
标题:Instruction Tuning with GPT-4
[Microsoft Research]
简介:
之前的工作表明,使用机器生成的指令跟随数据对大型语言模型(LLM)进行微调,可以使这类模型在新任务上获得显著的零点能力,而且不需要人类编写的指令。
在本文中,我们首次尝试使用GPT-4来生成指令跟踪数据,用于LLM的微调。我们对指令调整的LLaMA模型的早期实验表明,由GPT-4生成的52K英文和中文指令跟随数据在新任务上带来了比以前最先进的模型生成的指令跟随数据更好的零点性能。我们还收集了GPT-4的反馈和比较数据,以便能够进行全面的评估和奖励模型训练。
我们公开了使用GPT-4生成的数据以及我们的代码库。
https://instruction-tuning-with-gpt-4.github.io/
https://arxiv.org/pdf/2304.03277.pdf

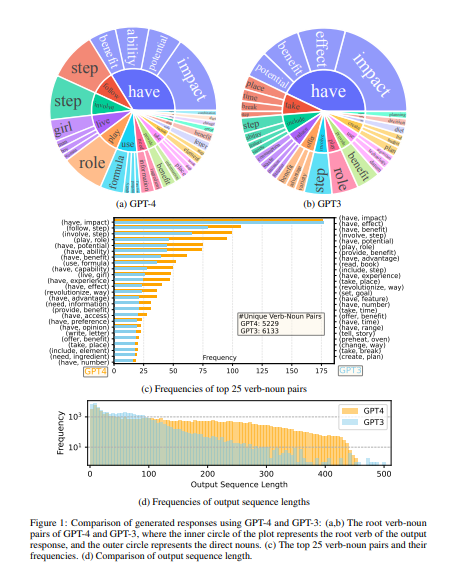
更多可以参考https://mp.weixin.qq.com/s/JWn2wZeg7MJ33zTq2TOCGg
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢