
论文标题:
Segment Everything Everywhere All at Once
论文背景:
尽管对交互式人工智能系统的需求越来越大,但在视觉理解(如分割)方面,关于人与人工智能的交互的全面研究还很少。受为LLMs开发的基于提示的通用界面的启发,本文提出了SEEM,一个可提示的交互式模型,用于在图像中一次将所有东西都分割开来。
SEEM是一种交互式模型,通过多种提示方式,一次性地对图像中所有物体进行分割,并在通用语义空间中学习联合视觉-语义表示,具有高效、可扩展性和可交互性。
SEEM有四个目标:
i)通用性:通过引入一个通用的提示引擎,用于不同类型的提示,包括点、框、涂鸦、面具、文本和另一个图像的参考区域;
ii)组合性:通过学习视觉和文本提示的联合视觉-语义空间,在推理中快速组成查询,如图1所示;iii)互动性:
iii)交互性:通过面具引导的交叉注意力,将可学习的记忆提示用于保留对话历史信息;
iv)语义意识:通过使用文本编码器来编码文本查询和用于开放词汇分割的面具标签。
论文作者:
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, Yong Jae Lee
[University of Wisconsin-Madison & Microsoft Research at Redmond & HKUST]

2023年04月27日11:00-12:00,我们将邀请本论文的第一作者,威斯康辛大学麦迪逊分校的博士研究生邹雪妍进行分享。本期作者将介绍在X-Decoder和SEEM中探索了如何统一多种任务和多个模态,使用同一个模型同一组参数理解多种任务和模态成为可能。
报告名称:
X-Decoder&SEEM: 从开放词库的图像理解到像素分割,如何用一个模型做N个任务理解M个模态
报告链接:
https://event.baai.ac.cn/activities/675
报告时间:
2023年4月27日11点
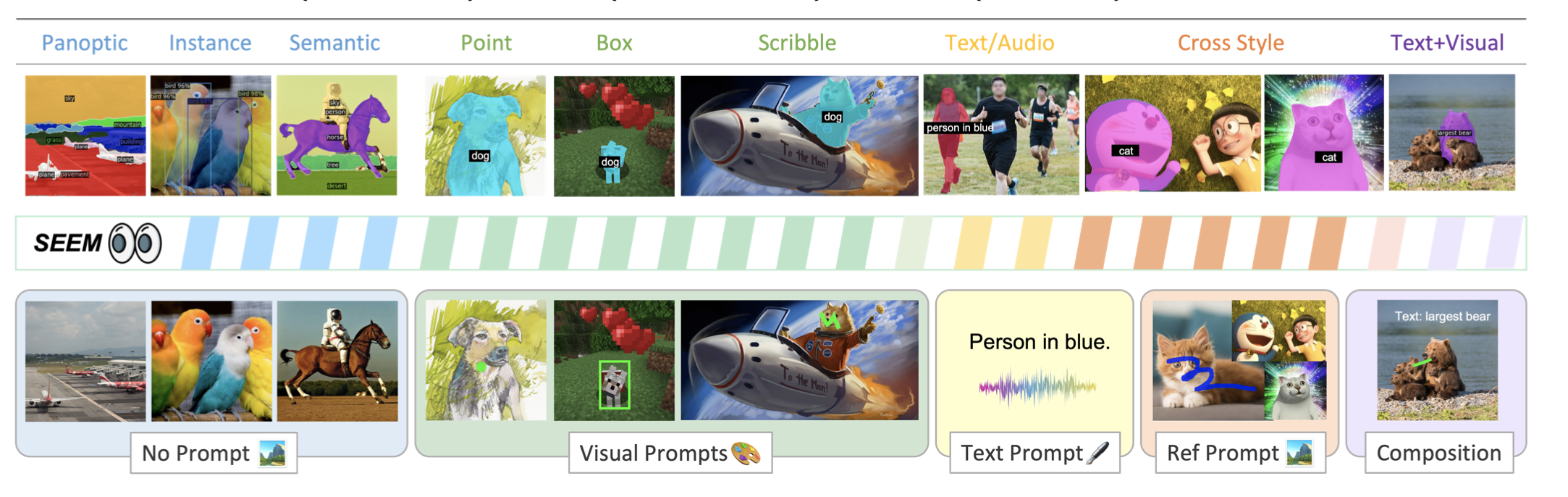
动机:
为满足交互式AI系统对视觉理解分割的需求,开发一种可以多种提示方式、在通用语义空间中学习联合视觉-语义表示的交互式模型。
方法:
提出一种通用的提示方案,将用户的意图编码成联合视觉-语义空间中的提示,并通过轻量解码器将其整合为多种类型的分割任务的可用的提示。
优势:
SEEM可以用多种提示方式对图像中所有的物体进行一次性的分割,并具有高效、可扩展性和可交互性,能适应各种提示方式,并在通用语义空间中学习联合视觉-语义表示,能够很好地适应未知提示。

加入交流群
获得直播消息&学术交流讨论
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢