图像对被用于可控文本-图像的生成。我们学习一个零初始化的卷积编码器来编码姿势信息。在第二阶段,我们通过一个无姿势的视频数据集,通过添加可学习的时间自我注意和改革的跨帧自我注意块,对上述网络的运动进行微调。通过我们的新设计,我们的方法成功地生成了连续姿势可控的角色视频,同时保持了预训练的T2I模型的编辑和概念构成能力。这些代码和模型将被公开提供。
https://arxiv.org/pdf/2304.01186.pdf


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢