
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
探讨了大型语言模型的因果推理能力,发现它们可以在多种因果推理任务中取得新的最高准确率,并能够使用自然语言输入系统地处理因果关系。同时,这些模型具有不可预测的失效模式,需要特殊技巧来解释其鲁棒性。本文认为大型语言模型可以作为人类领域知识的代理,以减少人在因果分析中的工作量,同时帮助实现协变与逻辑因果分析的统一。
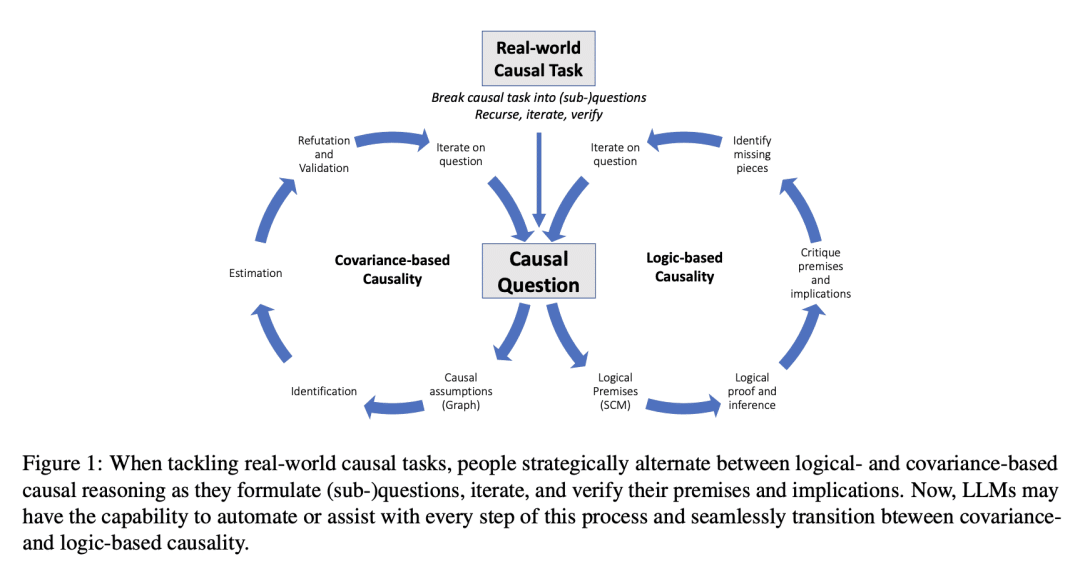
关键思路:文章使用基于GPT-3.5和4的算法,在多个因果基准测试中实现了新的最先进准确性。LLMs的因果推理能力依赖于与非LLM方法不同且互补的知识来源和方法,如使用收集的知识生成因果图或从自然语言中识别背景因果上下文。作者认为LLMs可以作为人类领域知识的代理,用于减少因果分析的人力成本,并与现有因果方法一起使用。
其他亮点:文章提出了解释LLMs鲁棒性的技术,并强调LLMs在捕捉常识和领域知识方面的潜力。实验使用了多个因果基准测试,并在其中实现了新的最先进准确性。文章没有提供开源代码。
关于作者:
Emre Kıcıman、Robert Ness、Amit Sharma、Chenhao Tan
[Microsoft Research & University of Chicago]
-
动机:大型语言模型的因果推理能力一直是一个争议性的问题,对其在医学、科学、法律和政策等领域的应用具有重要意义。本文旨在深入了解大型语言模型的因果能力,并考虑不同类型因果推理任务之间的区别以及构造和测量效度的威胁。 -
方法:采用多个因果基准测试数据集,发现基于大型语言模型的方法在多个因果推理任务中取得了新的最高准确率,并能使用自然语言输入系统地处理因果关系。同时提供了一些技巧来解释大型语言模型的失效模式。 -
优势:大型语言模型可以作为人类领域知识的代理,以减少人类在因果分析中的工作量,同时帮助实现协变与逻辑因果分析的统一。
https://arxiv.org/abs/2305.00050 
这篇文章探讨了大型语言模型(LLMs)的因果推理能力,并指出这对于LLMs在医学、科学、法律和政策等社会影响领域的应用有着重要的影响。作者进一步了解了LLMs及其因果推理的含义,考虑了不同类型因果推理任务之间的区别,以及构建和测量有效性的交织威胁。基于LLMs的方法在多个因果基准测试中建立了新的最先进的准确性。基于GPT-3.5和4的算法在成对因果发现任务(97%,增加13个点)、反事实推理任务(92%,增加20个点)和实际因果(86%准确率,确定情节中必要和充分的原因)方面优于现有算法。同时,LLMs表现出难以预测的失效模式,作者提供了一些解释其鲁棒性的技术。 重要的是,LLMs在执行这些因果任务时,依赖于与非LLM方法不同且互补的知识来源和方法。具体而言,LLMs带来了迄今为止被认为仅限于人类的能力,例如使用收集的知识生成因果图或从自然语言中识别背景因果上下文。我们预计LLMs将与现有的因果方法一起使用,作为人类领域知识的代理,并减少设置因果分析的人力成本,这是普及因果方法的最大障碍之一。我们还将现有的因果方法视为LLMs形式化、验证和沟通其推理的有希望的工具,特别是在高风险场景中。通过捕捉关于因果机制的常识和领域知识以及支持自然语言和形式方法之间的翻译,LLMs为推进因果关系的研究、实践和应用开辟了新的前沿。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢