
项目地址:
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat
总结
本工作旨在通过利用各种规模下的FPGA加速器将大规模的语言模型RLHF(Regularized LHF)方法推广到ChatGPT类语言模型的训练中。这样可以实现具有实际规模的训练,减少模型开发和训练的时间和成本。为了实现这个目标,本文提出了一种新的混合精度训练方案,该方案结合了MPI与数据并行之间的一些优点,并使用了本地TensorCore加速器,同时也支持分布式训练。实验结果表明,这种方法比当前最好的方法更快,同时也可以确保模型的质量。这个工作的结果对于以后更有效地训练大规模语言模型具有参考价值。
概述
ChatGPT类模型以其卓越的性能,如摘要、编码和翻译等任务与人类专家不相上下,已经在人工智能领域横扫一切。为了使ChatGPT类模型更容易被广泛使用,AI开源社区已经在多个方面努力(例如:ChatLLaMa、Alpaca、Vicuna、Databricks-Dolly等)。然而,现有的ChatGPT类模型系统仍存在不足之处,如无法进行易于访问的RLHF管道训练以实现高效、快速和价格实惠的训练,无法支持成本高昂的多GPU设置等。此外,现有的解决方案不能支持用于数百亿参数的现代ChatGPT模型的明显易用、快速和经济的训练。
DeepSpeed-Chat针对现有系统的不足,提供了易于使用的RLHF训练系统,可以快速、经济地训练强大的ChatGPT模型。DeepSpeed-Chat包含以下三个能力。
- 第一个是易于使用的ChatGPT类模型训练和推理体验,只需一份脚本即可实现对预训练Huggingface模型的训练,并使用DeepSpeed-RLHF系统运行所有三个InstructGPT训练步骤,生成自己的ChatGPT模型。此外,我们还提供了推理API,可用于在模型训练后测试对话式交互。
- 第二个是DeepSpeed-RLHF管道,主要复制InstructGPT论文中的训练管道,并仔细注意确保完整性和一对一的一致性,包括a)监督微调(SFT),b)奖励模型微调和c)强化学习与人的反馈(RLHF)。此外,还提供数据抽象和混合功能,以实现使用多数据源进行训练。
- 第三个是DeepSpeed-RLHF系统,这是一个强健而复杂的RLHF系统,将DeepSpeed的训练和推理能力整合到单一统一的混合引擎(DeepSpeed-HE)中,并实现无缝转换,具有高级别的优化策略,如张量并行和高性能变压器内核生成等,同时还能受益于多种基于ZeRO和LORA的用于RL训练的内存优化策略。
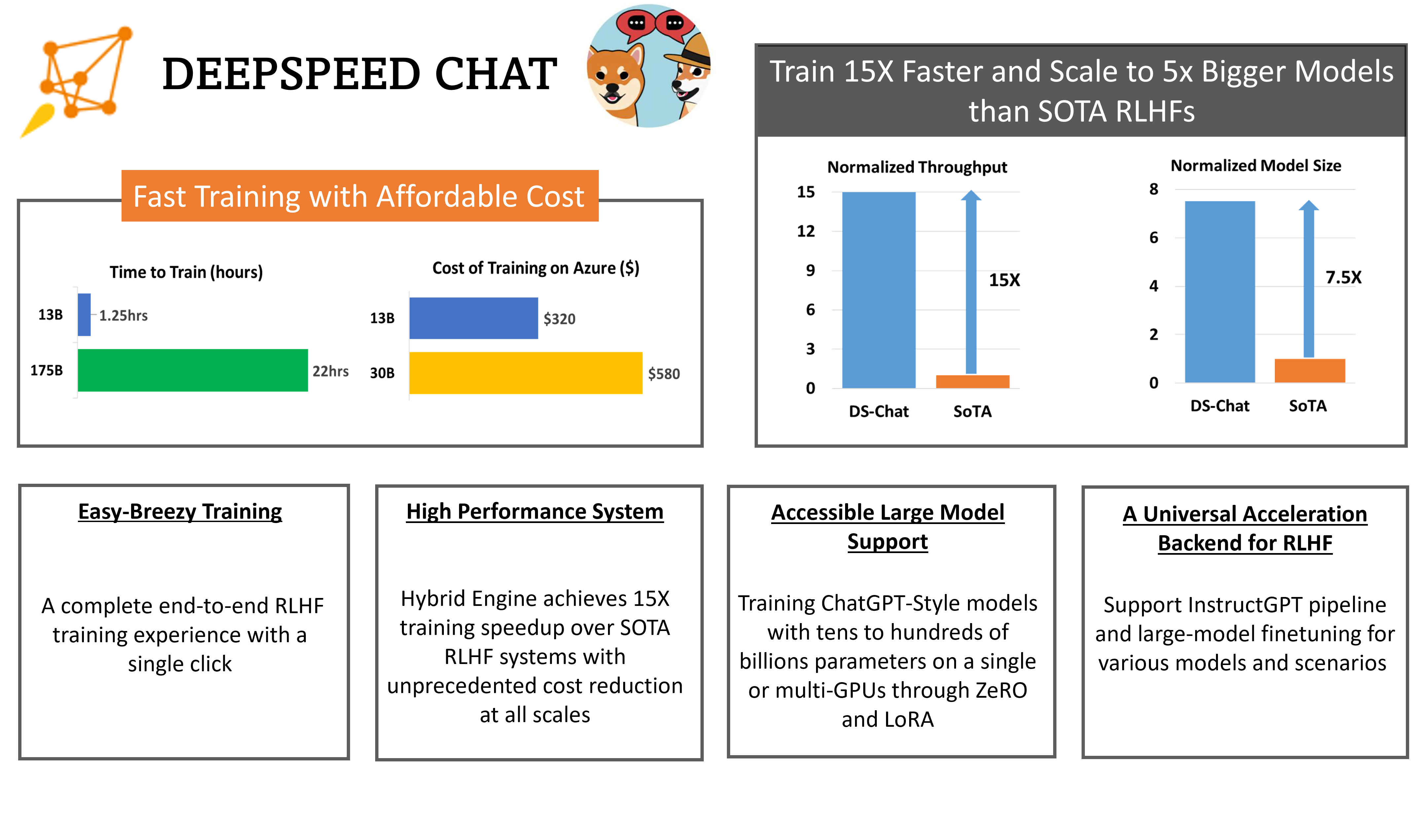
DeepSpeed-RLHF系统具有无与伦比的规模效率,使复杂的RLHF训练快速、价格实惠,易于面向AI社区的访问。例如,DeepSpeed-HE在效率上比现有系统快15倍以上,可以在Azure云上分别在9小时内和18小时内以低于300美元和600美元的价格来训练OPT-13B和OPT-30B模型。

卓越的可扩展性:DeepSpeed-HE支持具有数百亿参数的模型,并且可以在多节点多GPU系统上实现卓越的可扩展性。因此,即使是一个13B模型也可以在1.25小时内进行训练,巨大的175B模型也可以在不到一天的时间内使用DeepSpeed-HE进行训练。

非常重要的细节:上面两个表格中的数字是针对训练的第三步,基于在DeepSpeed-RLHF精选数据集和训练配方上实际测量的训练吞吐量,这个配方对总共1.35亿个标记进行了一个时期的训练。我们总共有6750万个查询标记(具有256个序列长度的131.9k个查询)和6750万个生成标记(具有256个序列长度的131.9k个答案),每步的最大全局批处理大小为0.5M标记(1024个查询-答案对)。我们敦促读者在与DeepSpeed-RLHF进行任何成本和端到端的时间比较之前,要注意这些规格。请参见我们的基准设置页面以获取更多详细信息。
自定义RLHF训练:仅用一个GPU,DeepSpeed-HE支持训练具有超过130亿个参数的模型,使得没有多GPU系统访问权限的数据科学家不仅可以创建玩具RLHF模型,还可以创建大型且强大的模型,可用于实际应用场景。

RLHF训练流程
我们遵循InstructGPT的做法,在DeepSpeed-Chat中包括一个完整的端到端训练流程,如下图所示。
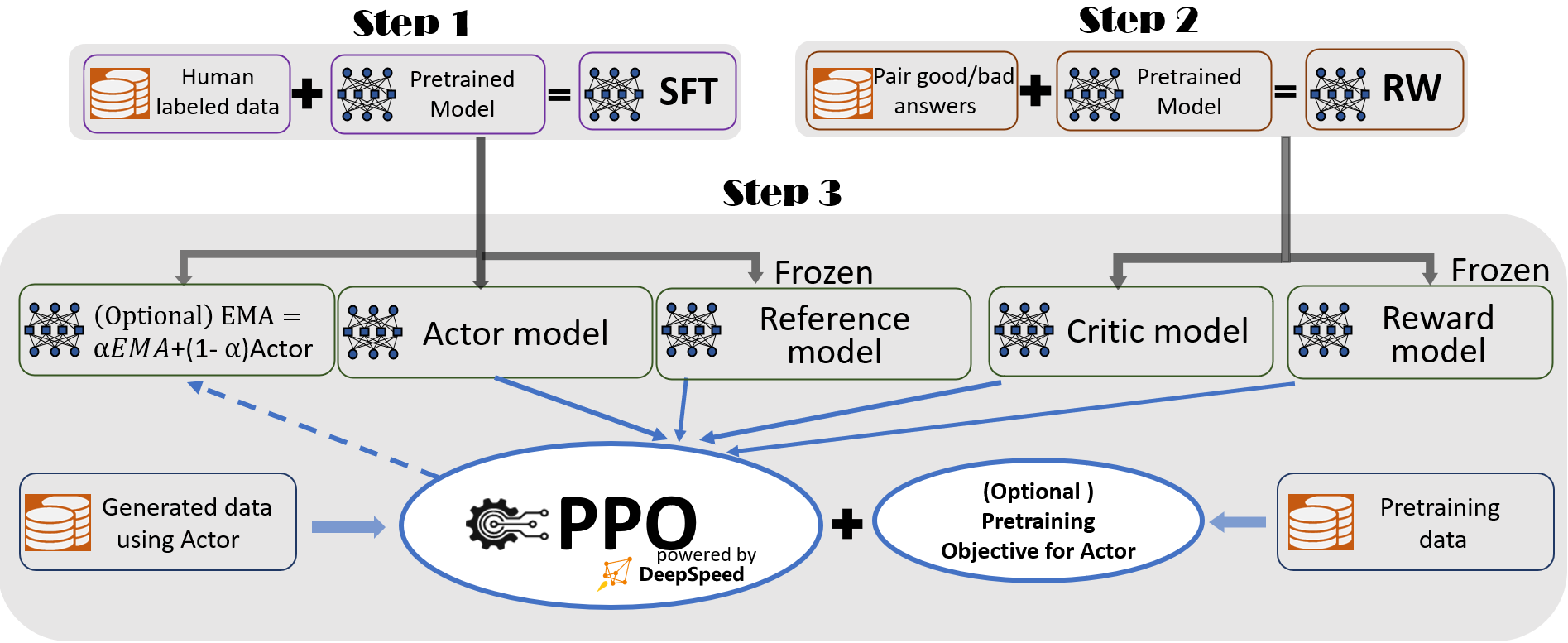
我们的流程包括三个主要步骤:
- 第一步:有监督微调(SFT),在此步骤中,人类对各种查询的响应被精心选择以微调预训练的语言模型。
- 第二步:奖励模型微调,对一个单独的模型(通常比SFT小)(RW)进行训练,该模型使用一个数据集,其中包含对多个答案的人类提供的排名,以响应同一个查询。
- 第三步:RLHF训练,使用近端策略优化(PPO)算法,使用RW模型的奖励反馈进一步微调SFT模型。 我们在第三步中提供了两个额外功能来帮助提高模型质量:
- 指数移动平均值(EMA)收集,在这里可以选择基于EMA的检查点进行最终评估。
- 混合训练,将预训练目标(即,下一个单词预测)与PPO目标混合,以防止在公共基准测试(如SQuAD2.0)上回归性能。
这两个训练功能,EMA和混合训练,通常被其他最近的工作省略,因为它们是可选的。但是,根据InstructGPT的说法,EMA检查点通常比传统的最终训练模型提供更好的响应质量,混合训练可以帮助模型保留预训练基准解决能力。因此,我们为用户提供这些功能,以完全获得InstructGPT描述的训练体验,并致力于实现更高的模型质量。
除了与InstructGPT文献高度一致外,我们还提供了便捷的功能,以支持研究人员和实践者使用多个数据资源训练自己的RLHF模型:
数据抽象和混合能力:DeepSpeed-Chat可以使用多个数据集训练模型,以获得更好的模型质量。它配备了(1)一个抽象数据集层,以统一不同数据集的格式;(2)数据分割/混合能力,使多个数据集得到适当地混合然后分割到3个训练阶段中。 为了说明我们的训练流程的有效性,我们展示了多轮对话中的模型质量,如体验部分所示。
Instruct-guided RLHF流程的第一步和第二步类似于大模型的常规微调,它们由DeepSpeed训练中的ZeRO优化和并行策略的灵活组合提供动力,以实现规模和速度。另一方面,流程的第三步在性能影响方面是最复杂的部分。每个迭代需要高效处理两个阶段:a)用于令牌/经验生成的推理阶段,生成用于训练的输入;b)用于更新演员和奖励模型的权重的训练阶段,以及它们之间的交互和调度。它引入了两个主要成本:(1)内存成本,因为SFT和RW模型的多个副本需要在阶段3中服务;(2)主要的生成阶段,如果没有正确加速,将显着减慢整个阶段3的速度。另外,我们在第三阶段添加的两个重要功能,包括指数移动平均(EMA)收集和混合训练,将产生额外的内存和训练成本。
为了解决这些挑战,我们将DeepSpeed训练和推断的完整系统能力组合到一个统一的基础设施中,称之为“混合引擎”。它利用原始的DeepSpeed引擎进行快速训练,同时轻松应用DeepSpeed推理引擎进行生成/评估模式,为第3阶段的RLHF训练提供显着更快的训练系统。正如图2所示,DeepSpeed训练和推理引擎之间的过渡是无缝的:通过在演员模型启用典型的评估和训练模式,在运行推理和训练流程时,DeepSpeed选择其不同的优化来加速模型运行并提高整个系统吞吐量。
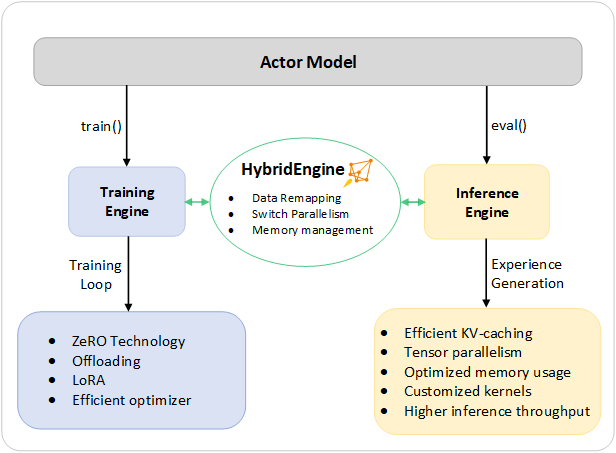
在RLHF训练的经验生成阶段执行推理时,DeepSpeed混合引擎使用轻量级内存管理系统来处理KV-cache和中间结果,以及高度优化的推理适配核心和张量并行实现,相比现有解决方案,可以显著提高吞吐量(每秒生成令牌数)。
在训练执行期间,混合引擎启用内存优化技术,例如DeepSpeed的ZeRO技术族和Low Rank Adaption(LoRA)。我们设计并实现了这些系统优化,使它们彼此兼容,可以组合在一起,以在统一的混合引擎下提供最高的训练效率。
混合引擎可以无缝切换模型划分,以支持基于张量并行的推理和基于ZeRO的分片机制进行训练。它还可以重新配置内存系统,在每种模式下最大限度地提高内存可用性。这可以通过避免内存分配瓶颈并支持大批量处理,实现改进的性能。混合引擎集成了来自DeepSpeed训练和推理的一系列系统技术,将现代RLHF训练的界限推向前沿,并为RLHF工作负载提供无与伦比的规模和系统效率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢