
Free Dolly:介绍世界上第一个真正开放的 Instruction-Tuned LLM
2023 年 4 月 12 日 databricks公司博客
两周前,我们发布了Dolly,这是一种大型语言模型 (LLM),其训练成本不到 30 美元,可以展示类似 ChatGPT 的人类交互性(也称为指令遵循)。今天,我们发布了Dolly 2.0,这是第一个开源的指令跟随法学硕士,它在人类生成的指令数据集上进行了微调,该数据集已获得许可用于研究和商业用途。
Dolly 2.0 是一个 12B 参数语言模型,它基于EleutherAI pythia模型系列,并专门根据 Databricks 员工众包的新的、高质量的人工生成指令跟随数据集进行了微调。
我们正在开源整个 Dolly 2.0,包括训练代码、数据集和模型权重,所有这些都适合商业使用。这意味着任何组织都可以创建、拥有和定制强大的 LLM,这些 LLM 可以与人们交谈,而无需支付 API 访问费用或与第三方共享数据。
databricks-dolly-15k数据集
databricks-dolly-15k包含 15,000 个高质量的人工生成的提示/响应对,专为指令调优大型语言模型而设计。databricks-dolly-15k根据(Creative Commons Attribution-ShareAlike 3.0 Unported License )的许可条款,任何人都可以出于任何目的使用、修改或扩展此数据集,包括商业应用程序。
据我们所知,该数据集是第一个开源的、人工生成的指令数据集,专门用于让大型语言模型展现 ChatGPT 神奇的交互性。由 5,000 多名 Databricks 员工在 2023 年 3 月和 4 月期间编写。这些培训记录自然、富有表现力,旨在代表广泛的行为,从头脑风暴和内容生成到信息提取和总结。databricks-dolly-15k
我们为什么要创建一个新的数据集?
当我们发布 Dolly 1.0 后,我们就被想要试用它的人们的请求淹没了。我们不断收到的第一个问题是“我可以将其用于商业用途吗?”
创建 Dolly 1.0 或 LLM 之后的任何指令的关键步骤是在指令和响应对的数据集上训练模型。Dolly 1.0 使用斯坦福羊驼团队使用 OpenAI API 创建的数据集进行训练,费用为 30 美元。该数据集包含 ChatGPT 的输出,正如斯坦福团队指出的那样,服务条款试图阻止任何人创建与 OpenAI 竞争的模型。所以,不幸的是,这个常见问题的答案是,“可能不会!”
据我们所知,所有现有的知名指令跟随模型(Alpaca、Koala、GPT4All、Vicuna)都受到此限制,禁止商业使用。为了解决这个难题,我们开始寻找方法来创建一个新的数据集,而不是“污染”用于商业用途。
我们是怎么做的?
我们从 OpenAI 研究论文中了解到,原始 InstructGPT 模型是在一个包含 13,000 个指令遵循行为演示的数据集上训练的。受此启发,我们着手看看是否可以让 Databricks 员工带头取得类似的结果。
事实证明,生成 13k 个问题和答案比看起来要难。每个答案都必须是原创的。它不能从 ChatGPT 或网络上的任何地方复制,否则会污染我们的数据集。这看起来令人望而生畏,但 Databricks 拥有超过 5,000 名对 LLM 非常感兴趣的员工。所以我们认为我们可以在他们之间进行众包,以创建比 40 个标记器为 OpenAI 创建的质量更高的数据集。但我们知道他们都很忙并且有全职工作,所以我们需要激励他们这样做。
我们举办了一场比赛,前 20 名贴标签者将获得大奖。我们还概述了 7 项非常具体的任务:
- 开放问答:比如“为什么人们喜欢喜剧电影?” 或“法国的首都是哪里?” 在某些情况下,没有正确的答案,而在另一些情况下,则需要借鉴整个世界的知识。
- 封闭式问答:这些问题只能使用参考文本中包含的信息来回答。例如,给出维基百科中关于原子的一段,人们可能会问,“原子核中质子和中子的比例是多少?”
- 从维基百科中提取信息:注释者将从维基百科中复制一个段落,并从该段落中提取实体或其他事实信息,例如重量或测量值。
- 总结来自维基百科的信息:为此,注释者提供了一段来自维基百科的文章,并被要求将其提炼成简短的摘要。
- 头脑风暴:此任务要求开放式构思和相关的可能选项列表。例如,“这个周末我可以和朋友一起做哪些有趣的活动?”。
- 分类:对于此任务,注释者被要求对类别成员进行判断(例如,列表中的项目是动物、矿物或蔬菜)或判断短文本的属性,例如电影评论的情感。
- 创意写作:这项任务包括写一首诗或一封情书。
databricks-dolly-15k中的开放式 QA 示例

databricks-dolly-15k中的头脑风暴示例

我们最初怀疑我们是否会获得 10,000 个结果。但通过夜间排行榜游戏化,我们在一周内成功打破了 15,000 个结果。由于害怕影响我们的生产力,我们结束了比赛。
我们创建商业上可行的模型的旅程
我们还想制作一个可以商业使用的开源模型。尽管databricks-dolly-15kDolly 1.0 在其上训练的数据集 Alpaca 小得多,但基于EleutherAI 的 pythia-12b生成的 Dolly 2.0 模型表现出高质量的指令遵循行为。事后看来,这并不奇怪。最近几个月发布的许多指令调优数据集都包含合成数据,这些数据通常包含幻觉和事实错误。
databricks-dolly-15k另一方面,它是由专业人士生成的,质量很高,并且包含对大多数任务的长答案。
您可以亲自查看一些示例,了解如何使用 Dolly 2.0 进行摘要和内容生成。根据我们最初的客户反馈,很明显,诸如此类的功能将在整个企业中得到广泛应用。
Dolly 2.0 总结 Databricks 文档
多莉 2.0 总结了一张客户支持票

Dolly 2.0 为推文生成内容

真正开放的大型语言模型
我们反复从客户那里听说,拥有自己的模型会为他们提供最好的服务,使他们能够为其特定领域的应用程序创建更高质量的模型,而无需将敏感数据移交给第三方。
我们还认为,偏见、问责制和人工智能安全等重要问题应该由不同利益相关者组成的广泛社区来解决,而不仅仅是少数大公司。开源数据集和模型鼓励评论、研究和创新,这将有助于确保每个人都能从人工智能技术的进步中受益。
作为技术和研究神器,我们并不期望 Dolly 在有效性方面是最先进的。然而,我们确实希望 Dolly 和开源数据集将作为大量后续工作的种子,这可能有助于引导更强大的语言模型。
今天我该如何开始?
要下载 Dolly 2.0 模型权重,只需访问Databricks Hugging Face页面并访问databricks-labs 上的 Dolly 存储库以下载databricks-dolly-15k dataset. 并加入我们的网络研讨会,了解如何为您的组织利用 LLM。
关于dolly-v2-12b介绍——dolly-v2-12b
概括
Databricks的dolly-v2-12b,是一个在Databricks机器学习平台上训练的指令跟随型大型语言模型,,在已获得商业使用许可的 Databricks 机器学习平台上进行训练。基于pythia-12b,Dolly 接受了 databricks-dolly-15kDatabricks 员工在 InstructGPT 论文的能力域中生成的约 15k 指令/响应微调记录的训练,包括头脑风暴、分类、封闭 QA、生成、信息提取、开放 QA 和总结。dolly-v2-12b不是最先进的模型,但确实表现出令人惊讶的高质量指令遵循行为不是它所基于的基础模型的特征。
所有者:Databricks, Inc.
型号概览
dolly-v2-12b是由Databricks创建的 120 亿参数因果语言模型,它源自 EleutherAI 的 Pythia-12b,并在由 Databricks 员工生成并在许可 (CC-BY-SA) 下发布的约 15K 记录指令语料库上进行了微调
用法
transformers要在配备 GPU 的机器上将模型与库一起使用:
from transformers import pipeline
instruct_pipeline = pipeline(model="databricks/dolly-v2-12b", trust_remote_code=True, device_map="auto")
然后您可以使用管道来回答指令:
instruct_pipeline("Explain to me the difference between nuclear fission and fusion.")
为了减少内存使用,您可以使用以下方式加载模型bfloat16:
import torch
from transformers import pipeline
instruct_pipeline = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
已知限制
性能限制
dolly-v2-12b不是最先进的生成语言模型,尽管正在进行定量基准测试,但其设计目的并不是为了与更现代的模型架构或受更大预训练语料库影响的模型竞争。
Dolly 模型系列正在积极开发中,因此任何缺点列表都不可能详尽无遗,但我们在此处包括已知的限制和失误,作为记录和与社区分享我们的初步发现的一种方式。
特别是,dolly-v2-12b挣扎于:语法复杂的提示、编程问题、数学运算、事实错误、日期和时间、开放式问题回答、幻觉、特定长度的枚举列表、文体模仿、幽默感等。此外,我们发现它dolly-v2-12b不具备原始模型中存在的某些功能,例如格式良好的字母书写。
数据集限制
与所有语言模型一样,dolly-v2-12b反映了其训练语料库的内容和局限性。
-
The Pile:GPT-J 的预训练语料库包含主要从公共互联网收集的内容,并且像大多数网络规模的数据集一样,它包含许多用户会反感的内容。因此,该模型可能会反映这些缺点,在明确要求生成令人反感的内容的情况下可能是公开的,有时是微妙的,例如在有偏见或有害的隐式关联的情况下。
-
databricks-dolly-15k:指令调整的训练数据dolly-v2-12b代表 Databricks 员工在 2023 年 3 月和 2023 年 4 月期间生成的自然语言指令,包括来自维基百科的段落作为指令类别的参考段落,如封闭式 QA 和摘要。据我们所知,它不包含关于非公众人物的淫秽、知识产权或个人身份信息,但它可能包含拼写错误和事实错误。数据集也可能反映维基百科中发现的偏见。最后,该数据集可能反映了 Databricks 员工的兴趣和语义选择,这是一个不能代表全球总体人口的人口统计数据。
Databricks 致力于持续的研发工作,以开发有用、诚实和无害的人工智能技术,最大限度地发挥所有个人和组织的潜力。
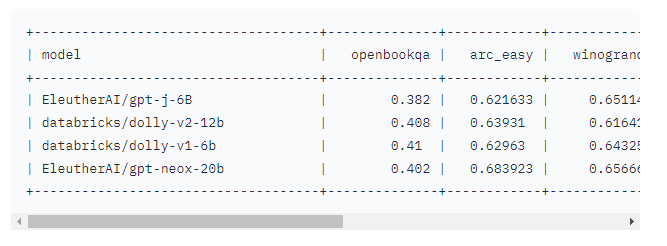
基准指标
您将在下面找到EleutherAI LLM Evaluation Harness上的各种模型基准性能;模型结果按几何平均数排序以产生可理解的排序。如上所述,这些结果表明这dolly-v2-12b不是最先进的,实际上dolly-v1-6b在某些评估基准中表现不佳。我们认为这归因于基础微调数据集的组成和大小,但关于这些变化来源的可靠声明需要进一步研究。
相关资讯:
Databricks 发布 Dolly 2.0,这是第一个用于商业用途的开放式指令遵循型语言大模型
今天Databricks发布了 Dolly 2.0,这是该公司两周前 发布的具有类似于 ChatGPT 的人类交互性(又名指令遵循)的大型语言模型 (LLM) 的下一个版本。
该公司表示,Dolly 2.0 是第一个开源、遵循指令的LLM,它在透明且免费提供的数据集上进行了微调,该数据集也是开源的,可用于商业目的。这意味着 Dolly 2.0 可用于商业应用程序,无需支付 API 访问费用或与第三方共享数据。
根据 Databricks 首席执行官 Ali Ghodsi 的说法,虽然还有其他 LLM 可以用于商业目的,但“他们不会像 Dolly 2.0 那样与你交谈。” 而且,他解释说,用户可以修改和改进训练数据,因为它是在开源许可下免费提供的。“所以你可以制作你自己的多莉版本,”他说。
Databricks 发布数据集 Dolly 2.0 用于微调
Databricks 表示,作为其对开源的持续承诺的一部分,它还发布了 Dolly 2.0 在其上进行微调的数据集,称为 databricks-dolly-15k。这是由数千名 Databricks 员工生成的超过 15,000 条记录的语料库,Databricks 称这是“第一个开源的、人工生成的指令语料库,专门设计用于让大型语言能够展示 ChatGPT 的神奇交互性。”
在过去的两个月里出现了一波遵循指令的、类似于 ChatGPT 的 LLM 版本,这些版本被许多定义视为开源(或提供某种程度的开放性或门控访问)。一个是 Meta 的 LLaMA,它反过来启发了其他人,如 Alpaca、Koala、Vicuna 和 Databricks 的 Dolly 1.0。
然而,Ghodsi 说,许多这些“开放”模型都处于“工业捕获”之下,因为它们接受了旨在限制商业用途的条款的数据集的训练——例如来自斯坦福羊驼项目的 52,000 个问答数据集它是根据 OpenAI 的 ChatGPT 的输出进行训练的。但他解释说,OpenAI 的使用条款包括一条规则,即您不能使用与 OpenAI 竞争的服务的输出。
然而,Databricks 想出了解决这个问题的方法:Dolly 2.0 是一个 120 亿参数的语言模型,它基于开源Eleuther AI pythia模型系列,并专门针对小型开源指令记录语料库进行了微调(databricks-dolly-15k) 由 Databricks 员工生成。该数据集的许可条款允许出于任何目的使用、修改和扩展它,包括学术或商业应用。
到目前为止,在 ChatGPT 输出上训练的模型一直处于合法的灰色地带。“整个社区一直在小心翼翼地解决这个问题,每个人都在发布这些模型,但没有一个可以用于商业用途,”Ghodsi 说。“所以这就是我们超级兴奋的原因。”
Dolly 2.0 小而强大
Databricks 的一篇博客文章强调,与最初的 Dolly 一样,2.0 版本并不是最先进的,但“在给定训练语料库的规模的情况下,表现出令人惊讶的指令遵循行为水平。” 该帖子补充说,构建强大的人工智能技术所需的努力和费用水平“比以前想象的要少几个数量级”。
“其他人都想变大,但我们实际上对变小感兴趣,”Ghodsi 谈到 Dolly 的小尺寸时说。“其次,它是高质量的。我们查看了所有答案。”
Ghodi 补充说,他相信 Dolly 2.0 将产生“滚雪球”效应——AI 社区中的其他人可以加入并提出其他替代方案。他解释说,商业用途的限制是一个需要克服的巨大障碍:“我们现在很兴奋,因为我们终于找到了绕过它的方法。我保证你会看到人们将 15,000 个问题应用于现有的每个模型,他们会看到其中有多少模型突然变得有点神奇,你可以在其中与它们互动。”
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢