标题:RRHF: Rank Responses to Align Language Models with Human Feedback without tears
作者:Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
[Alibaba DAMO Academy & Tsinghua University]
OpenAI 的 ChatGPT 理解多种多样的的人类指令,并且可以很好的应对不同的语言任务需求。自发布以来就掀起了对于通用人工智能的讨论。ChatGPT 令人惊叹的能力来源于一种新颖的大规模语言模型微调方法:RLHF(通过强化学习对齐人类反馈)。
RLHF 方法不同于以往传统的监督学习的微调方式,该方法首先让模型根据指令提示生成不同的回复,之后通过人工的评价反馈,使用强化学习的方式对 LLM 进行微调。RLHF 解锁了语言模型跟从人类指令的能力,并且使得语言模型的能力和人类的需求和价值观对齐,从而使得 RLHF 微调下的语言模型具有令人惊叹的能力。
当前研究 RLHF 的工作主要使用 PPO 算法对语言模型进行优化。从一个使用指令和人类示范的数据通过监督学习微调的语言模型开始,PPO 算法首先使用这个语言模型输出对于不同指令数据的回复,之后通过一个奖励模型对语言模型的不同回复进行打分评价,最后使用打分评价通过策略梯度下降的方式对语言模型进行优化。
考虑到语言模型在训练中不断变化和奖励模型有限的泛化能力,PPO 在工程实践中需要反复迭代上述流程,并且在奖励的设计上需要限制微调的语言模型不能偏离初始模型太远。由于使用强化学习训练包含有众多的超参数,并且在算法迭代的过程中需要多个独立模型的相互配合,错误的实现细节都会导致不尽如人意的训练结果。
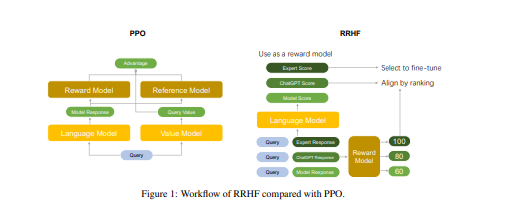
在和人类对齐的角度上,强化学习算法是不是必须的呢?该篇论文提出了基于排序的人类偏好对齐方法。它对不同语言模型生成的回复(回复可以来自 ChatGPT、GPT-4、当前的训练模型或者人类标注数据)进行评分,评分来自于回复在当前模型下的对数概率。RRHF 通过通过排名损失使评分与人类的偏好(或者代理的奖励模型)对齐。RRHF 训练好的模型可以同时作为生成语言模型和奖励模型使用。下图中对比了 PPO 算法和 RRHF 算法的区别。
简介:
人类反馈强化学习 (RLHF) 促进了大型语言模型与人类偏好的对齐,显着提高了人类与这些模型之间的交互质量。InstructGPT 通过几个阶段实现 RLHF,包括监督微调 (SFT)、奖励模型训练和近端策略优化 (PPO)。然而,PPO 对超参数很敏感,并且在其标准实现中至少需要四个模型,这使得它很难训练。
相比之下,我们提出了一种称为 RRHF 的新型学习范式,它对不同采样策略生成的响应进行评分,并通过排名损失学习使它们与人类偏好保持一致。RRHF 可以像微调一样有效地将语言模型输出概率与人类偏好对齐,并且在调优期间只需要 1 到 2 个模型。此外,RRHF 可以被认为是 SFT 和奖励模型的扩展,同时在编码、模型计数和超参数方面比 PPO 更简单。整个对齐过程可以在一次 RRHF 培训课程中完成。我们使用 LLaMA 和 Alpaca 在有用和无害的数据上评估 RRHF,展示了与 PPO 相当的性能。
https://arxiv.org/pdf/2304.05302.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢