
Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
[University of Wisconsin–Madison & Microsoft Research & Columbia University]
视觉指令微调
论文地址:https://arxiv.org/abs/2304.08485
项目地址:https://llava-vl.github.io
使用机器生成的指令跟踪数据进行指令调整大语言模型(LLM)改进了语言领域新任务的零命中能力,但这一想法在多模态领域较少被探索。
-
- 多模态指令数据。我们首次尝试使用仅限语言的GPT-4来生成多模态语言图像指令跟踪数据。
- LLaVA模型。我们引入了LLaVA(大型语言和视觉助理),这是一个端到端训练的大型多模态模型,将视觉编码器和LLM连接起来,用于通用视觉和语言理解。
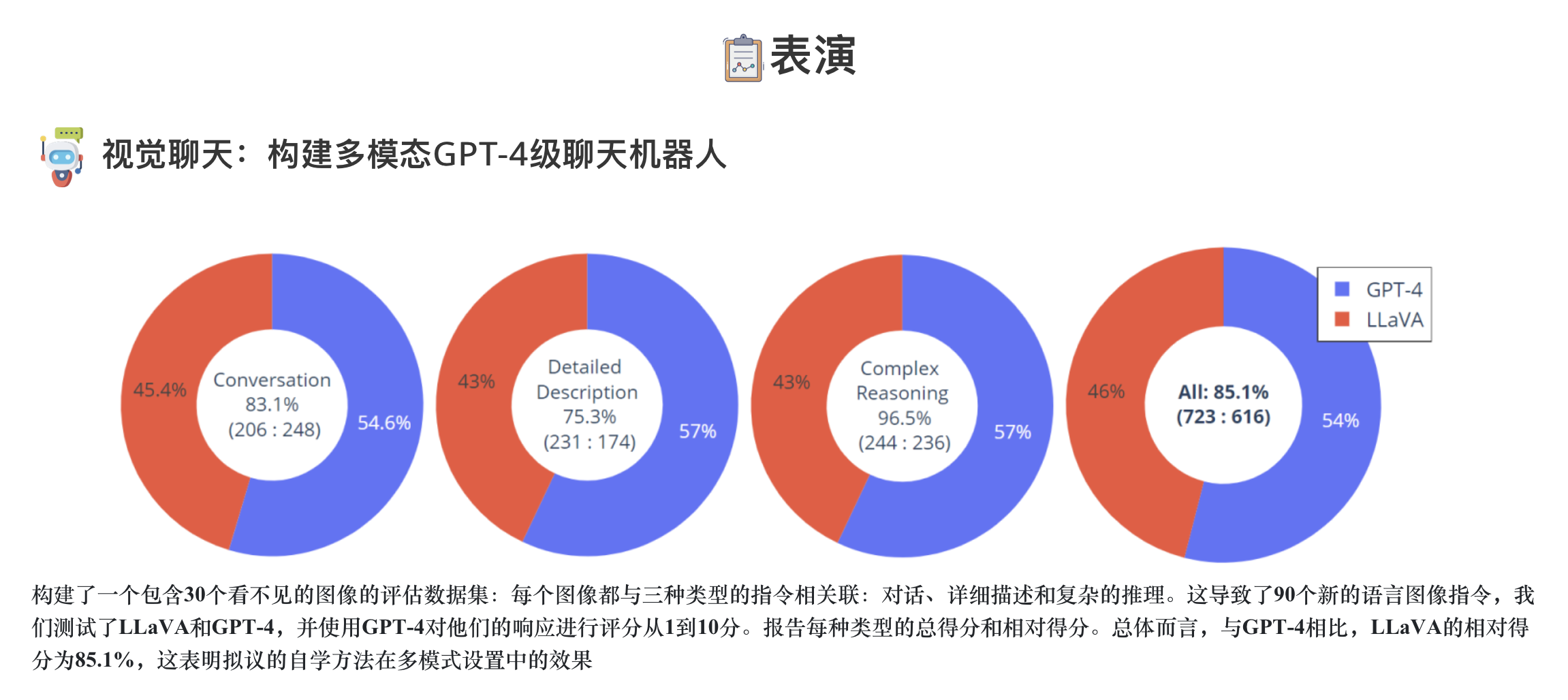
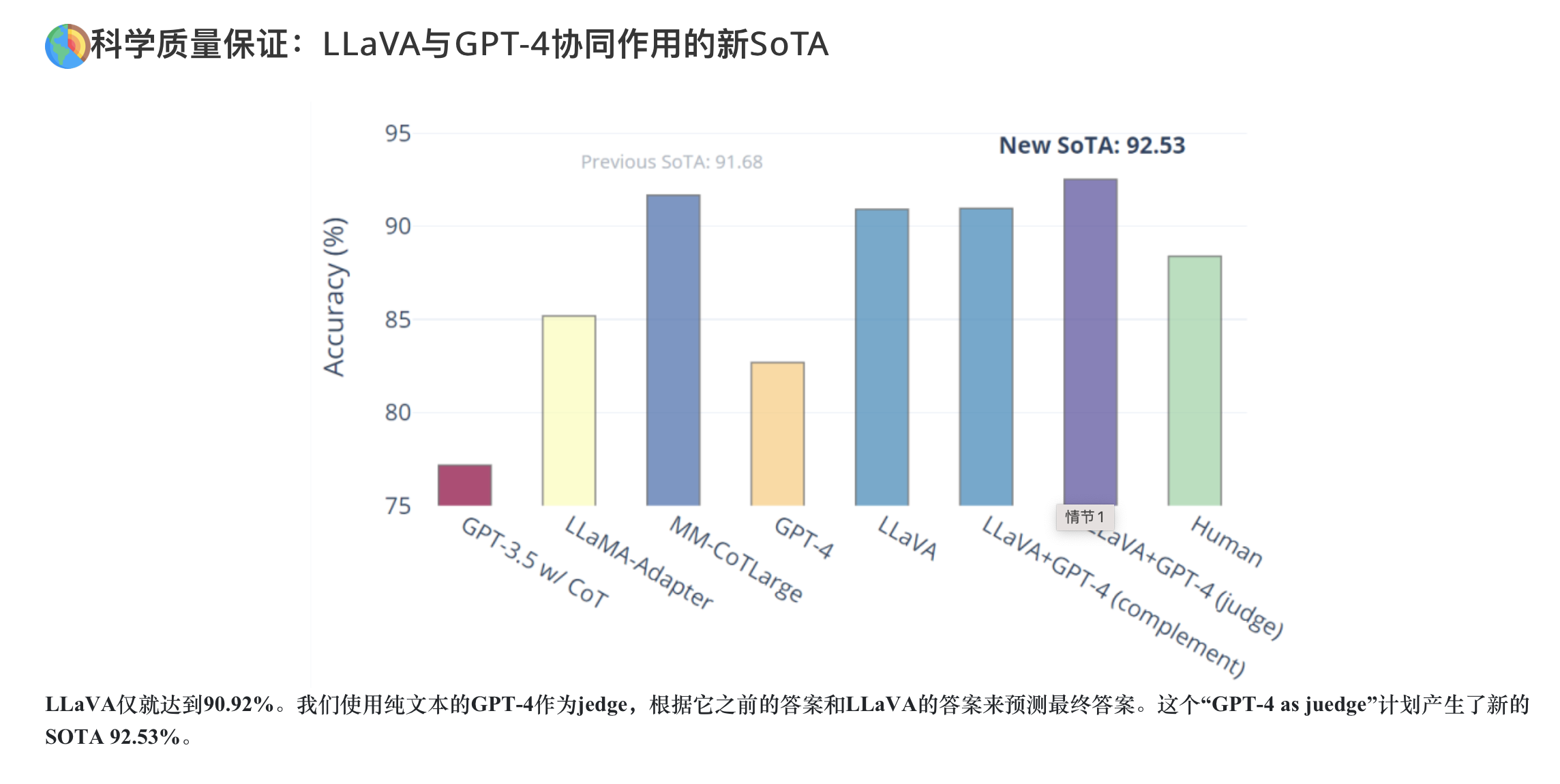
- 性能。我们早期的实验表明,LLaVA展示了令人印象深刻的多模型聊天能力,有时在看不见的图像/指令上表现出多模态GPT-4的行为,与合成多模态指令跟踪数据集的GPT-4相比,得出了85.1%的相对分数。当对科学质量保证进行微调时,LLAVA和GPT-4的协同作用实现了92.53%的新最先进的精度。
- 开源。我们公开了GPT-4生成的视觉指令调优数据、我们的模型和代码库。
用语言生成数据对多模态语言图像指令进行微调,提出一种名为LLaVA的大型多模态模型,连接视觉编码器和大型语言模型,用于通用的视觉和语言理解。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢