
标题:Inference with Reference: Lossless Acceleration of Large Language Models
[Microsoft]
简介:
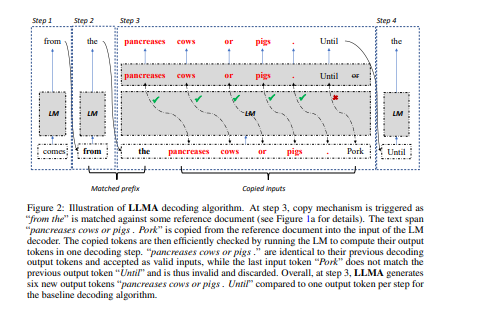
本文提出了LLMA,一个LLM加速器,用于无损地加速有参考文献的大型语言模型(LLM)推理。
LLMA的动机是观察到在许多现实世界的场景中(如检索的文件),LLM的解码结果与参考文献之间存在大量相同的文本跨度。LLMA首先从参考文献中选择一个文本跨度,并将其标记复制到解码器中,然后在一个解码步骤中有效地检查这些标记是否适合作为解码结果。改进的计算并行性使LLMA在许多实际的生成场景中实现了2倍以上的速度,其生成结果与贪婪解码相同(如搜索引擎和多轮对话),在这些场景中,上下文参考和输出之间存在大量重叠。
https://arxiv.org/pdf/2304.04487.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢