
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
解决问题:这篇论文试图解决大型语言模型在指令微调方面所需的资源过多的问题,通过将大型语言模型的知识蒸馏到更小的模型中,以实现资源的节约。同时,论文还探索了如何构建一组广泛涵盖不同主题的指令集。
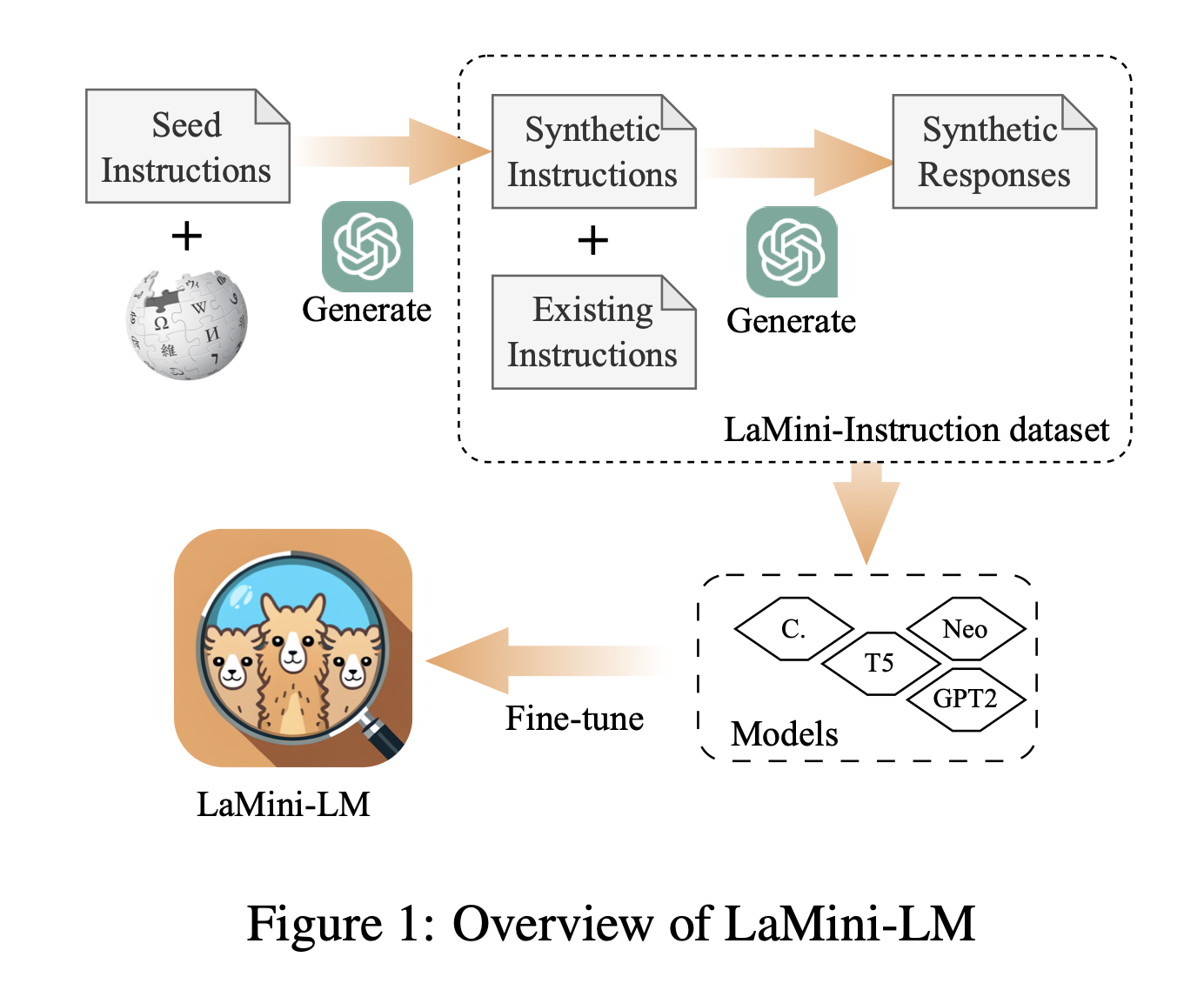
关键思路:论文的关键思路是通过将大型语言模型的知识蒸馏到更小的模型中,以实现资源的节约。此外,论文还构建了一组广泛涵盖不同主题的指令集,以确保指令的多样性。
其他亮点:论文的实验结果表明,所提出的LaMini-LM模型在15个不同的NLP基准测试中与竞争基线相当,同时模型大小几乎缩小了10倍。此外,论文还开源了数据集和代码,为后续研究提供了便利。
关于作者:
Minghao Wu、Abdul Waheed、Chiyu Zhang、Muhammad Abdul-Mageed、Alham Fikri Aji
Mohamed bin Zayed University of Artificial Intelligence、Monash University、The University of British Columbia
相关研究:近期其他相关的研究包括《Distilling the Knowledge of BERT for Text Generation》(作者:Luyang Huang、Yongbin Li、Jie Liu、Tong Xu,机构:中国科学技术大学)、《TinyBERT: Distilling BERT for Natural Language Understanding》(作者:Xiaoqi Jiao、Yichun Yin、Linfeng Song、Chenxi Liu、Yanbin Zhao,机构:清华大学)、《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》(作者:Victor Sanh、Lysandre Debut、Julien Chaumond、Thomas Wolf,机构:Hugging Face Inc.)等。
论文摘要:本文介绍了一种基于大规模指令的多样化压缩模型——LaMini-LM。大型语言模型(LLM)通过指令微调可以展现出更出色的生成能力,但这些模型需要大量资源。为了解决这个问题,本文探索了将指令微调的LLM的知识蒸馏到更小的模型中。
为此,研究人员精心设计了一个包含258万个指令的大型数据集,这些指令基于现有的和新生成的指令。除了数量庞大外,这些指令的设计涵盖了广泛的主题,以确保其多样性。通过对指令数据的彻底调查,研究人员证明了其多样性,并使用gpt-3.5-turbo为这些指令生成响应。然后,研究人员利用这些指令微调了一系列大小不同的模型,称为LaMini-LM,包括编码器-解码器和仅解码器两个系列。作者在15个不同的NLP基准测试上自动和手动评估了他们的模型。结果显示,LaMini-LM与竞争基线相当,同时大小几乎缩小了10倍。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢