
Stability AI releases StableVicuna, the AI World’s First Open Source RLHF LLM Chatbot
背景介绍
近几个月来,聊天机器人的开发和发布有了很大的进展。从去年春天Character.ai的聊天机器人到11月的ChatGPT和12月的Bard,为聊天调整语言模型所创造的用户体验一直是一个热门话题。开放存取和开源替代品的出现进一步激发了这种兴趣。

开源聊天机器人的当前环境
这些聊天模型的成功得益于两种训练范式:指令微调和通过人类反馈的强化学习(RLHF)。虽然在建立帮助训练这类模型的开源框架方面做出了巨大的努力,如trlX、trl、DeepSpeed Chat和ColossalAI,但目前还缺乏同时应用这两种范式的开放平台和开源模型。在大多数模型中,指令微调是在没有RLHF训练的情况下应用的,因为它涉及到的复杂性。
最近,Open Assistant、Anthropic和斯坦福大学已经开始向公众提供聊天RLHF数据集。这些数据集,再加上trlX提供的直接的RLHF训练,是我们今天在这里介绍的第一个大规模指令微调和RLHF模型的骨干: StableVicuna。
第一个大规模的开源RLHF LLM聊天机器人
我们很自豪地介绍StableVicuna,这是第一个通过人类反馈强化学习(RHLF)训练的大规模开源聊天机器人。StableVicuna是Vicuna v0 13b的进一步指令微调和RLHF训练版本,它是一个指令微调的LLaMA 13b模型。对于感兴趣的读者,你可以在这里找到更多关于Vicuna的信息。
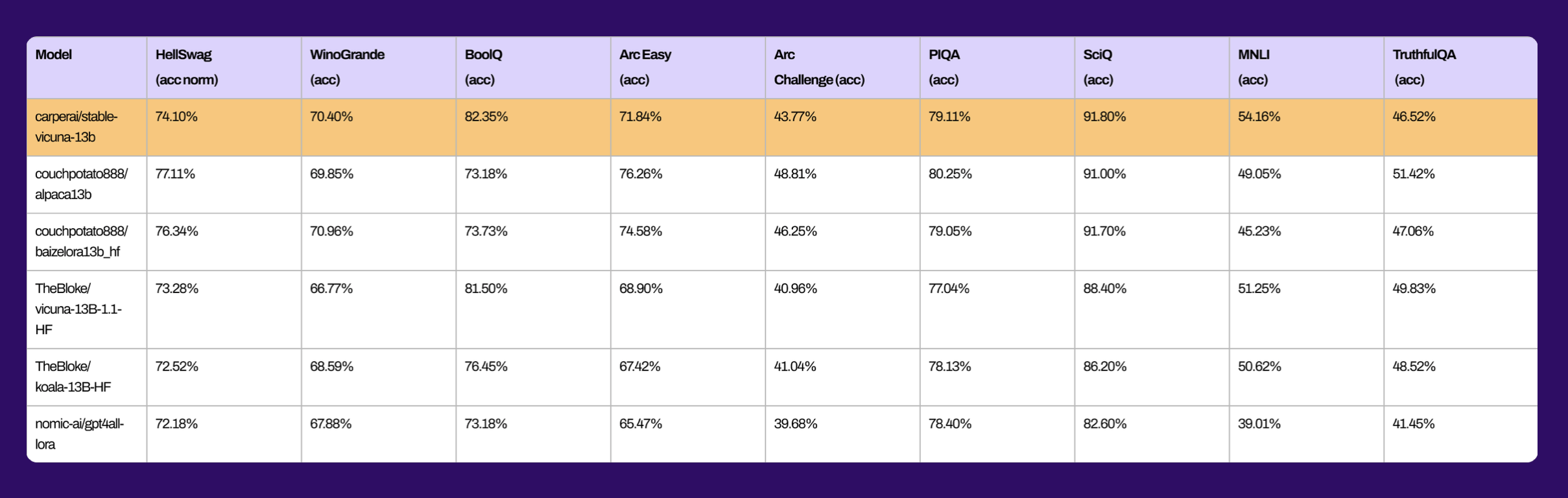
同样,这里有一些基准,显示了与其他类似规模的开源聊天机器人相比,StableVicuna的整体性能。
为了实现StableVicuna的强大性能,我们利用Vicuna作为基础模型,并遵循Steinnon等人和Ouyang等人概述的典型的三阶段RLHF管道。使用三个数据集,通过监督微调(SFT)进一步训练基础Vicuna模型:
OpenAssistant Conversations Dataset (OASST1),这是一个由人类生成的、经过人类注释的助理式对话语料库,包括161,443条信息,分布在66,497个对话树上,使用35种不同的语言;
GPT4All Prompt Generations,一个由GPT-3.5 Turbo生成的437,605条提示和回应的数据集;
还有Alpaca,这是一个由OpenAI的text-davinci-003引擎生成的52,000条指令和演示的数据集。
我们使用trlx来训练一个奖励模型,该模型首先从我们在以下RLHF偏好数据集上的进一步SFT模型初始化:
OpenAssistant对话数据集(OASST1)包含7213个偏好样本;
Anthropic HH-RLHF,一个关于人工智能助手的有用性和无害性的偏好数据集,包含160800个人类标签;
以及斯坦福人类偏好(SHP),这是一个包含348718个集体人类偏好的数据集,涉及从烹饪到哲学等18个不同主题领域的问题/指令的回应。最后,我们使用trlX进行近似策略优化(PPO)强化学习,对SFT模型进行RLHF训练,得出StableVicuna!
获得StableVicuna-13B
StableVicuna当然是在HuggingFace Hub上! 该模型可作为与原始的LLaMA模型相对应的权重delta下载。要获得StableVicuna-13B,你可以从这里下载权重delta。然而,请注意,你还需要获得原始的LLaMA模型,这需要你使用GitHub repo中提供的链接或在这里单独申请LLaMA权重。一旦你同时拥有了权重delta和LLaMA权重,你就可以使用GitHub repo中提供的脚本将它们结合起来,获得StableVicuna-13B。
除了我们的聊天机器人,我们很高兴能预览我们即将推出的聊天界面,它正处于开发的最后阶段。下面的屏幕截图提供了用户可以期待的一瞥。
我们对持续改进的承诺
这仅仅是StableVicuna的开始! 在未来几周内,我们将对这个聊天工具进行迭代,并在稳定基金会的服务器上部署一个 Discord 机器人。我们鼓励你尝试StableVicuna,并向我们提供有价值的反馈,以帮助我们改善用户体验。目前,你可以通过访问这个链接在HuggingFace空间上尝试这个模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢