
Koala: A Dialogue Model for Academic Research
Xinyang Geng*、Arnav Gudibande*、Hao Liu*和Eric Wallace*
在这篇文章中,我们介绍了 Koala,这是一种聊天机器人,通过对从网络收集的对话数据微调 Meta 的LLaMA进行训练。我们描述了我们模型的数据集管理和训练过程,还展示了将我们的模型与ChatGPT和斯坦福大学的 Alpaca进行比较的用户研究结果。我们的结果表明,Koala 可以有效地响应各种用户查询,生成的响应通常优于 Alpaca,并且至少在超过一半的情况下与 ChatGPT 相关。
我们希望这些结果能够进一步促进围绕大型闭源模型与小型公共模型的相对性能的讨论。特别是,它表明,如果在仔细收集的数据上进行训练,那么小到可以在本地运行的模型可以捕捉到它们较大表亲的大部分性能。例如,这可能意味着社区应该更加努力地管理高质量的数据集,因为这可能比简单地增加现有系统的规模更能实现更安全、更真实和更有能力的模型。我们强调 Koala 是一个研究原型,虽然我们希望它的发布能提供有价值的社区资源,但它在内容、安全性和可靠性方面仍然存在重大缺陷,不应该在研究之外使用。
系统总览
大型语言模型 (LLM) 使越来越强大的虚拟助手和聊天机器人成为可能,其中包括ChatGPT、Bard、Bing Chat和Claude等系统能够响应广泛的用户查询,提供示例代码,甚至写诗。许多最有能力的 LLM 需要大量的计算资源来训练,并且经常使用大型专有数据集。这表明,在未来,功能强大的 LLM 将主要由少数组织控制,用户和研究人员都将付费与这些模型进行交互,而无需直接访问以自行修改和改进它们。另一方面,最近几个月还发布了功能越来越强大的免费或(部分)开源模型,例如LLaMA. 这些系统通常不及最强大的封闭模型,但它们的能力一直在迅速提高。这向社区提出了一个重要问题:未来会看到越来越多的围绕少数闭源模型的整合,还是会看到具有更小架构的开放模型的增长,以接近其更大但闭源的同类模型的性能?
虽然开放模型不太可能与封闭源模型的规模相匹配,但使用精心挑选的训练数据也许可以使它们接近其性能。事实上,斯坦福大学的 Alpaca等对来自 OpenAI 的 GPT 模型的数据微调 LLaMA 的努力表明,正确的数据可以显着改进较小的开源模型。
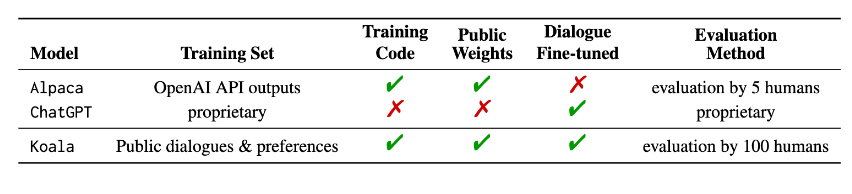
我们引入了一个新模型 Koala,它为本次讨论提供了额外的证据。Koala 对从网络上抓取的免费交互数据进行了微调,但特别关注包括与 ChatGPT 等功能强大的闭源模型交互的数据。我们根据从网络和公共数据集中抓取的对话数据微调 LLaMA 基础模型,其中包括对来自其他大型语言模型的用户查询的高质量响应,以及问答数据集和人类反馈数据集。由此产生的模型 Koala-13B 显示了与现有模型相比具有竞争力的性能,正如我们对真实世界用户提示的人工评估所建议的那样。
我们的结果表明,从高质量数据集中学习可以减轻较小模型的一些缺点,甚至可能在未来匹配大型闭源模型的功能。例如,这可能意味着社区应该更加努力地管理高质量的数据集,因为这可能比简单地增加现有系统的规模更能实现更安全、更真实和更有能力的模型。
通过鼓励研究人员参与我们的系统演示,我们希望发现任何意想不到的功能或缺陷,以帮助我们在未来评估模型。我们要求研究人员报告他们在我们的网络演示中观察到的任何令人震惊的行为,以帮助我们理解和解决任何问题。与任何发布一样,都存在风险,我们将在本博文后面详细说明此次公开发布的原因。我们强调 Koala 是一个研究原型,虽然我们希望它的发布能提供有价值的社区资源,但它在内容、安全性和可靠性方面仍然存在重大缺陷,不应该在研究之外使用。下面我们概述了 Koala 与现有著名模型之间的差异。
数据集和培训
构建对话模型的主要障碍是管理训练数据。著名的聊天模型,包括ChatGPT、Bard、Bing Chat和Claude,都使用使用大量人工注释构建的专有数据集。为了构建 Koala,我们通过从网络和公共数据集中收集对话数据来整理我们的训练集。该数据的一部分包括用户在线发布的与大型语言模型(例如 ChatGPT)的对话。
我们不是通过尽可能多地抓取网络数据来最大化数量,而是专注于收集小型高质量数据集。我们使用公共数据集进行问题回答、人类反馈(正面和负面的回答)以及与现有语言模型的对话。我们在下面提供了数据集组成的具体细节。
ChatGPT 蒸馏数据
使用 ChatGPT (ShareGPT) 的公共用户共享对话使用公共 API 收集了用户在ShareGPT上共享的大约 60K 对话。为了保持数据质量,我们在用户查询级别进行了重复数据删除,并删除了所有非英语对话。这留下了大约 30K 个示例。
Human ChatGPT Comparison Corpus (HC3)我们同时使用来自HC3 英语数据集的人类和 ChatGPT 响应,其中包含大约 60K 人类答案和 27K ChatGPT 答案,用于大约 24K 问题,产生总数大约 87K 的问答示例。
开源数据
开放式教学通才 (OIG)。我们使用从LAION 策划的开放指令通才数据集中手动选择的组件子集。具体来说,我们使用小学数学教学、诗歌到歌曲和情节-剧本-书籍-对话数据集。这导致总共大约 30k 个示例。
斯坦福羊驼。我们包括用于训练斯坦福羊驼模型的数据集。该数据集包含大约 52K 个示例,这些示例由 OpenAI 的 text-davinci-003 按照自我指导过程生成。值得注意的是,HC3、OIG 和 Alpaca 数据集是单轮问答,而 ShareGPT 数据集是对话对话。
人择HH。Anthropic HH数据集包含人类对模型输出的危害性和有用性的评级。该数据集包含约 160,000 个人类评价的示例,其中该数据集中的每个示例都包含来自聊天机器人的一对响应,其中一个是人类更喜欢的。该数据集为我们的模型提供了功能和额外的安全保护。
OpenAI WebGPT。OpenAI WebGPT数据集总共包含大约 20K 个比较,其中每个示例都包含一个问题、一对模型答案和元数据。答案由具有偏好分数的人进行评分。
OpenAI 总结。OpenAI摘要数据集包含约 93K 个示例,每个示例都包含人类对模型生成的摘要的反馈。人类评估人员从两个选项中选择了更好的摘要。
使用开源数据集时,一些数据集有两个响应,分别对应评级为好或差的响应(Anthropic HH、WebGPT、OpenAI Summarization)。我们以Keskar 等人、Liu 等人和Korbak 等人之前的研究为基础,他们证明了条件语言模型对人类偏好标记(例如“有用的答案”和“无用的答案”)提高性能的有效性。我们根据偏好标签将模型设置为正标记或负标记。我们在没有人工反馈的情况下对数据集使用正面标记。为了进行评估,我们提示带有正标记的模型。
Koala 模型在EasyLM中使用 JAX/Flax 实现,这是我们的开源框架,可以轻松预训练、微调、服务和评估各种大型语言模型。我们在配备 8 个 A100 GPU 的单个 Nvidia DGX 服务器上训练我们的 Koala 模型。完成 2 个 epoch 的训练需要 6 个小时。在公共云计算平台上,使用可抢占实例进行此类训练的成本通常低于 100 美元。
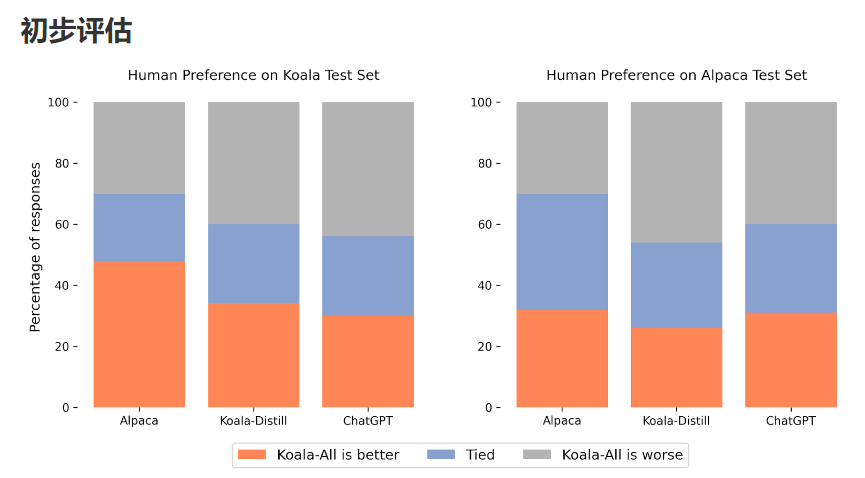
在我们的实验中,我们评估了两个模型:只使用蒸馏数据的 Koala-Distill 和使用所有数据(包括蒸馏和开源数据)的 Koala-All。我们的目标是比较这些模型的性能,并评估蒸馏和开源数据集对最终性能的影响。我们进行了一项人工评估,将 Koala-All 与 Koala-Distill、Alpaca 和 ChatGPT 进行比较。我们在上图中展示了我们的结果。我们在两个不同的集合上进行评估,一个由斯坦福羊驼使用的 180 个测试查询(“羊驼测试集”)和我们自己的测试集(“考拉测试集”)组成。
羊驼测试集由从自我指导数据集中采样的用户提示组成,并代表羊驼模型的分布数据。为了提供第二个更真实的评估协议,我们还引入了我们自己的 (Koala) 测试集,其中包含在线发布的180 个真实用户查询。这些用户查询涵盖各种主题,通常是对话式的,并且可能更能代表基于聊天的系统的真实用例。为了减少可能的测试集泄漏,我们使用训练集中的任何示例过滤掉了 BLEU 分数大于 20% 的查询。此外,我们删除了非英语和与编码相关的提示,因为对这些查询的回答无法由我们的评分员(人群工作者)可靠地审查。我们发布我们用于学术用途和未来基准测试的测试集。
有了这两个评估集,我们通过在 Amazon Mechanical Turk 平台上询问大约 100 名评估员来比较这些保留的提示集上模型输出的质量,从而进行了盲配对比较。在评分界面中,我们向每个评分者展示一个输入提示和两个模型的输出。然后要求他们使用与响应质量和正确性相关的标准来判断哪个输出更好(或者它们同样好)。
在 Alpaca 测试集上,Koala-All 表现出与 Alpaca 相当的性能。然而,在我们提出的由真实用户查询组成的测试集上,Koala-All 在近一半的情况下被评为优于羊驼毛,并且在 70% 的情况下超过或与羊驼毛持平。当然,Koala 测试集中的对话提示越多,越接近 Koala 训练集,所以这也许并不奇怪,但就此类提示越接近此类模型的可能下游用例而言,这表明 Koala 是预期的在类似助手的应用程序中表现更好。这表明来自用户在网络上发布的示例的 LLM 交互数据是赋予此类模型有效指令执行能力的有效策略。
也许更令人惊讶的是,我们发现除了蒸馏数据 (Koala-All) 之外,对开源数据的训练比仅对 ChatGPT 蒸馏数据 (Koala-Distill) 的训练表现稍差,如与 Koala-Distill 在两个数据集。尽管差异可能并不显着,但这一结果表明 ChatGPT 对话的质量如此之高,以至于即使包含两倍的开源数据也不会带来显着的改进。我们最初的假设是 Koala-All 应该至少表现得更好一些,因此我们在所有评估中都将其用作我们的主要模型,但这些实验的一个潜在收获是有效的指令和辅助模型可以从 LLM 主干(如 LLaMA)中进行微调完全使用来自更大更强大模型的数据,只要这些响应的提示代表用户将在测试时提供的提示类型。这也进一步支持了这样一种观点,即建立强大的对话模型的关键可能更多地在于策划用户查询多样化的高质量对话数据,而不是简单地将现有数据集重新格式化为问题和答案。
限制和安全
与其他语言模型一样,Koala 也有局限性,如果使用不当可能会造成伤害。我们观察到考拉可以产生幻觉并以高度自信的语气产生非事实的反应,这可能是对话微调的结果。不幸的是,这可能意味着较小的模型在继承相同级别的真实性之前继承了较大语言模型的自信风格——如果属实,这是一个在未来工作中研究的重要限制。如果使用不当,考拉的幻觉反应可能会助长错误信息、垃圾邮件和其他内容的传播。

考拉可以用自信和令人信服的语气产生不准确的信息。除了幻觉之外,Koala 还存在其他聊天机器人语言模型的不足之处。其中一些包括:
- 偏见和刻板印象:我们的模型会从它所训练的对话数据中继承偏见,可能会延续有害的刻板印象、歧视和其他危害。
- 缺乏常识:虽然大型语言模型可以生成看起来连贯且语法正确的文本,但它们往往缺乏人类认为理所当然的常识知识。这可能会导致无意义或不适当的反应。
- 有限的理解:大型语言模型可能难以理解对话的上下文和细微差别。他们也可能难以识别讽刺或讽刺,这可能会导致误解。
为了解决 Koala 的安全隐患,我们在 ShareGPT 和 Anthropic HH 的数据集中加入了对抗性提示,以使模型更加稳健和无害。为了进一步减少潜在的滥用,我们在在线演示中部署了 OpenAI 的内容审核过滤器,以标记和删除不安全的内容。我们将对 Koala 的安全性保持谨慎,并致力于对其进行进一步的安全评估,同时监控我们的互动演示。总的来说,我们决定发布 Koala,因为我们认为它的好处大于风险。
发布
我们正在发布以下工件:
- 考拉在线互动演示
- EasyLM:我们用来训练 Koala 的开源框架
- 预处理训练数据的代码
- 我们的查询测试集
- 模型权重:我们希望尽快发布权重,但我们仍在调查一些权限和许可问题以负责任地进行此操作。
执照
在线演示是仅供学术研究使用的研究预览,受LLaMA模型许可、 OpenAI 生成数据的使用条款和ShareGPT隐私惯例的约束。严禁将在线演示用于任何其他用途,包括但不限于商业用途。如果您发现任何潜在的违规行为,请与我们联系。我们的训练和推理代码是根据 Apache License 2.0 发布的。
未来的工作
我们希望 Koala 模型将成为未来大型语言模型学术研究的有用平台:该模型足以展示我们与现代 LLM 相关的许多功能,同时又足够小以进行微调或用于更多有限的计算。潜在有希望的方向可能包括:
- 安全性和一致性:Koala 允许进一步研究语言模型的安全性并更好地与人类意图保持一致。
- 模型偏差:Koala 使我们能够更好地理解大型语言模型的偏差、对话数据集中虚假相关和质量问题的存在,以及减轻此类偏差的方法。
- 理解大型语言模型:由于 Koala 推理可以在相对便宜的商品 GPU 上执行,它使我们能够更好地检查和理解对话语言模型的内部结构,使(以前的黑盒)语言模型更具可解释性。
团队
考拉模型是加州大学伯克利分校伯克利人工智能研究实验室 (BAIR)多个研究小组的共同努力。
学生(字母顺序):
Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace
顾问(按字母顺序):
Pieter Abbeel, Sergey Levine, Dawn Song
致谢
我们感谢加州大学伯克利分校的 Sky Computing Lab 为我们提供服务后端支持。感谢 Charlie Snell、Lianmin Zheng、Zhuohan Li、Hao Zhang、Wei-Lin Chiang、Zhanghao Wu、Aviral Kumar 和 Marwa Abdulhai 的讨论和反馈。我们要感谢 Tatsunori Hashimoto 和 Jacob Steinhardt 就限制和安全性进行的讨论。我们还要感谢 Yuqing Du 和 Ritwik Gupta 对 BAIR 博客的帮助。请查看来自 Sky Computing Lab 的博客文章,内容是关于他们的聊天机器人 Vicuna 的并行工作。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢