
Machine Intelligence Research
近年来,自监督学习(SSL)在推荐算法系统中的成效显著。但是,SSL推荐模型很可能由于存在虚假相关而导致泛化能力较差。为了减轻虚假相关性的影响,现有研究通常致力于基于ID的SSL推荐或利用特征工程来识别虚假特征。然而,基于ID的SSL方法牺牲了不变特征的优势,而特征工程方法需要借助高成本的人工标记来完成。
为了解决这些问题,本研究旨在自动减少虚假相关性的影响。实现这一目标需要:1)无需监督即可自动屏蔽虚假特征;2)在SSL过程中拦截虚假特征对其他特征产生的负面影响。为了应对这两个挑战,本文提出了一种不变特征学习框架,该框架首先将用户与物品间的交互分成多个具有分布迁移的环境,通过学习特征屏蔽机制来捕获不同环境中的不变特征。利用屏蔽机制可以去除虚假特征以进行鲁棒预测,并通过屏蔽机制引导的特征增强来阻止负面影响的传播。就两个数据集所进行的的大量实验证明了该框架在减轻虚假相关性影响和提高SSL模型泛化能力方面的有效性。相关成果已发表于MIR 2023年第二期专题中,全文开放获取!

图片来自Springer
全文下载:
Mitigating Spurious Correlations for Self-supervised Recommendation
Xin-Yu Lin, Yi-Yan Xu, Wen-Jie Wang, Yang Zhang, Fu-Li Feng
自监督学习(SSL)方法近年来已成为个性化推荐算法的前沿技术(SOTA)。SSL在推荐算法中的核心逻辑是通过额外的自分辨任务来学习更好的用户和物品表征,即通过对用户-物品特征或用户-物品交互图之间的增强进行对比,以发现其特征与交互之间的相关关系。尽管取得了很大成功,基于SSL的推荐模型依然由于将输入特征与交互相拟合而容易受到虚假相关性的影响。由于数据收集过程中存在选择偏差,训练数据中难免存在虚假相关性,其中一些虚假特征与用户交互(例如点击)显示出较强的相关性。如图1所示,具有4或6年工作经验的用户更容易与全职工作有交互,而具有5或7年工作经验的用户不容易与全职工作产生交互。但用户对全职工作的偏好不太可能因为一年的经验差距而产生显著改变,因此这种用户经验与交互之间的相关性是不可靠的。SSL模型倾向于通过自分辨任务来捕获这些虚假相关性,导致其泛化能力较差。
为减轻虚假相关性对SSL模型的不利影响,现有的解决方案主要分为三类:
1) 基于ID的SSL算法仅利用用户和物品的ID进行协同过滤,因此可以免受虚假特征带来的一些不利影响。然而,用户和物品特征对推荐算法是有帮助的,尤其适用于用户与物品交互很少的情况。一些具有因果性的不变特征会影响交互,因此也有必要被纳入考虑范围之内。例如,会计学生通常更喜欢会计相关的工作。
2) 借助特征工程方法可以通过人机结合的方法手动识别出一系列虚假特征。随后再通过丢弃识别出的特征来训练SSL推荐模型。然而,特征工程方法需要大量的人工标注工作,因此不适用于用户和物品特征过多的大规模推荐系统。
3) 有效信息特征选择法能够自动识别有用的特征,并在训练过程中删除冗余特征。例如,Liu等提出了一种两段式训练策略,通过正则化优化器识别有用的特征交互,并在删除所有冗余特征后重新训练模型。然而,虚假特征很可能会由于其与交互的虚假关联被识别成有用特征,从而极大地干扰训练数据中的交互预测,降低泛化能力。
要解决这些问题,就要让SSL模型自动减少虚假相关对其的影响。实现这一目标存在两个最主要的挑战:
1) 研究表明,在无监督的情况下屏蔽虚假特征是非常困难的。我们希望SSL推荐模型可以自动识别虚假特征,并得到更加可靠的预测结果。因此,应该从相关数据中发掘可用于帮助我们识别虚假特征的信号。
2) 拦截虚假特征对其他特征的影响至关重要。SSL模型通常会通过特征增强(如屏蔽相关特征)和对比学习来最大化特征间的互信息,因此其对虚假特征和其他相关特征可能具有相似的表征,将虚假特征的不利影响传递给其他特征。例如,图1中的用户体验可能与用户的年龄有关,对此,SSL模型很可能会通过自分辨来学习类似的表征。
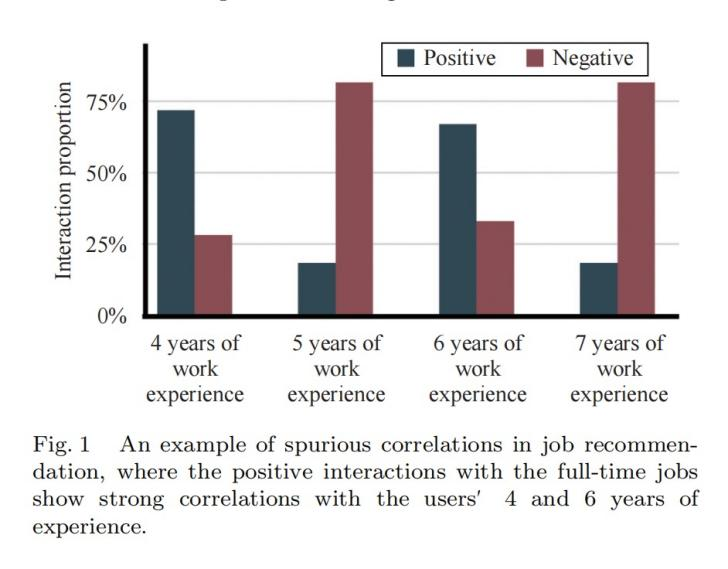
图1 工作推荐中的虚假相关示例,可见用户与全职工作的交互与其4年和6年经验有很强的相关性。
为破解这两个难题,本文试从多个场景中学习特征屏蔽机制,以估计出现虚假特征的概率,然后采用屏蔽机制来指导SSL模型的特征增强。具体来说,1) 可以将交互聚类到多个环境中,每个环境内具有相似的特征分布,但其在不同场景中会存在偏差。分布偏差将指导屏蔽机制捕捉不同场景中的不变特征并排除虚假特征。2) 此外,可以利用屏蔽机制把虚假特征丢弃并保留不变特征作为增强样本,然后最大化增强样本中不变特征与实际样本中所有输入特征之间的互信息,从而使SSL模型忽略虚假特征,并阻断虚假特征对不变特征的负面影响。
为此,文章提出了一个不变特征学习(IFL)框架,以帮助SSL推荐模型减少虚假相关性。具体而言,IFL将训练交互分成多个环境,并利用可训练的屏蔽机制来屏蔽虚假相关性。为了优化屏蔽机制,IFL采用方差损失来识别不变特征,实现多个环境中的鲁棒预测。就自分辨任务而言,本文借助屏蔽机制来增强样本以摒弃虚假特征,然后通过对比损失最大化真实样本和增强样本之间的互信息,从而帮助SSL模型忽略虚假特征。本研究在最前沿的SSL模型上实现IFL框架,通过对两个真实采样的数据集的大量实验验证了所提出的IFL框架在减少虚假相关性影响方面的有效性。
总的来说,本文的贡献可以总结如下:
1) 文章指出了SSL推荐算法中的虚假相关性,并试从多个环境中学习不变特征。
2) 文章提出了一种模型无关的IFL框架,该框架利用特征屏蔽机制和基于屏蔽机制的对比学习来减少SSL模型的虚假相关性。
3) 通过对两个公共数据集的实证研究,证实了文中所提出的IFL框架在屏蔽虚假特征和提升SSL模型的泛化能力方面的优越性。
全文下载:
Mitigating Spurious Correlations for Self-supervised Recommendation
Xin-Yu Lin, Yi-Yan Xu, Wen-Jie Wang, Yang Zhang, Fu-Li Feng
【本文作者】

MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
∨关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选"中国科技期刊卓越行动计划",已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等数据库收录。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢