
近几个月,多个大型语言模型(LLMs,包括OpenAI 的 GPT-3,ChatGPT和GPT-4;Anthropic 的 Claude; Google 的 T5,PaLM 和 Bard; Meta 的 LLaMA等)广泛公共部署或开源。然而,这种技术在自然语言理解和生成的许多方面都超出了人们的预期,这也引起了来自许多领域的倡导者、媒体记者、政策制定者和学者的广泛关注和参与。这种关注是对这项技术引发的许多紧迫问题的回应,显然是合适的,因为这项技术正在成为具有重大影响力的技术,人们希望政府和公民社会的力量也都参与其中,以确定我们该如何使用它。但有时也可能某些忽略重要的考虑因素。
Anthropic 技术团队的核心成员以及纽约大学终身教授 Sam Bowman 最近几个月一直在试图梳理总结目前业界对大语言模型 (LLMs) 的了解,并在最近撰写并在其个人网站上发布略带主观色彩的调查性论文草稿:关于大型语言模型(LLMs)需要知道的八件事 (Eight Things to Know about Large Language Models; https://cims.nyu.edu/~sbowman/eightthings.pdf) 。
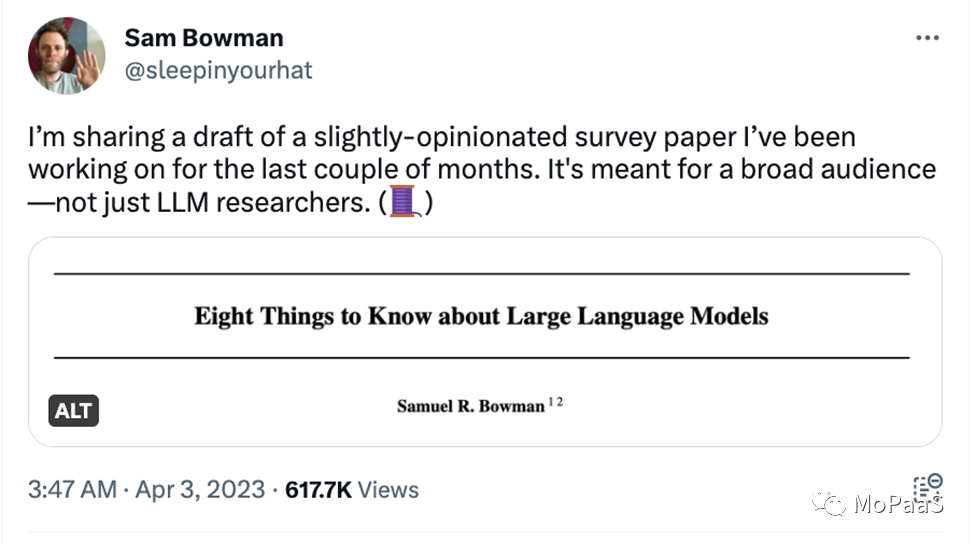
他的八个主要观点包括:
1、即使没有针对性的创新,LLMs的能力会随着投入的增加而可预测地提高 (LLMs predictably get more capable with increasing investment, even without targeted innovation)。
2、许多重要的LLMs行为会在不可预测的情况下作为增加投入的副产品出现 (Many important LLM behaviors emerge unpredictably as a byproduct of increasing investment)。
3、LLMs经常表现出学习和使用外部世界的表示 (LLMs often appear to learn and use representations of the outside world)。
4、目前没有可靠的技术来控制LLMs的行为 (There are no reliable techniques for steering the behavior of LLMs)。
5、专家们尚未能够解释LLMs的内部运作方式 (Experts are not yet able to interpret the inner workings of LLMs)。
6、人类在某项任务上的表现并不是LLMs表现的上限 (Human performance on a task isn’t an upper bound on LLM performance)。
7、LLMs不一定表达其创建者的价值观,也不一定表达编码在网络文本中的价值观 (LLMs need not express the values of their creators nor the values encoded in web text)。
8、与LLMs聊天机器人的简短互动往往是具有误导性的 ( Brief interactions with LLMs chatbots are often misleading)。
作者认为这八个重要的观察是令人惊讶的,而且在很多讨论中很容易被忽略。这些主张在围绕LLMs展开的许多对话中都会引人关注。作者了解到,这些观点在各个私有实验室中开发这些模型的研究人员中已经被广泛分享。该文提供的所有证据以及大多数论点都来自先前的研究,作者鼓励任何发现这些主张有用的人参考该文提到的来源。
作者希望这篇论文能够涵盖对某些决策有关联的观点,但对于刚开始跟进这项技术的人来说可能会容易忽略这些观点。他甚至也考虑过将其称为“大型语言模型是一种奇怪的技术的八个方面 (Eight Ways that Large Language Models are a Weird Technology)”。所有这些观察都应该对一些研究和测试这些模型的研究人员来说显而易见,而且有一些证据支持,尽管其中一些仍然存在争议——作者尝试指出这种情况的地方。
即使这样可能有些从业者或用户还会觉得这些观点还缺乏足够的证据,有些结论还值得商榷,所以作者并不希望让这些说法在任何重大程度上成为规范。相反,这项工作的动机是出于认识到,在这种颠覆性的新技术的背景下,我们应该怎么做是一个最好由来自核心技术研发社区之外的学者、倡导者和立法者以明智的方式引导的问题。
作者在Twitter 和LinkedIn等社交媒体上介绍这篇调查性论文时也一再强调这是一篇调查性论文:所使用的所有证据都是由他人发表的,大多数论点已经被其他人清晰地表达过。如果有疑问,希望读者引用他们而不是该文作者。

作者还以一些非调查性的讨论结束了本文,对上述内容进行了一些带有预测性的调整,包括:
1、我们应该期望当前LLM的一些显著缺陷得到显著改进 (We should expect some of the prominent flaws of current LLMs to improve significantly)。
2、部署LLM作为灵活追求目标的代理的激励措施将会出现(There will be incentives to deploy LLMs as agents that flexibly pursue goals)。
3、LLM开发人员对开发内容的影响力有限(LLM developers have limited influence over what is developed)。
4、LLM很可能会产生一系列快速增长的风险(LLMs are likely to produce a rapidly growing array of risks)。
5. LLM的负面结果可能难以解释,但指出了真正的弱点(Negative results with LLMs can be difficult to interpret but point to areas of real weakness)。
6、LLM周围的科学和学术研究尤其不成熟(The science and scholarship around LLMs is especially immature)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢