
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
旨在评估两个大型语言模型(LLM)在医疗中的实际效用和安全性。通过向GPT-3.5和GPT-4提交医生的问题,评估它们能否以安全和协调的方式提供信息。结果表明,虽然两个LLM的响应基本上没有明显的硬伤,但往往不能满足特定问题的信息需求。
Debadutta Dash, Rahul Thapa, Juan M. Banda, Akshay Swaminathan, Morgan Cheatham, Mehr Kashyap, Nikesh Kotecha, Jonathan H. Chen, Saurabh Gombar, Lance Downing, Rachel Pedreira, Ethan Goh, Angel Arnaout, Garret Kenn Morris, Honor Magon, Matthew P Lungren, Eric Horvitz, Nigam H. Shah
[Stanford]
要点:
-
动机:评估两个大型语言模型在医疗中的实际效用和安全性。 -
方法:通过向GPT-3.5和GPT-4提交医生的问题,评估它们能否以安全和协调的方式提供信息。医生评估LLM的响应是否可能对患者造成伤害以及是否与信息咨询服务的现有报告一致。 -
优势:评估了LLM在医疗中的实际效用和安全性,为进一步提高LLM的实用性提供了启示。
https://arxiv.org/abs/2304.13714 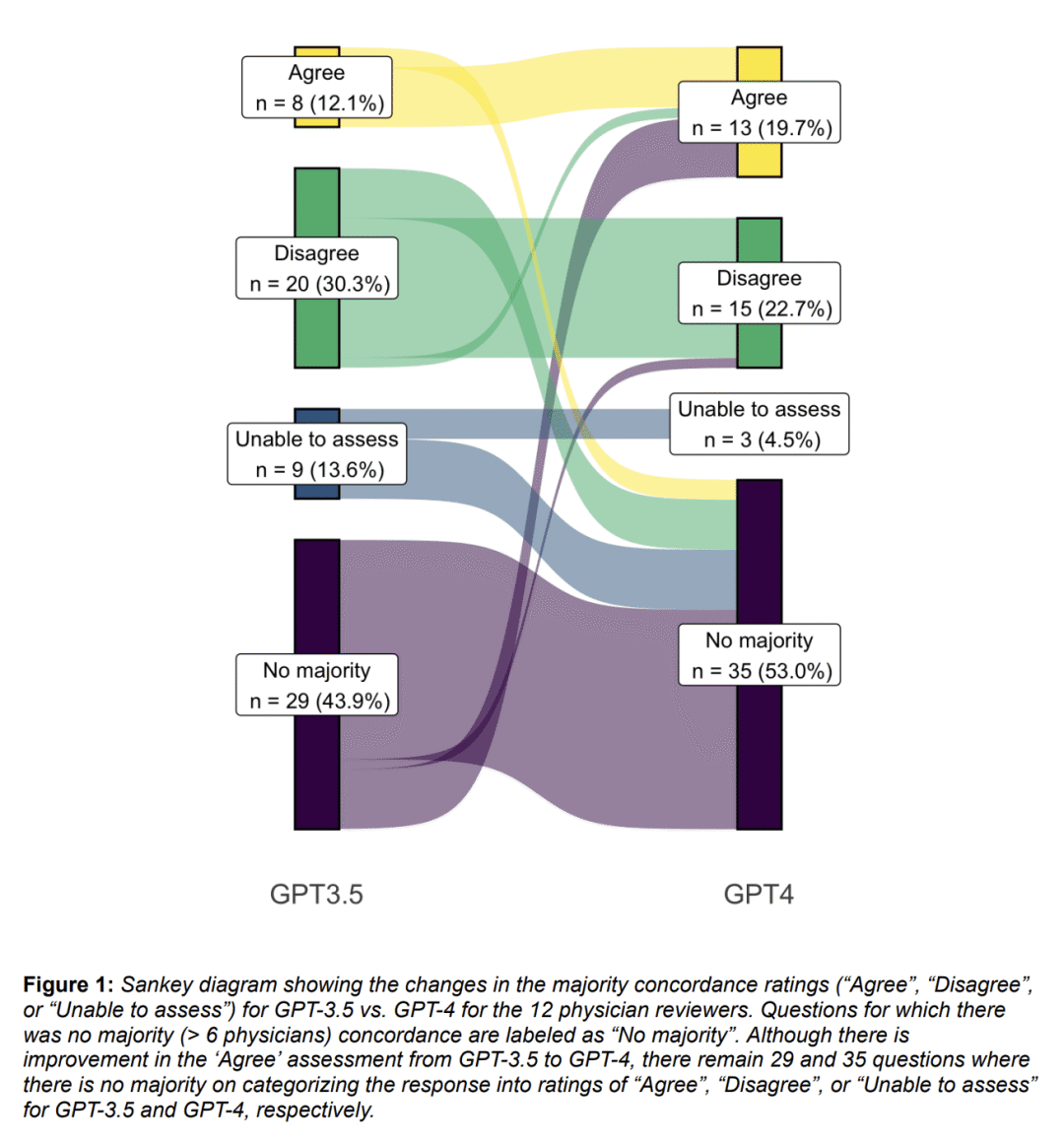
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢