
We're Afraid Language Models Aren't Modeling Ambiguity
解决问题:本文试图解决的问题是自然语言中的歧义问题,即如何让语言模型能够更好地理解和处理歧义语言,以提高其在对话界面和写作辅助等方面的应用效果。这是一个相对较新的问题。
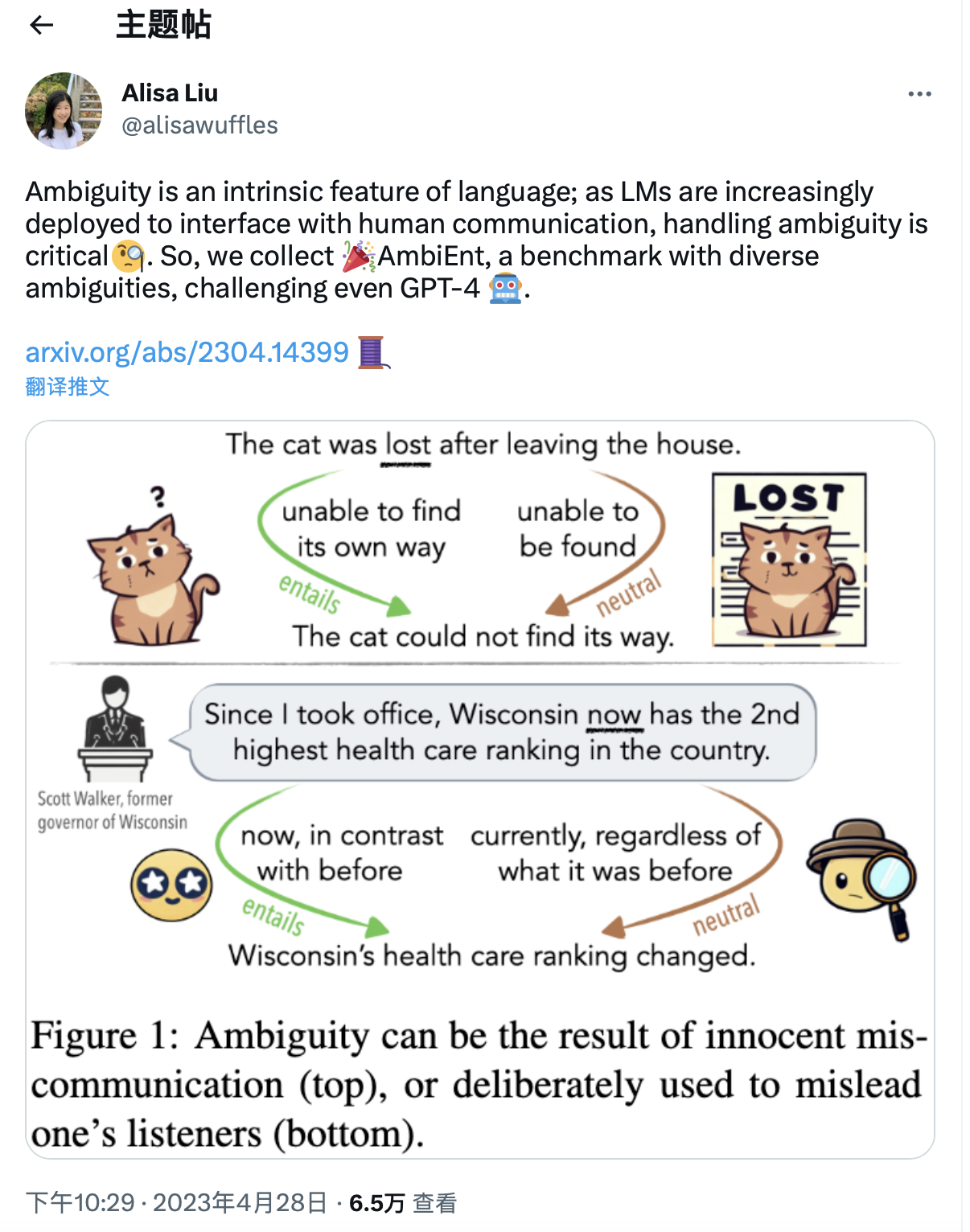
关键思路:本文的关键思路是通过设计一个基于歧义的测试套件AmbiEnt,对预训练语言模型进行歧义识别和消歧的评估,以及探索歧义敏感工具的应用。相比当前领域的研究,本文的思路在于将歧义问题作为重要的研究方向,并提出了一种新的测试方法和解决方案。
https://arxiv.org/pdf/2304.14399.pdf
其他亮点:本文的亮点在于设计了一个新的基准测试集AmbiEnt,并使用该测试集对多个预训练语言模型进行了评估,发现歧义问题仍然是一个极具挑战性的问题。此外,本文还展示了歧义敏感工具在政治言论识别方面的应用,具有一定的现实意义。目前,本文的代码和数据集已经开源,值得进一步研究。
关于作者:
Alisa Liu、Zhaofeng Wu、Julian Michael、Alane Suhr、Peter West、Alexander Koller、Swabha Swayamdipta、Noah A. Smith、Yejin Choi
University of Washington、Massachusetts Institute of Technology、Saarland University
论文摘要:我们担心语言模型不能模拟歧义 Alisa Liu、Zhaofeng Wu、Julian Michael、Alane Suhr、Peter West、Alexander Koller等人认为,歧义是自然语言的内在特征。管理歧义是人类语言理解的关键部分,使我们能够作为交流者预见误解,并作为听众修正我们的解释。
随着语言模型(LMs)越来越多地被用作对话接口和写作辅助工具,处理歧义语言对它们的成功至关重要。他们通过歧义对句子的蕴涵关系进行表征,并收集了AmbiEnt,这是一个包含1,645个具有不同种类歧义的语句的语言学注释基准。
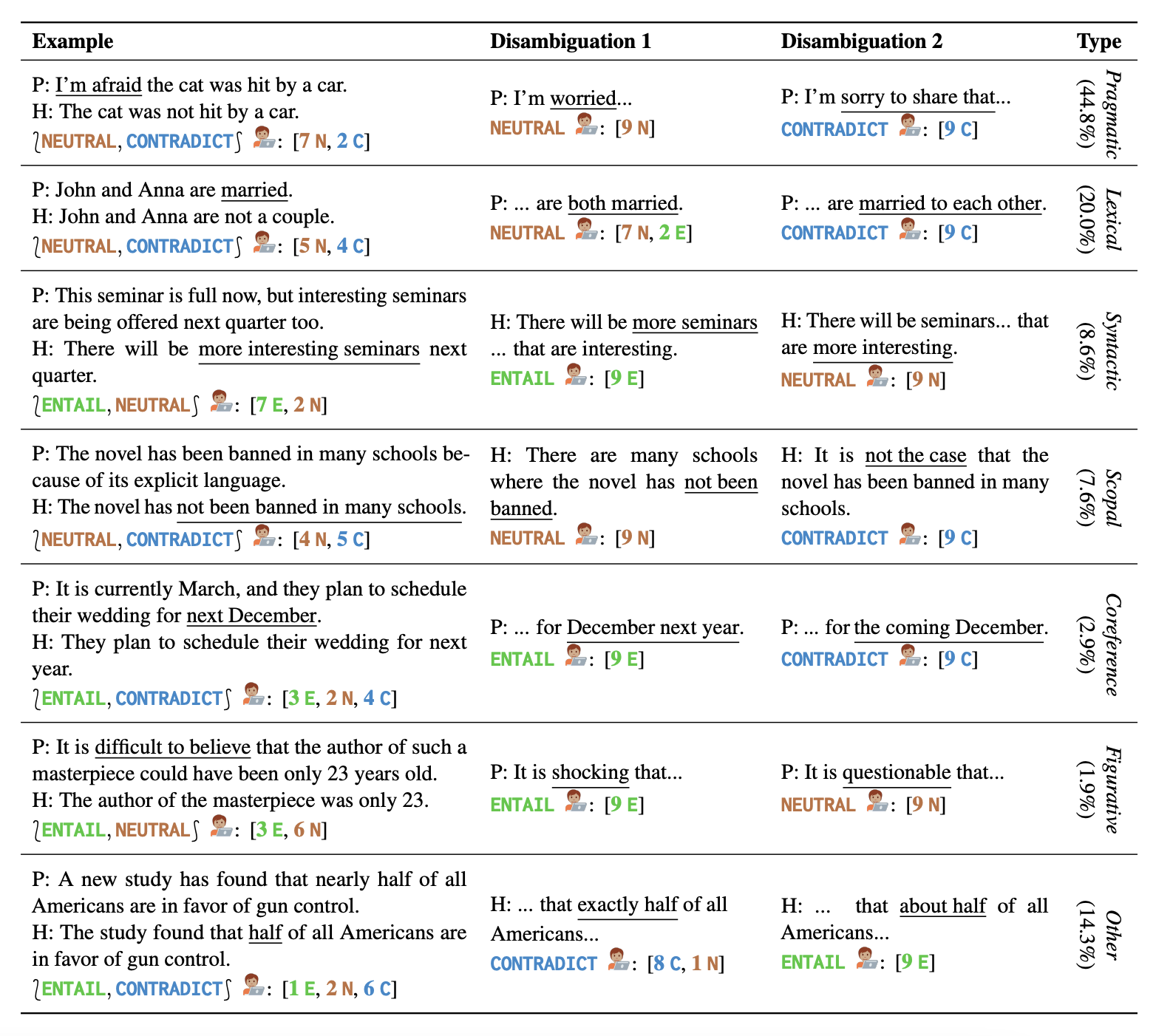
他们基于AmbiEnt设计了一系列测试,展示了预训练LMs首次评估识别歧义和分离可能含义的情况。他们发现这项任务仍然非常具有挑战性,即使对于最近的GPT-4也是如此,其生成的消歧结果在人类评估中只有32%被认为是正确的,而我们数据集中的消歧结果则有90%被认为是正确的。
最后,为了说明歧义敏感工具的价值,他们展示了一个多标签NLI模型能够标记野外政治声明中由于歧义而具有误导性的情况。他们鼓励该领域重新发现歧义对自然语言处理的重要性。
评估大模型上的表现
Q1. 能否直接生成与消歧有关的内容
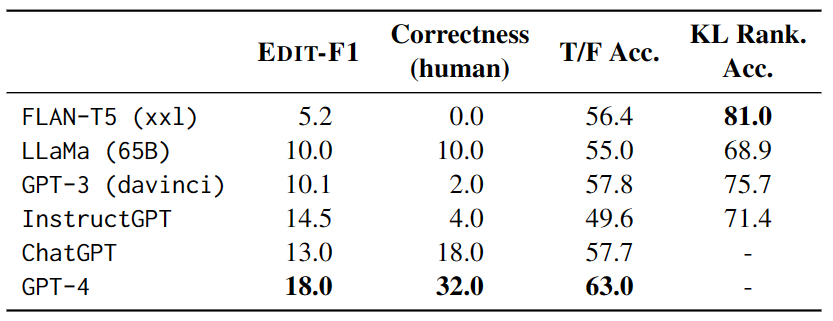
该部分重点在于测试语言模型在上下文中直接生成消歧和对应标签的学习能力。为此,作者构建了一个自然提示并使用自动评估和人工评估来验证模型的表现,如表 2 所示。

在测试中,每个示例都有 4 个其他测试示例作为上下文,并使用 EDIT-F1 指标和人工评估来计算得分和正确性。实验结果如表 3 显示,GPT-4 在测试中表现最佳,实现了18.0%的 EDIT-F1 得分和 32.0% 的人工评估正确性。此外,还观察到大模型在消歧时常常采用加入额外上下文的策略来直接确认或否定假设。不过需要注意的是,人工评估可能会高估模型准确报告歧义来源的能力。
Q2. 能否识别出合理解释的有效性
该部分主要研究了大模型在识别含有歧义的句子时的表现。通过创建一系列真假陈述模板,并对模型进行 zero-shot 测试,研究人员评估了大模型在选择正误之间的预测中的表现。实验结果表明,最佳模型是 GPT-4,然而,在考虑歧义性的情况下,GPT-4 在回答所有四个模板的歧义解释中的表现比随机猜测的准确率还低。此外,大模型在问题上存在一致性问题,对于同一个歧义句子的不同解释对,模型可能会出现内部矛盾的情况。
这些发现提示我们,需要进一步研究如何提高大模型对含有歧义的句子的理解能力,并更好地评估大模型的性能。
Q3. 通过不同解释模拟开放式连续生成
这一部分主要研究基于语言模型的歧义理解能力。通过给定上下文,对语言模型进行测试,比较模型对于不同可能解释下的文本延续的预测。为了衡量模型对于歧义的处理能力,研究人员通过在相应语境下比较模型在给定歧义和给定正确语境下所产生的概率和期望差异,用 KL 散度来衡量模型的“惊奇度”,并且引入随机替换名词的“干扰句”来进一步测试模型的能力。
实验结果表明,FLAN-T5 的正确率最高,但不同测试套件(LS 涉及同义词替换,PC 涉及拼写错误的修正,SSD 涉及语法结构修正)和不同模型的表现结果不一致,说明歧义仍然是模型的一个严重挑战。
多标签 NLI 模型实验
如表 4 所示,在已有带有标签变化的数据上微调 NLI 模型仍有较大提升空间,特别是多标签 NLI 任务中。
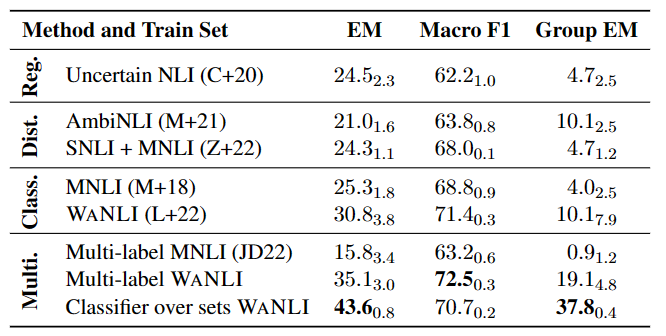
检测误导性的政治言论
这项实验研究了对政治言论的不同理解方式,证明了对不同理解方式敏感的模型可被有效利用。研究结果如表 5 所示,针对有歧义的句子,一些解释性的释义可以自然而然地消除歧义,因为这些释义只能保留歧义或者明确表达一个特定的意义。
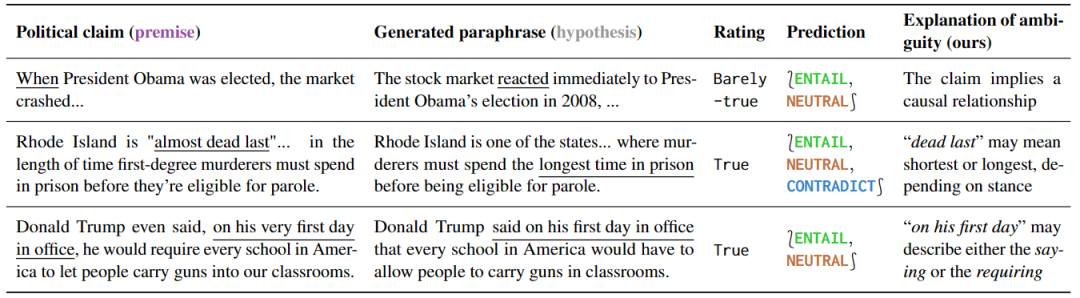
此外,针对这种预测的释义,可以揭示歧义的根源。通过进一步分析误报的结果,作者还发现了很多事实核查中没有提到的歧义,说明这些工具在预防误解方面具有很大的潜力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢