
【约翰·霍普金斯大学 Alan Yuille 团队】CO2:无监督视觉表征学习的一致性对比 【论文标题】CO2: CONSISTENT CONTRAST FOR UNSUPERVISED VISUAL REPRESENTATION LEARNING 【作者团队】Chen Wei, Huiyu Wang, Wei Shen, Alan Yuille 【发表时间】2020/10/05 【论文链接】https://arxiv.org/pdf/2010.02217.pdf
【推荐理由】 本文出自计算机视觉大师 Alan Yuille 领导的团队,针对当下大火的对比学习中缺乏对查询图块与各个负例图块异构相似度度量的问题,提出了一种一致性正则化策略,取得了显著的性能提升。
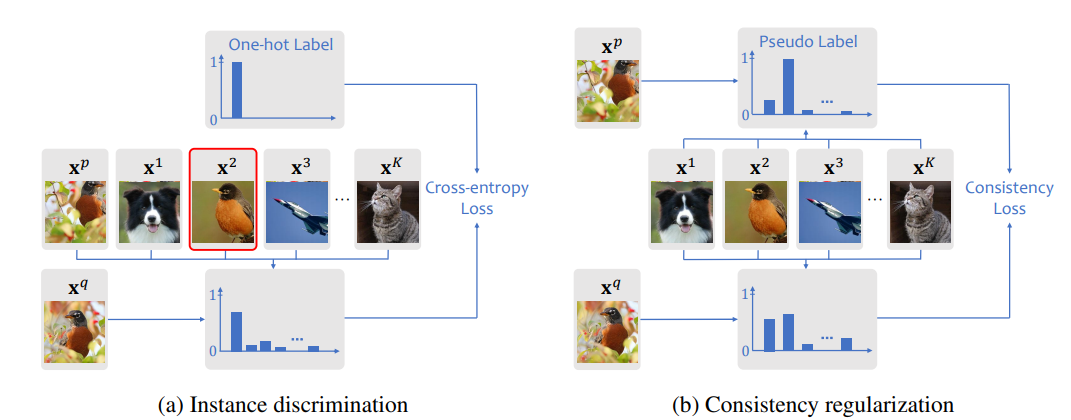
近年来,对比学习成为了无监督视觉表示学习领域最受瞩目的方法。在没有人工标记的情况下,对比学习通常会执行一个实例判别任务,即给定一个查询图像的裁剪图块,该任务将来自同一图像的其它裁剪图快标记为正例,将来自其它随机得到的采样图像的裁剪图块标记为负例。这种标签分配策略有一个很大的缺点:不能反映查询图块与来自其它图像的每个图块之间的异构相似度,而将它们都等同地视为负例(甚至有些图块可能与查询属于相同的语义类别)。为了解决这个问题,受到在无标签数据上的半监督学习领域中的一致性正则化启发,本文作者提出了一致性对比(CO2)策略,它在当前的对比学习框架中引入了一个一致性正则化项。考虑到查询图块与其它图像中的每一个图块的相似性没有被标记,一致性项将正例图块对应的相似性作为伪标签,并促进这两种相似性之间的一致性得以提升。实验结果表明,CO2 在 ImageNet 线性分类器上相较于 MoCo 提高了 2.9% 的 top-1 准确率,在带有 1% 和 10% 标记的半监督实验环境下提高了 3.8% 和 1.1% 的 top-5 准确率。它还在 PASCAL VOC 上的图像分类、目标检测和语义分割任务上取得了性能提升。这表明 CO2 能在这些下游任务中学习到更好的视觉表征。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢