
ChatGPT 出现后的这几个月,整个学界和业界的疯狂想必大家都已经看到了。
然而,在背各种各样的动物还有山海经怪兽的英语单词的时候,其实不妨停下来想一想复现中文 ChatGPT 到底缺什么?缺大模型吗?缺工程经验吗?缺 trick 吗?缺算力吗(确实缺...)?
先来看看比较火的那些“动物”做了什么:Alpaca[1](羊驼)用语言模型生成了一些指令数据,Baize[2](白泽)用 ChatGPT 生成了一些对话数据,Vicuna[3](小羊驼)用 ShareGPT 数据 (ChatGPT 用户分享的对话记录) 复现了不少 ChatGPT 效果......
种种迹象表明,数据还是那个最珍贵的资源。那什么样的数据更重要呢?
再来看看 ChatGPT 的关键几步:(1)大规模语料预训练;(2)监督指令精调(Supervised Instruction Fine-Tuning);(3)基于人类反馈的强化学习(RLHF)
对于(1)来说,中文其实不缺,从互联网上爬就是了;对于(3)而言,人工打分标注的成本相对而言低一些。所以,主要是指令数据的稀缺,导致语言模型精调的时候无法获得足够的监督训练,而且,还影响了后续 RLHF 的输入指令集的筹备。要知道,指令精调给模型带来的指令遵循能力,是具有很强的泛化性的,这样模型才能够更好地泛化到用户多种多样的指令上去(参考[4])。
可惜的是,相比于英文来说,开源的、大规模的中文指令数据实在是太少了......
因此,本文给大家推荐这么一批珍贵的中文数据:Chinese Open Instruction Generalist(COIG)第一期!
第一期总共发布了 5 个子数据集,包括翻译指令、考试指令、人类价值观对齐指令、反事实修正多轮聊天、Leetcode指令,总计 191k 数据,聚焦中文语料、数据类型多样、经过了人工质检与修正、数据质量可靠,而且可以商用。
论文标题:
Chinese Open Instruction Generalist: a Preliminary Release
论文机构:
北京智源人工智能研究院等
论文链接:
https://arxiv.org/pdf/2304.07987.pdf
数据链接:
https://huggingface.co/datasets/BAAI/COIG
经过人工验证的翻译通用指令(67,798)
作者对三个数据集进行了翻译工作,包括具有1,616个任务描述和示例的Super-Natural Instructions数据集,175个种子任务的Self-Instruct数据集,以及66,007个指令的Unnatural Instructions数据集。整个翻译过程分为自动翻译、人工验证和人工修正三个阶段,以确保翻译结果的准确性和可靠性。
在自动翻译阶段,作者将指令和实例的输入输出组合在一起,然后使用 DeepL 进行翻译。
在人工验证阶段,作者为注释者定义了四个标签,根据指令是否可用和需要的修正程度进行分类。作者使用两阶段质量验证方法进行人工验证,第一阶段由经验丰富的质量检查员进行验证,只有正确率超过95%的案例才能进入第二阶段。在第二阶段,专家质量检查员从总语料库中随机抽取200个案例进行验证。
在人工修正阶段,注释者需要将翻译后的指令和实例纠正为正确的中文三元组{指令,输入,输出},而不仅仅是保持翻译的准确性。这是因为在 unnatural instructions 中存在事实错误,这可能会导致LLMs出现 hallucination. 作者同样使用两阶段质量验证方法进行人工修正,第一阶段的正确率为97.24%。
人工注释的考试指令(63,532)
中国的高考、中考和公务员考试题目中包含各种问题类型和详细的分析,这些考试可以用来构建思维链(CoT)语料库用于增强模型推理能力。作者从这些考试中提取了六个信息元素,包括指令、问题背景、问题、答案、答案分析和粗粒度学科。这些语料库中的六个主要学科是语文、英语、政治、生物、历史和地质。数学、物理和化学问题很少在语料库中出现,因为这些问题通常包含难以注释的复杂数学符号。
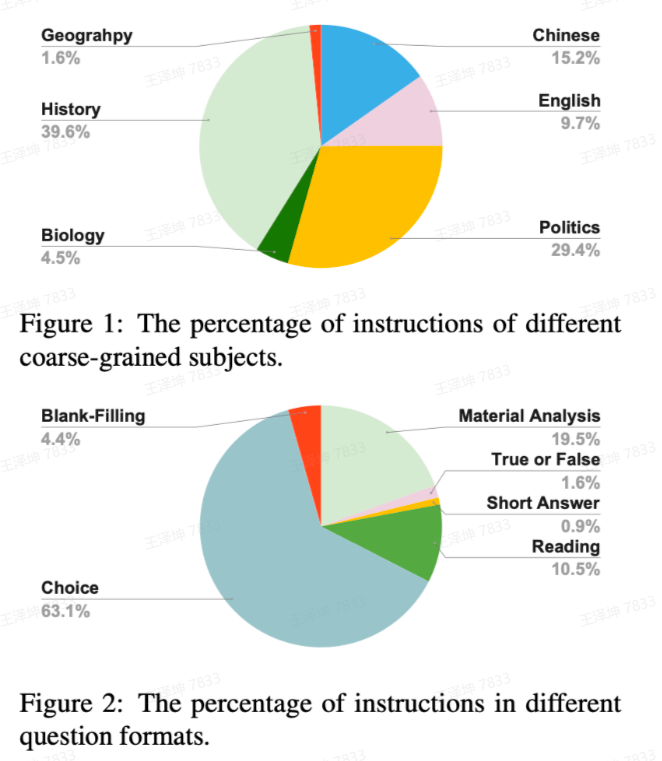
人类价值观对齐指令(34,471)
为了尊重和反映不同文化背景所带来的主要差异,COIG数据集中的价值观对齐数据被分为两个独立的系列:
一组展示中文世界共享人类价值观的样本。作者选择了50个指令作为扩充种子,并使用中文世界通用的价值观对齐样本,生成了3,000个结果指令。另外一些展示特定区域文化或国家特定人类价值观的样本集。以下是数据示例:

反事实修正多轮聊天(13,653)
反事实修正多轮聊天数据集(CCMC)是基于CN-DBpedia知识图谱数据集构建的,旨在解决当前LLM中出现的幻觉和事实不一致的问题。数据集包含约13,000个对话,每个对话平均有5轮,共约65,000轮聊天。这些对话是在学生和教师之间进行的角色扮演聊天,他们在对话中参考相关的知识。

Leetcode 指令(11,737)
考虑到与代码相关的任务可能有助于LLM能力的涌现,作者从CC-BY-SA-4.0许可下的2,589个编程问题中构建Leetcode指令。这些问题包含问题描述、多种编程语言和解释(其中 834个问题尚没有解释)。编程语言分类统计如下图所示:
结语
COIG 是目前首个指令类型丰富且可商用的中文指令集,作者欢迎大家加入共建,一起扩充指令数据集类型和规模!
[1] Alpaca: https://github.com/tatsu-lab/stanford_alpaca
[2] Baize: https://arxiv.org/pdf/2304.01196.pdf
[3] Vicuna: https://vicuna.lmsys.org/
[4] https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
更多精彩
智能体自己玩转《我的世界》强化学习+ChatGPT,智源Plan4MC攻克24项复杂任务,当前最优表现!
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢