
【多模态预训练模型】X-LXMERT:使用多模态Transformer绘制、描述和回答问题(EMNLP 2020) 【论文标题】X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers 【作者团队】Jaemin Cho, Jiasen Lu, Dustin Schwenk, Hannaneh Hajishirzi, Aniruddha Kembhavi 【发表时间】2020/9/23 【论文链接】https://arxiv.org/abs/2009.11278v1 【推荐理由】 如何用多模态预训练模型从文本生成丰富且具有语义的图像,让我们看看EMNLP 2020中艾伦人工智能研究院卢家森团队是如何通过改进LXMERT模型实现的?
目前的多模态预训练模型例如VILBERT,LXMERT和UNITER在视觉问答,视觉因果等任务中已经取得了很好的性能,但是目前多模态预训练模型还无法得知是否能从文本片段生成相应的图像,于是作者通过对LXMERT实验发现现在的模型在已有的训练设置下,无法通过文本段生成丰富且由语义的图像。
在这个问题的启发下,作者团队在LXMERT基础上设计了X-LXMERT(如图),主要做的改进包括:1.增加了离散化的视觉表示 2.使用具有大范围遮盖率的均匀Mask任务 3.对齐与训练数据集和正确目标对保证图像能够绘制。
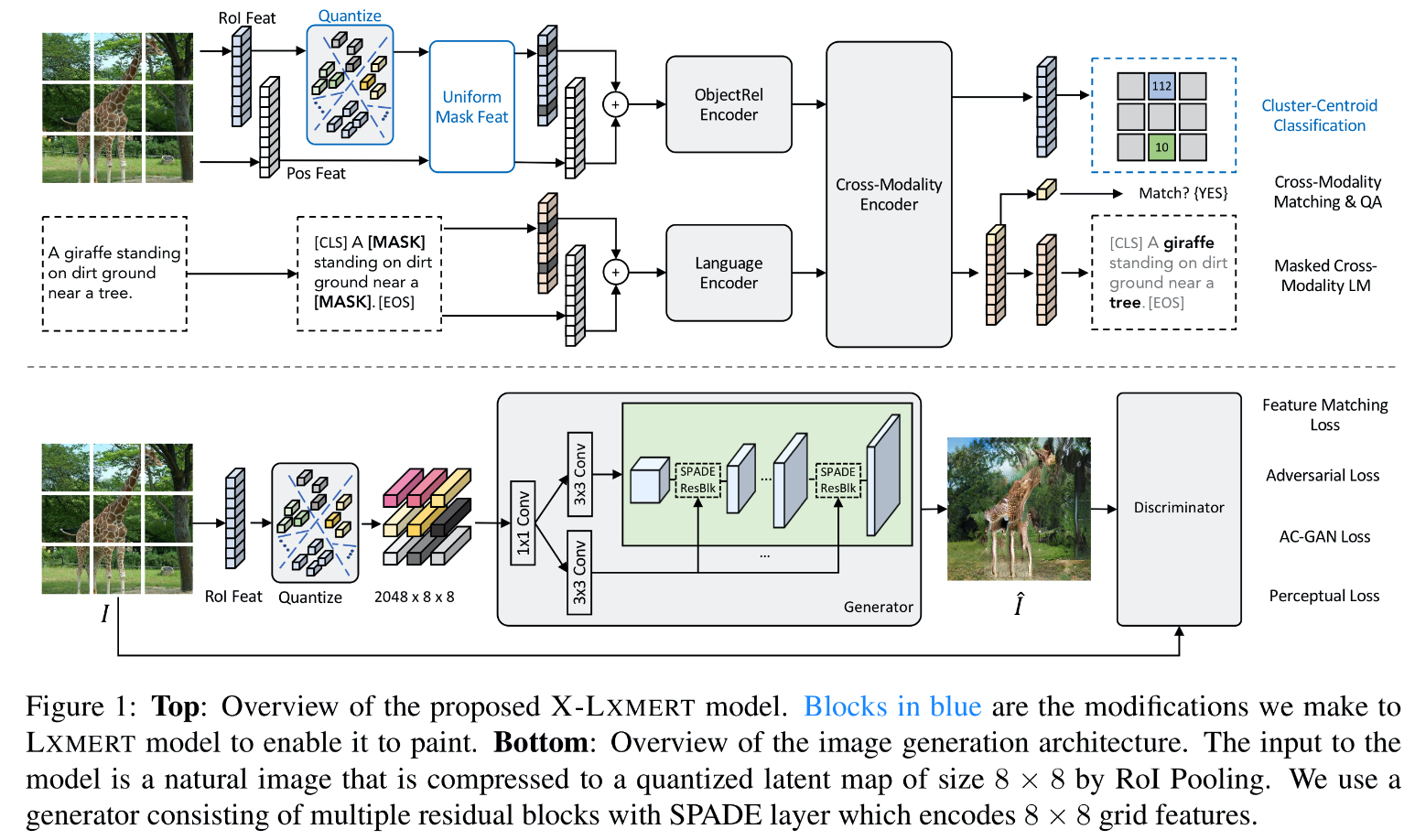
X-LXMERT的图像生成效果可与最新的图像生成模型相媲美,而且他的视觉问答和图像字幕等任务效果仍然和LXMERT保持一致,
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢